目錄
- 一、停用詞介紹
- 二、停用詞應用場景
- 2.1 提取高頻詞
- 2.2 詞云圖
- 三、停用詞獲取方法
- 3.1 自定義停用詞
- 3.2 用wordcloud調取停用詞
- 3.3 用nltk調取停用詞
- 3.3.1 nltk中文停用詞
- 3.3.2 nltk英文停用詞
- 3.4 用sklearn調取停用詞
- 3.5 用gensim調取停用詞
- 3.6 用spacy調取停用詞
一、停用詞介紹
您好,我是@馬哥python說 ,一名10年程式猿,
在自然語言處理(NLP)研究中,停用詞stopwords是指在文本中頻繁出現但通常沒有太多有意義的詞語,這些詞語往往是一些常見的功能詞、虛詞甚至是一些標點符號,如介詞、代詞、連詞、助動詞等,比如中文里的"的"、"是"、"和"、"了"、","等等,英文里的"the"、"is"、"and"、"..."等等,
停用詞的作用是在文本分析程序中過濾掉這些常見詞語,從而減少處理的復雜度,提高演算法效率,并且在某些任務中可以改善結果的質量,避免分析結果受到這些詞的干擾,
二、停用詞應用場景
2.1 提取高頻詞
在使用jieba.analyse提取高頻詞時,可以事先把停用詞存入stopwords.txt檔案,然后用以下陳述句設定停用詞:jieba.analyse.set_stop_words('stopwords.txt') 這樣提取出的高頻詞就不會出現停用詞了,
2.2 詞云圖
在使用wordcloud畫詞云圖時,可以設定WordCloud物件的引數stopwords,把需要設定的停用詞放到這個引數里(通常情況下,需要手動多次增加停用詞,多輪迭代,才能繪制出滿意的詞云圖結果),


圖2摻雜了太多無意義的詞語,嚴重影響了詞頻分析結果,圖1效果就好多了,由此可見停用詞在文本分析里的重要性,
三、停用詞獲取方法
3.1 自定義停用詞
在科研領域,很多機構公開了一些停用詞庫,比如中文停用詞表、哈工大停用詞表、百度停用詞表、四川大學機器智能實驗室停用詞庫等,以方便廣大科研者使用,
下面,以哈工大停用詞表為例,完整代碼如下:
# 讀取停用詞(哈工大通用停用詞表)
with open('hit_stopwords.txt', 'r') as f:
stopwords_list = f.readlines()
stopwords_list = [i.strip() for i in stopwords_list]
print('停用詞數量:', len(stopwords_list))
print('停用詞串列:')
print(stopwords_list)
運行截圖:
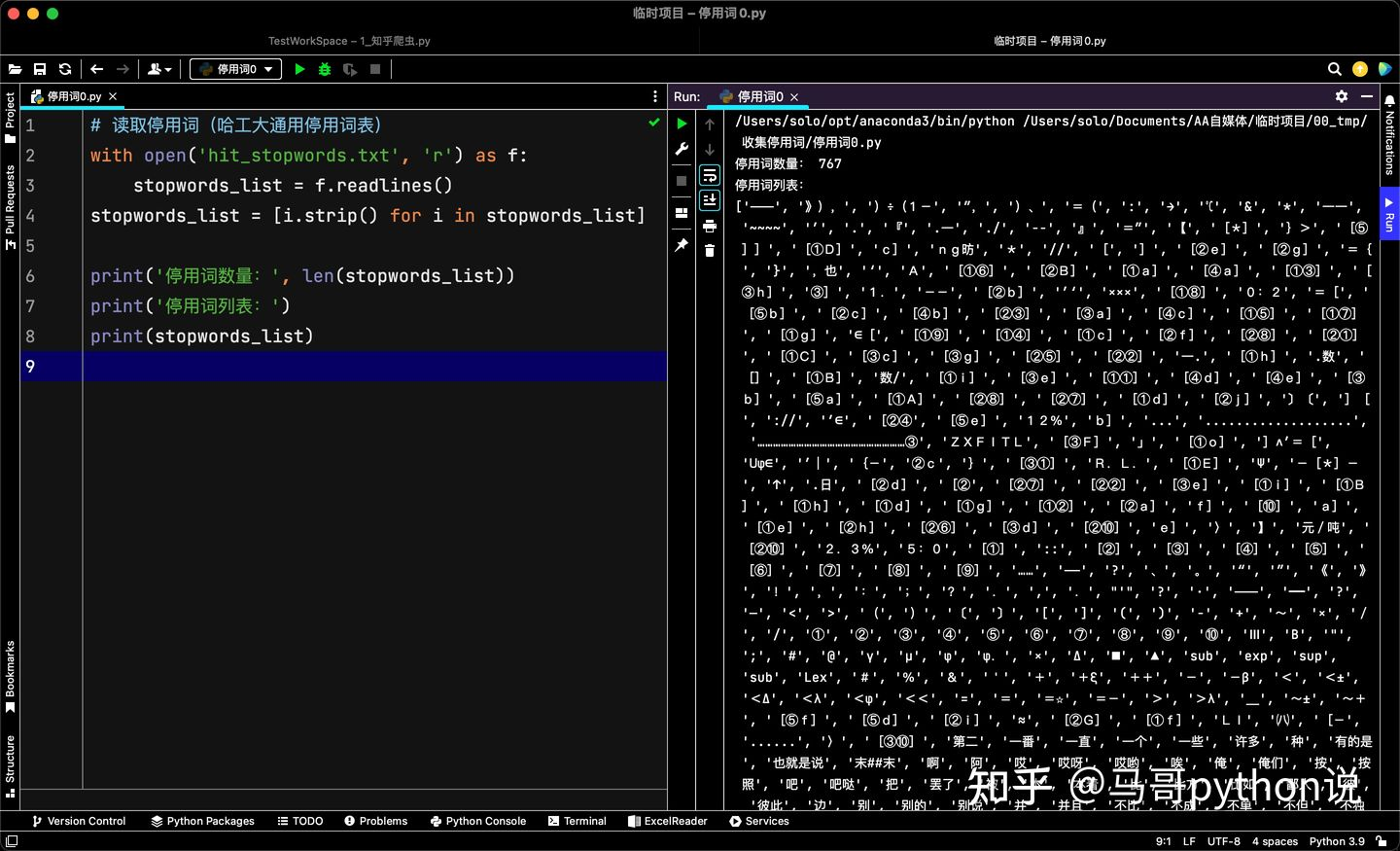
可以看到,中文停用詞還是挺全面的,共767個,
我整理了一份較詳盡的停用詞詞典,包含:中文停用詞表、哈工大停用詞表、百度停用詞表、四川大學機器智能實驗室停用詞庫,公眾號"老男孩的平凡之路"后臺回復"停用詞"直接拿!
3.2 用wordcloud調取停用詞
Python中的wordcloud是用來畫詞云圖的庫,它可以根據文本中單詞的頻率或重要性,將單詞以不同的大小、顏色等形式展示在影像中,從而形成一個視覺上吸引人的詞云圖,
同時,它也內置了英文停用詞庫,完整代碼如下:
from wordcloud import STOPWORDS
print('停用詞數量:', len(STOPWORDS))
print('停用詞串列:')
print(STOPWORDS)
運行截圖:
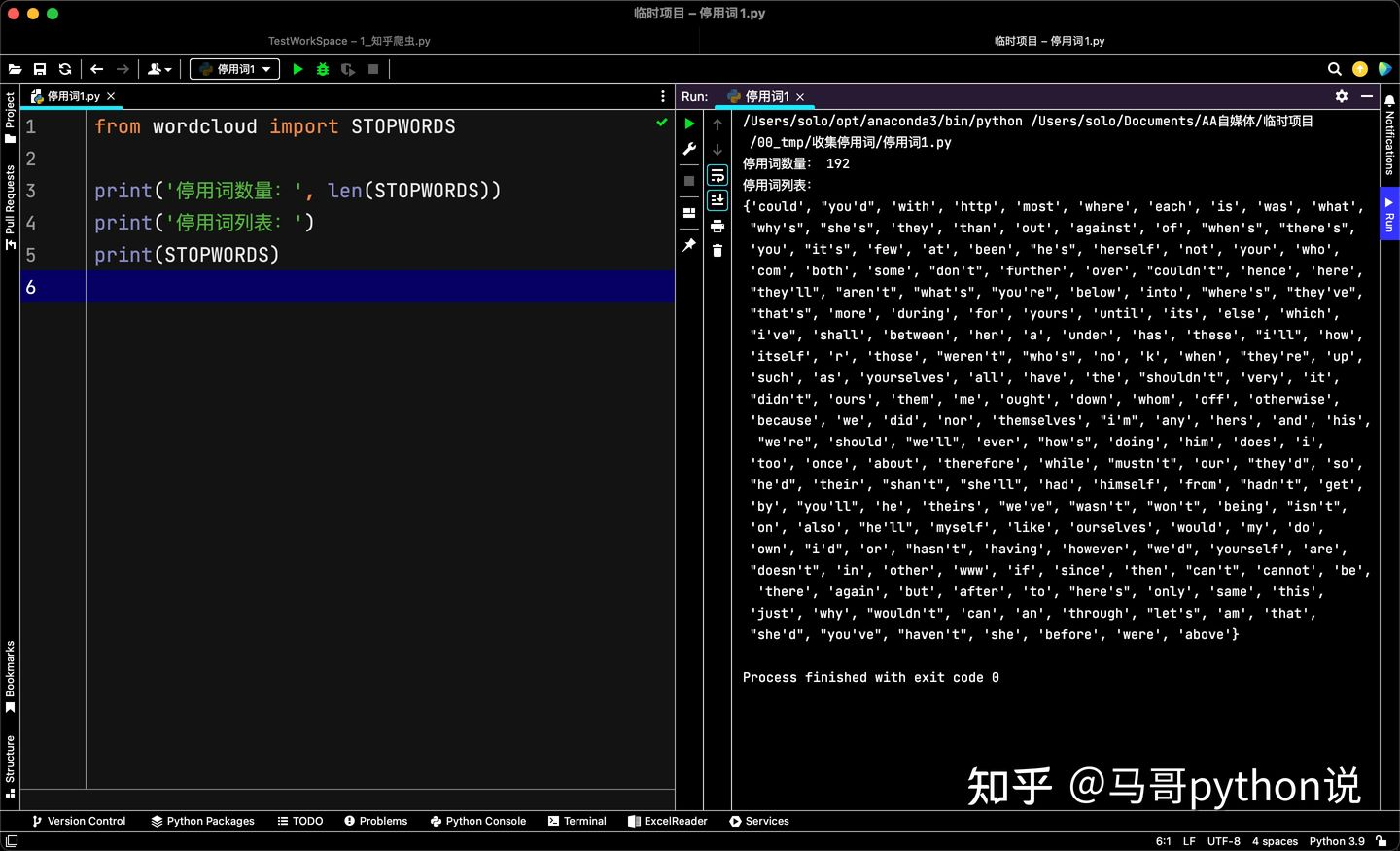
可以看到,wordcloud共包含了192個常用英文停用詞,
3.3 用nltk調取停用詞
nltk是一個流行的自然語言處理庫,提供了許多文本處理和語言分析的功能,包含停用詞加載、文本分詞、詞性標注、命名物體識別、詞干提取和詞形還原等常見功能,
其中,nltk內置了多種語言的停用詞,下面分別介紹中文、英文停用詞,
3.3.1 nltk中文停用詞
完整代碼:
import nltk
from nltk.corpus import stopwords
# 下載停用詞資源
nltk.download('stopwords')
# 獲取中文停用詞串列
stopwords_cn_list = stopwords.words('chinese')
# 列印中文停用詞串列
print('中文停用詞數量:', len(stopwords_cn_list))
print('中文停用詞:\n', stopwords_cn_list)
運行截圖:
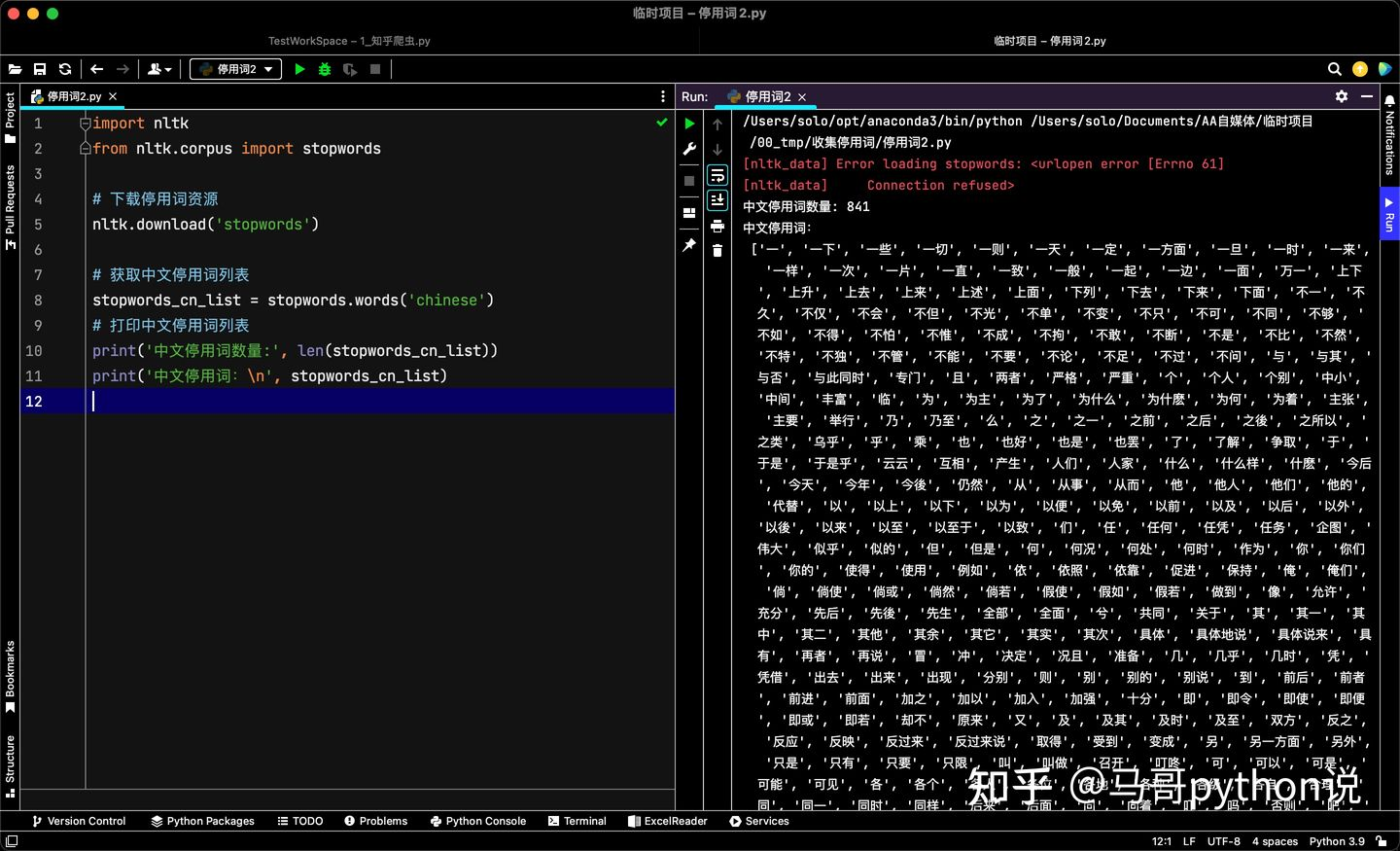
可以看到,nltk共包含841個中文停用詞,
3.3.2 nltk英文停用詞
完整代碼:
import nltk
from nltk.corpus import stopwords
# 下載停用詞資源
nltk.download('stopwords')
# 獲取英文停用詞串列
stopwords_en_list = stopwords.words('english')
# 列印英文停用詞串列
print('英文停用詞數量:', len(stopwords_en_list))
print('英文停用詞:\n', stopwords_en_list)
運行截圖:

可以看到,nltk共包含179個英文停用詞,
3.4 用sklearn調取停用詞
sklearn是一個用于機器學習的Python庫,它包含了各種經典和先進的機器學習演算法,如分類、回歸、聚類、降維、特征選擇、模型選擇等,
其中,sklearn.feature_extraction是用于特征提取的模塊,可以利用它調取停用詞庫,完整代碼如下:
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
# 列印停用詞串列
print('停用詞數量:', len(ENGLISH_STOP_WORDS))
print('停用詞串列:')
print(list(ENGLISH_STOP_WORDS))
運行截圖:
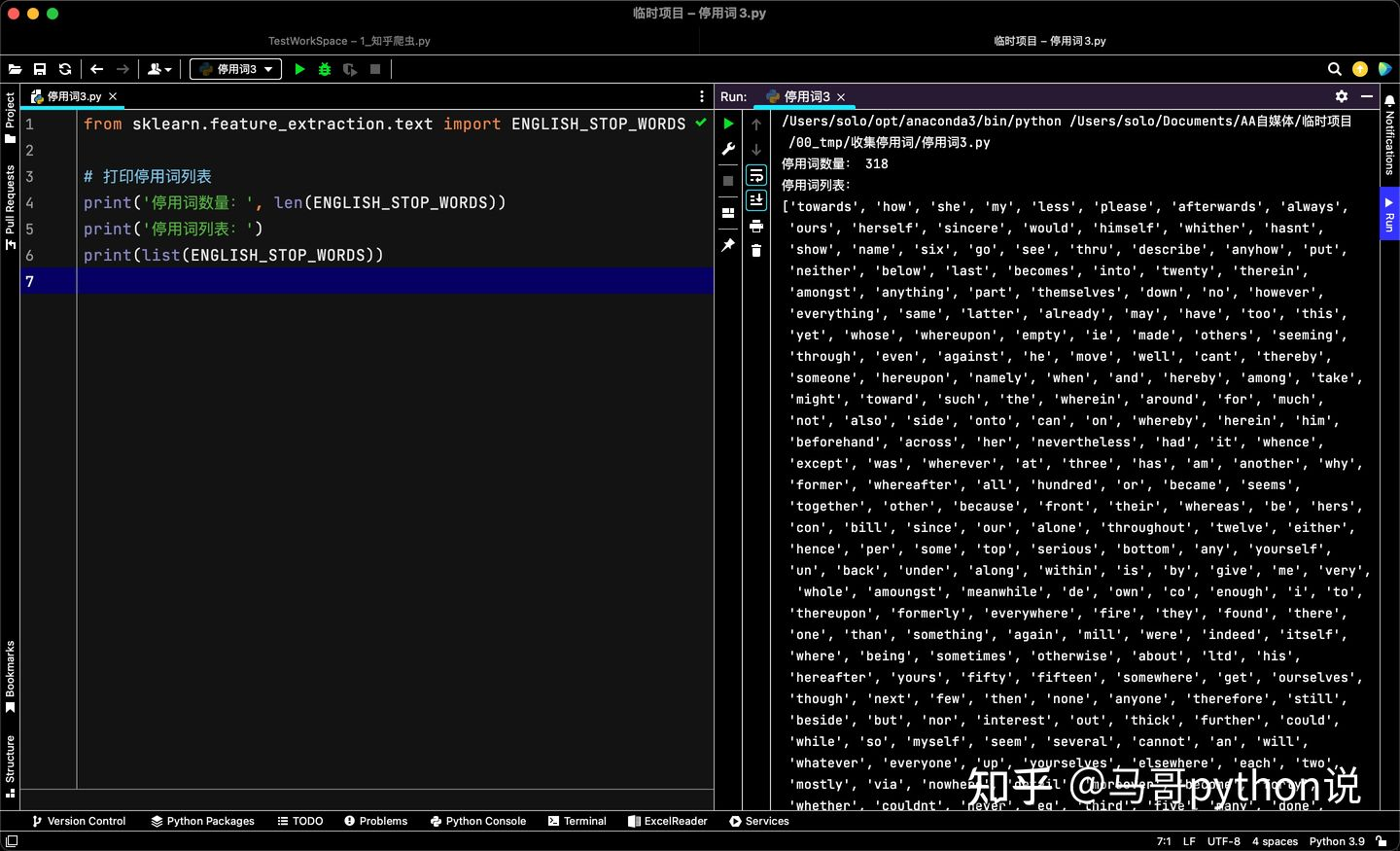
可以看到,sklearn共包含318個英文停用詞,
3.5 用gensim調取停用詞
gensim是一個用于主題建模和自然語言處理的Python庫,它提供了一組功能強大的工具和演算法,用于從大規模文本語料庫中提取語意主題和執行相關的文本處理任務,
其中,gensim.parsing.preprocessing是gensim庫中用于文本預處理的模塊,該模塊提供了一系列函式和工具,用于對文本進行標記化、停用詞去除、大小寫轉換、標點符號去除、詞干提取等常見的文本預處理任務,
用gensim調取停用詞,完整代碼如下:
from gensim.parsing.preprocessing import STOPWORDS
# 列印停用詞串列
print('停用詞數量:', len(STOPWORDS))
print('停用詞串列:')
print(list(STOPWORDS))
運行截圖:
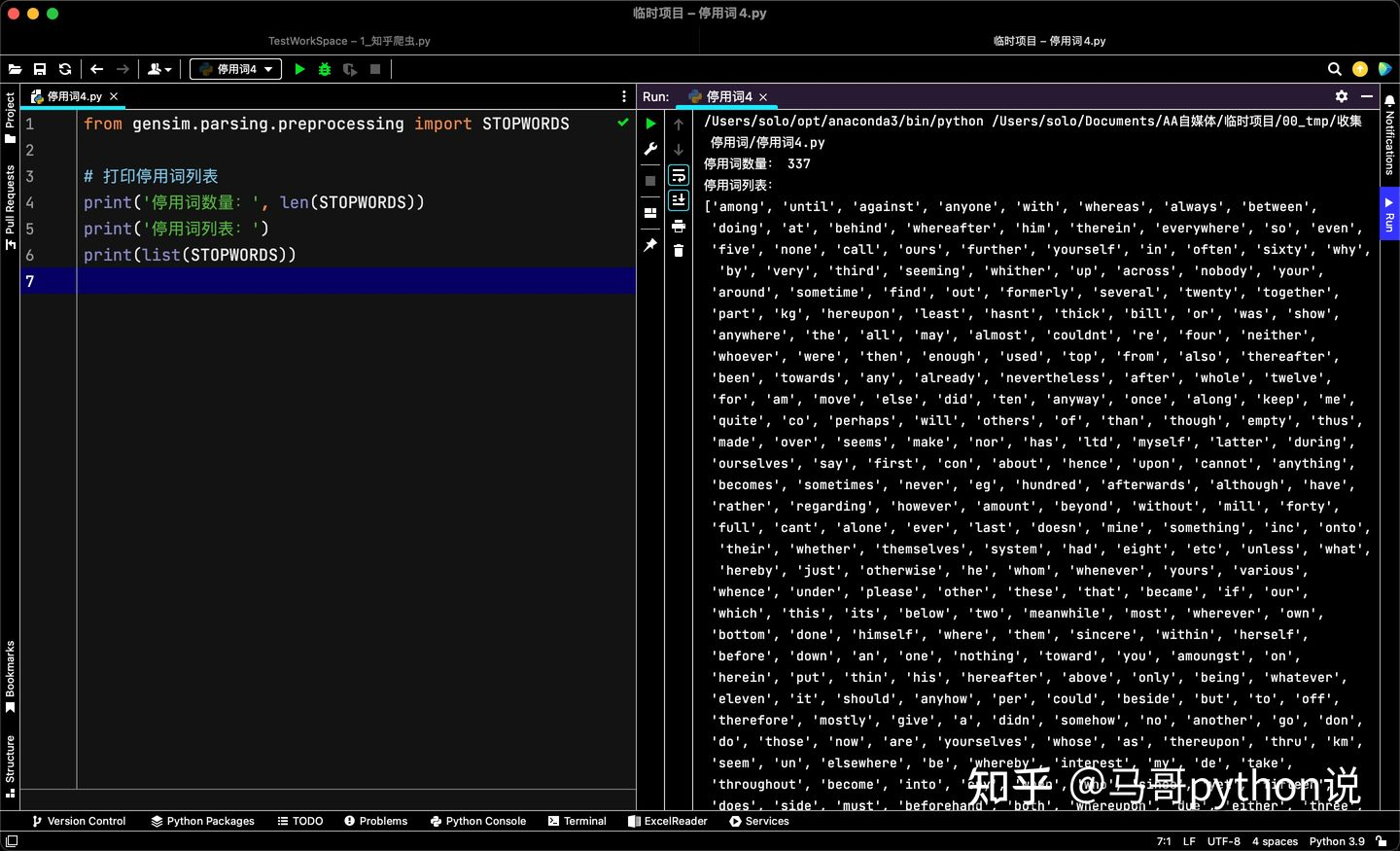
可以看到,gensim共包含337個英文停用詞,
3.6 用spacy調取停用詞
spacy是一個用于自然語言處理的Python庫,具有高性能、易用性和多語言支持的特點,它提供了一系列的功能和工具,用于詞法分析、命名物體識別、句法分析、依存關系分析等常見的自然語言處理任務,
用spacy調取停用詞,完整代碼如下:
import spacy
nlp = spacy.load("en_core_web_sm")
stopwords = nlp.Defaults.stop_words
# 列印停用詞串列
print('停用詞數量:', len(stopwords))
print('停用詞串列:')
print(list(stopwords))
運行截圖:

可以看到,spacy共包含326個英文停用詞,
以上,
您好,我是@馬哥python說,一名10年程式猿,開發過很多原創文本挖掘、情感分析案例,可移步:https://zhuanlan.zhihu.com/p/508625189
推薦閱讀:
【爬蟲+資料清洗+可視化】用Python分析“淄博燒烤“的評論資料
【爬蟲+資料清洗+可視化分析】輿情分析嗶哩嗶哩"陽了"的評論
【爬蟲+資料清洗+可視化分析】輿情分析嗶哩嗶哩"狂飆"的評論
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/556821.html
標籤:其他
上一篇:Netty-LengthFieldBasedFrameDecoder-解決拆包粘包問題的解碼器
下一篇:返回列表