本篇內容主要來源于自己學習的視頻,如有侵權,請聯系洗掉,謝謝,
1、etcd讀請求概覽
etcd是典型的讀多寫少存盤,在我們實際業務場景中,讀一般占據2/3以上的請求,一個讀 請求從client通過Round-robin(輪詢)負載均衡演算法,選擇一個etcd server節點,發出 gRPC請 求,經過etcd server的 KVServer模塊、線性讀模塊、MVCC的treelndex和 boltdb模塊緊 密協作,完成了一個讀請求,
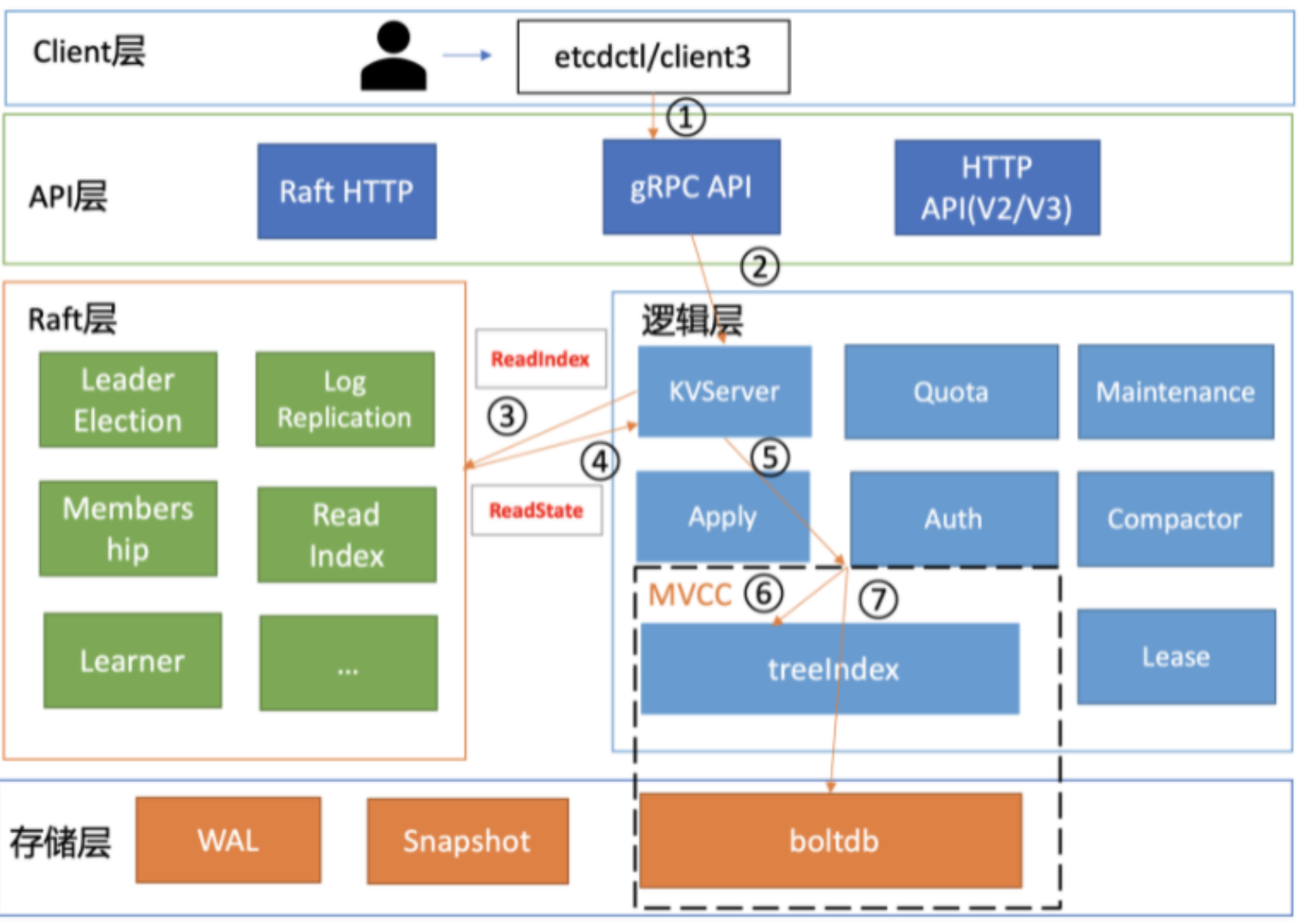
思考:通過etcdctl執行如下命令etcd是如何作業的?
etcdctl get hello ‐‐endpoints 192.168.65.210:2379,192.168.65.211:2379,19 2.168.65.212:2379
2、詳細步驟解讀
2.1 Client 層
主要是對應到步驟 1
1、首先,etcdctl 會對命令中的引數進行決議,
get是請求的方法,它是 KVServer 模塊的 提供的API;hello是 我們查詢的 key 名;endpoints是我們后端的 etcd 地址,通常,生產環境下中需要配置多個endpoints,這樣在 etcd 節點出現故障后,client 就可以自動重連到其它正常的節點,從而保證請求的正常執行,
2、在決議完請求中的引數后,etcdctl 會創建一個 clientv3 庫物件,使用 KVServer 模塊 的 API 來訪問 etcd server,
etcd clientv3 庫采用的負載均衡演算法為 Round-robin,針對每一個請求,Round-robin 演算法通過輪詢的方式依次從 endpoint 串列中選擇一個 endpoint 訪問 (長連接),使 etcd server 負載盡量均衡,
2.2 KVServer 與 攔截器
主要是對應到步驟 2
client 發送 Range RPC 請求到了 server 后就進入了 KVServer 模塊,
etcd 通過攔截器以非侵入式的方式實作了許多特性,例如:豐富的 metrics、日志、請求行為檢查、所有請求的執行耗時及錯誤碼、來源IP 等,攔截器提供了在執行一個請求前后 的 hook 能力,除了 debug 日志、metrics 統計、對 etcd Learner 節點請求介面和引數限制等能力,etcd 還基于它實作了以下特性:
-
要求執行一個操作前集群必須有 Leader;
-
請求延時超過指定閾值的,列印包含來源 IP 的慢查詢日志 (3.5 版本),
server 收到 client 的 Range RPC 請求后,根據 ServiceName 和 RPC Method 將請求轉 發到對應的 handler 實作,handler 首先會將上面描述的一系列攔截器串聯成一個攔截器再執行,在攔截器邏輯中,通過呼叫 KVServer 模塊的 Range 介面獲取資料,
2.3 串行讀與線性讀
流程三和四.
etcd 為了保證服務高可用,生產環境一般部署多個節點,多節點之間的資料由于延遲等關系可能會存在不一致的情況,
當 client 發起一個寫請求后分為以下幾個步驟:
1、Leader 收到寫請求,它會將此請求持久化到 WAL 日志,并廣播給各個節點;
只有 Leader 節點能處理寫請求,
2、若一半以上節點持久化成功,則該請求對應的日志條目被標識為已提交;
3、etcdserver 模塊異步從 Raft 模塊獲取已提交的日志條目,應用到狀態機 (boltdb 等),
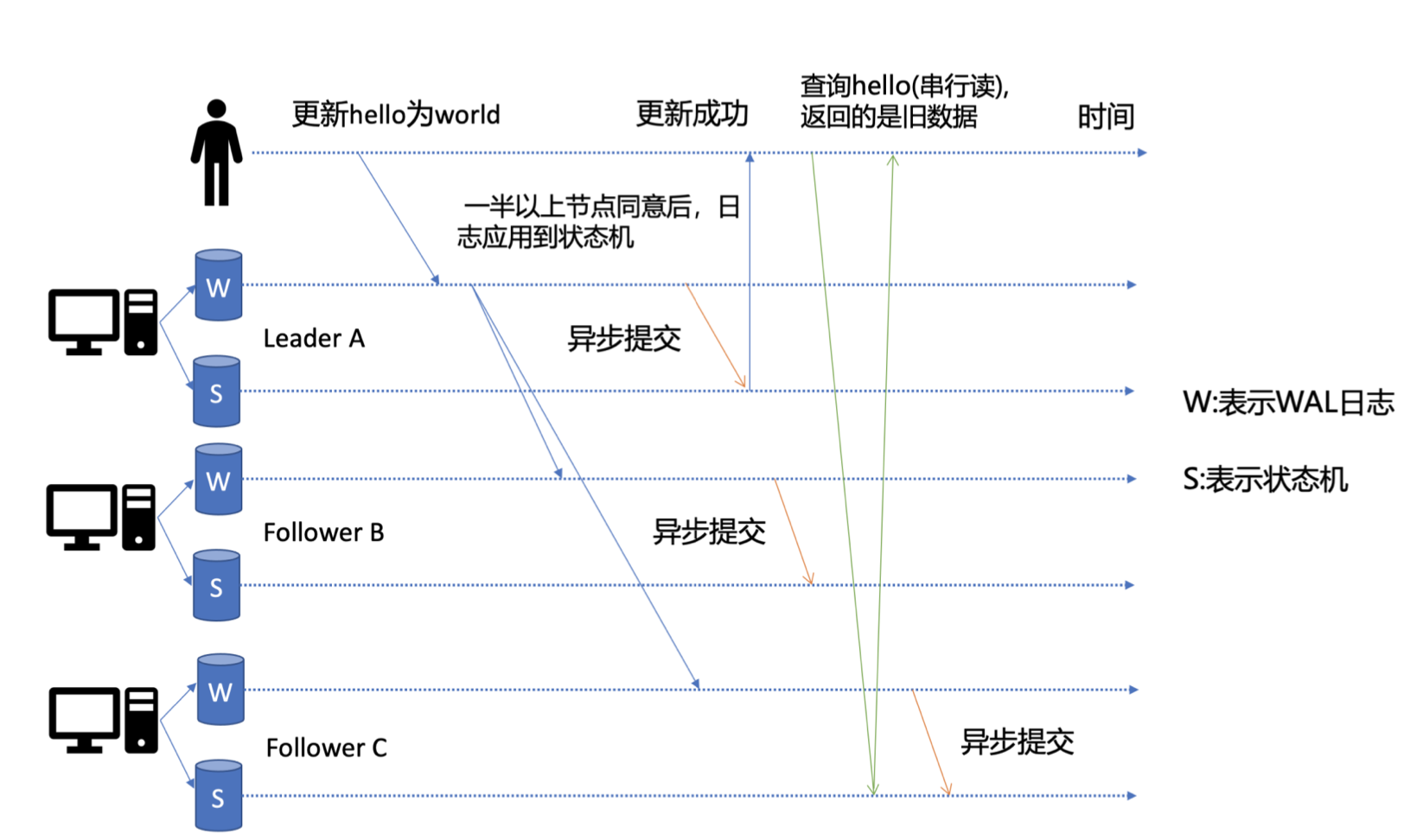
此時若client 發起一個讀取 hello 的請求,假設此請求直接從狀態機中讀取,如果連接到的是C節點,若C節點磁盤I/O出現波動,可能導致它應用已提交的日志條目很慢,則會出現更新 hello 為 world 的寫命令,在client讀 hello 的時候還未被提交到狀態機,因此就可能讀取到舊資料,如上圖查詢hello流程所示,
所以在多節點etcd集群中,各個節點的狀態機資料一致性存在差異,而我們不同業務場景 的讀請求對資料是否最新的容忍度是不一樣的,有的場景它可以容忍資料落后幾秒甚至幾分 鐘,有的場景要求必須讀到反映集群共識的最新資料,根據業務場景對資料一致性差異的接受程度,
**etcd 中有兩種讀模式: **
1、串行 (Serializable) 讀:
直接讀狀態機資料回傳、無需通過 Raft 協議與集群進行互動, 它具有低延時、高吞吐量的特點,適合對資料一致性要求不高的場景,
2、線性讀:
etcd
默認讀模式是線性讀,需要經過 Raft 協議模塊,反應的是集群共識,因 此在延時和吞吐量上相比串行讀略差一點,適用于對資料一致性要求高的場景,
對資料敏感度較低的場景:
- 直接讀狀態機資料回傳、無需通過 Raft 協議與集群進行互動的模式,在 etcd 里叫做串行 (Serializable) 讀,它具有低延時、高吞吐量的特點,適合對資料一致性要求不高的場景,
對資料敏感性高的場景:
- 在 etcd 里面,提供了一種線性讀模式來解決對資料一致性要求高的場景,
什么是線性讀呢?
你可以理解一旦一個值更新成功,隨后任何通過線性讀的 client 都能及時訪問到,雖然集群中有多個節點,但 client 通過線性讀就如訪問一個節點一樣,etcd 默認讀模式是線性讀,因為它需要經過 Raft 協議模塊,反應的是集群共識,因此在延時和吞吐量上相比串行讀略差一點,適用于對資料一致性要求高的場景,
2.4 ReadIndex
在 etcd 3.1 引入了 ReadIndex 機制,保證在串行讀的時候,也能讀到最新的資料,
接下來看看線性讀的執行流程

具體流程如下:
-
當收到一個線性讀請求時,它
首先會從Leader獲取集群最新的已提交的日志索引(committed index),如上圖中的流程二所示, -
Leader收到
ReadIndex請求時,為防止腦裂等例外場景,會向Follower節點發送心跳確認,一半以上節點確認Leader身份后才能將已提交的索引(committed index)回傳給節點C(上圖中的流程三), -
節點則會等待,直到
狀態機已應用索引 (applied index)大于等于Leader的已提交索引時(committed Index)(上圖中的流程四),然后去通知讀請求,資料已趕上 Leader,你可以去狀態機中訪問資料了(上圖中的流程五),
以上就是線性讀通過ReadIndex機制保證資料一致性原理,當然還有其它機制也能實作線性讀,如在早期etcd 3.0中讀請求通過走一遍Raft 協議保證一致性,這種Raft log read機制 依賴磁盤IO,性能相比 ReadIndex較差,
總體而言,KVServer模塊收到線性讀請求后,通過架構圖中流程三向Raft模塊發起 ReadIndex請求,Raft模塊將Leader最新的已提交日志索引封裝在流程四的ReadState結構體,通過channel層層回傳給線性讀模塊,線性讀模塊等待本節點狀態機追趕上Leader進度,追趕完成后,就通知KVServer模塊,進行架構圖中流程五,與狀態機中的 MVCC模塊進行進行互動了,
2.5 MVCC
流程五中的多版本并發控制(Multiversion concurrency control)模塊是為了解決etcd v2不支持保存key的歷史版本、不支持多key事務等問題而產生的,它核心由記憶體樹形索引模塊 (treelndex)和嵌入式的KV持久化存盤庫 boltdb 組成,boltdb是個基于B+ tree實作的 key-value鍵值庫,支持事務,提供Get/Put等簡易API給etcd操作,
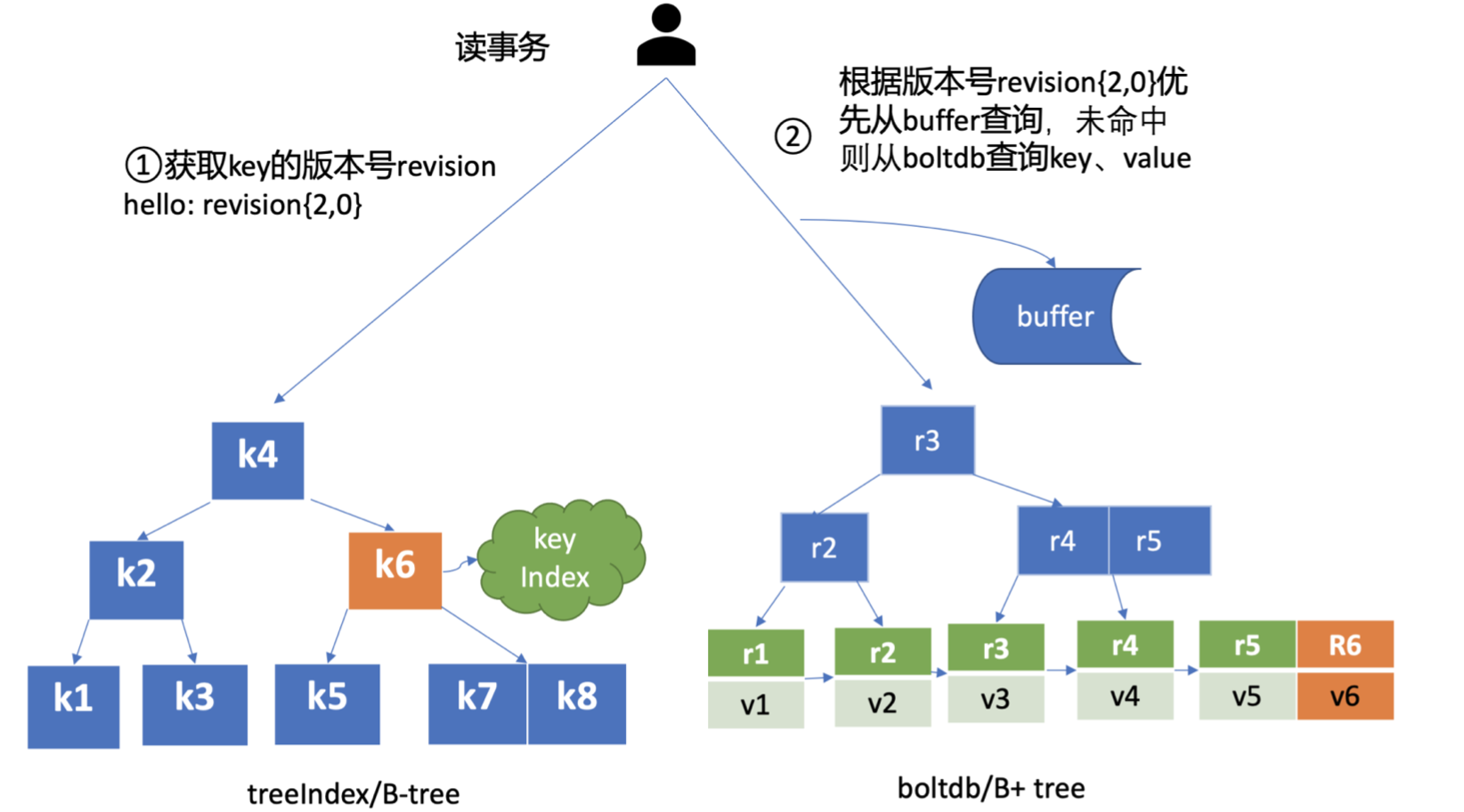
etcd MVCC 具體方案如下:
- 每次修改操作,生成一個
新的版本號 (revision),以版本號為 key, value 為用戶 key-value 等資訊組成的結構體存盤到 blotdb, - 讀取時·先從 treeIndex 中獲取 key 的版本號·,再以版本號作為 boltdb 的 key,從 boltdb 中獲取其 value 資訊,
2.6 treelndex
treelndex模塊是基于Google開源的記憶體版btree 庫實作的,treeIndex模塊只會保存用戶的key和相關版本號資訊,用戶 key 的value資料存盤在boltdb里面,相比ZooKeeper和 etcd v2全記憶體存盤,etcd v3對記憶體要求更低,
簡單介紹了etcd如何保存 key的歷史版本后,架構圖中流程六也就非常容易理解了,它需要從treelndex模塊中獲取 hello這個 key對應的版本號資訊,treeIndex模塊基于 B-tree快速查找此 key,回傳此 key對應的索引項keyIndex即可,索引項中包含版本號等資訊,
2.7 buffer
在獲取到版本號資訊后,就可從boltdb模塊中獲取用戶的key-value資料了,不過并不是所有請求都—定要從 boltdb 獲取資料,etcd出于資料一致性、性能等考慮,在訪問boltdb前,首先會從一個記憶體讀事務 buffer中,二分查找你要訪問key是否在 buffer里面,若命中則直接回傳,
2.8 boltdb
若buffer未命中,此時就真正需要向boltdb模塊查詢資料了,進入了流程七, 我們知道MySQL通過 table 實作不同資料邏輯隔離,那么在boltdb是如何隔離集群元資料 與用戶資料的呢?答案是bucket,
boltdb 里每個 bucket 類似對應 MySQL 一個表,用戶的 key 資料存放的 bucket 名字的是 key,etcd MVCC 元資料存放的 bucket 是 meta,
我猜測這里的意思是每個key都當做一個 bucket,然后bucket的名字是 key,這里是猜測的,待驗證,若有知道的朋友,請不吝賜教,十分感謝,
因boltdb使用B+ tree來組織用戶的key-value資料,獲取 bucket key物件后,通過boltdb 的游標Cursor可快速在B+ tree找到 key hello對應的value資料,回傳給client, 到這里,一個讀請求之路執行完成,
文章來源:
etcd讀請求執行流程-視頻教程
etcd教程(七)---讀請求執行流程分析
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/556670.html
標籤:其他
上一篇:es筆記三之term,match,match_phrase 等查詢方法介紹
下一篇:返回列表