隨著業務的發展,實時場景在各個?業中變得越來越重要,?論是?融、電商還是物流,實時資料處理都成為了其中的關鍵環節,Flink 憑借其強?的流處理特性、窗?操作以及對各種資料源的?持,成為實時場景下的?選開發?具,
FlinkSQL 通過 SQL 語??向資料開發提供了更友好的互動?式,但是其開發?式和離線開發 SparkSQL 仍然存在較?的差異,袋鼠云實時開發平臺StreamWorks,?直致?于降低 FlinkSQL 的開發門檻,讓更多的資料開發掌握實時開發能?,普及實時計算的應?,
本文將為大家簡單介紹在袋鼠云實時開發平臺開發 FlinkSQL 任務的四種?式,
腳本模式
該模式是最基礎的開發?式,資料開發人員在平臺 IDE 中通過 FlinkSQL 代碼,完成 Flink 表定義和業務邏輯加?,代碼如下:
-- 定義資料源表
CREATE TABLE server_logs (
client_ip STRING,
client_identity STRING,
userid STRING,
user_agent STRING,
log_time TIMESTAMP(3),
request_line STRING,
status_code STRING,
size INT
) WITH (
'connector ' = 'faker ',
'fields .client_ip .expression ' = '#{Internet .publicIpV4Address} ',
'fields .client_identity .expression ' = '- ',
'fields .userid .expression ' = '- ',
'fields .user_agent .expression ' = '#{Internet .userAgentAny} ',
'fields .log_time .expression ' = '#{date .past ' '15 ' ', ' '5 ' ', ' 'SECONDS ' '} ',
'fields .request_line .expression ' = '#{regexify ' '(GET |POST |PUT |PATCH){1} ' '} #{regexify ' '(/search\ .html|/login\ .html|/prod\ .html|c
'fields .status_code .expression ' = '#{regexify ' '(200 |201 |204 |400 |401 |403 |301){1} ' '} ',
'fields .size .expression ' = '#{number .numberBetween ' '100 ' ', ' '10000000 ' '} '
);
-- 定義結果表, 實際應用中會選擇 Kafka、JDBC 等作為結果表
CREATE TABLE client_errors (
log_time TIMESTAMP(3),
request_line STRING,
status_code STRING,
size INT
) WITH (
'connector ' = 'stream-x '
);
-- 寫入資料到結果表
INSERT INTO client_errors
SELECT
log_time,
request_line,
status_code,
size
FROM server_logs
WHERE status_code SIMILAR TO '4[0-9][0-9] ';
腳本模式的優缺點
優點:靈活性?,
缺點:Flink表定義邏輯復雜,如果不熟悉資料源插件,很難記住需要維護哪些引數;如果該任務涉及多張表,代碼塊中存在?段表定義代碼,不?便排查業務邏輯,
向導模式
基于腳本模式存在的缺點,袋鼠云實時開發平臺將 Flink 表定義邏輯抽象成了可視化配置的功能,引導資料開發?員通過??配置化的?式完成 Flink 表定義,讓資料開發更專注在業務邏輯的加?,

向導模式是在開發??的配置項中根據??引導,完成 Flink 表的源表、維表、結果表的映射,然后在 IDE 中直接引?,讀寫對應的 Flink 表,完成邏輯開發,
· 平臺默認提供各類資料源的源表、維表、結果表常?配置項;
· 對于各種?級引數,平臺也提供了維護?定義引數的 key/value ?式來滿?靈活性要求,
Catalog 模式
在向導模式中,我們可以借助配置化的?式快速完成表映射,但同時也存在?個問題,這些映射表只能在當前任務中被引?,?法在不同的任務中復?,
但是在真實的實時數倉建設程序中,我們常會遇到下?這種場景:某?個 dws 層級的 kafka topic,會在多個 ads 任務中被作為源表使?,?在每個 ads 任務開發程序中,都需要為同?個 dws topic 做?次相同的 Flink 映射,
為了解決這種重復映射的開發?作,我們可以借助 Flink Catalog 功能,將映射表的元資料資訊進?持久化存盤,這樣就可以在不同的任務中重復引?,具體使??法如下(以平臺的 DT Catalog 為例):
Catalog ?錄維護
· 先在 DT Catalog 下創建?個名為 stream_warehouse 的 catalog
· 然后在該 catalog 下根據數倉層級或者業務域創建不同的 database
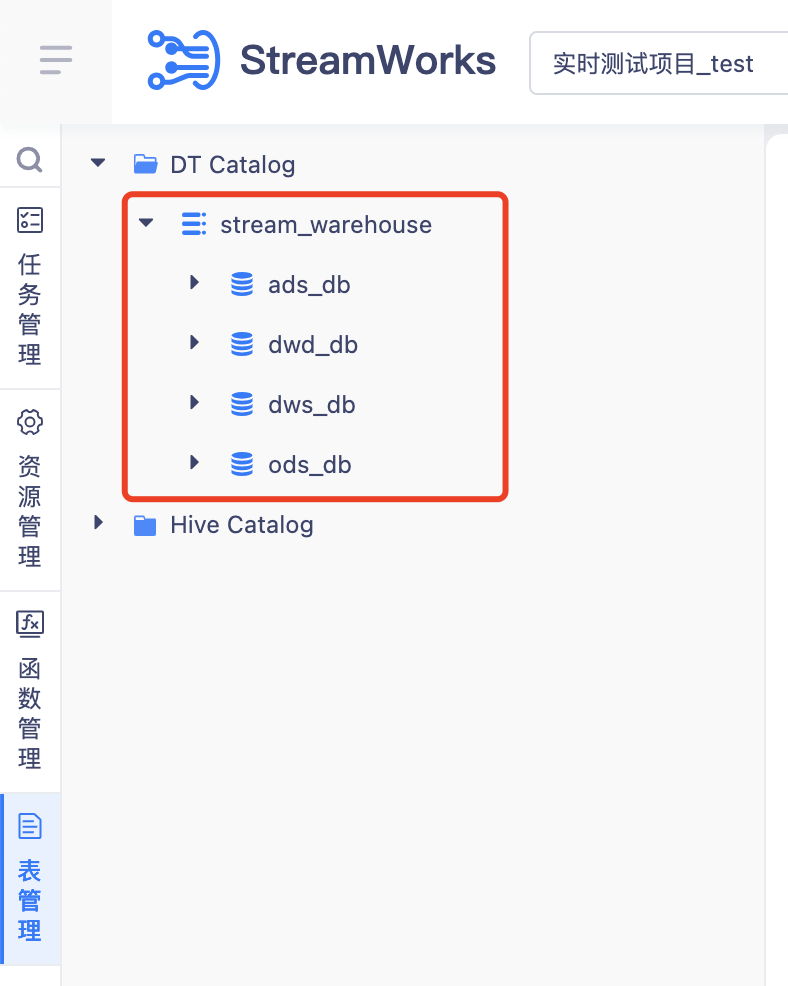
Flink 映射表創建
· ?式?:在?錄中 hover database,根據引導通過配置化?式完成 Flink 表映射

· ?式?:在 IDE 中,通過 Create DDL 完成創建,注意要指定對應的 catalog.database 路徑
CREATE TABLE stream_warehouse .dws .orders (
order_uid BIGINT,
product_id BIGINT,
price DECIMAL(32, 2),
order_time TIMESTAMP(3)
) WITH (
'connector ' = 'datagen '
);
FlinkSQL 任務開發
完成上面兩個步驟,?張元資料持久化存盤的 Flink 映射表就創建好了,我們在開發任務的時候,就可以直接通過 catalog.database.table 的?式,引?我們需要的表,
INSERT INTO stream_warehouse .ads_db .client_errors
SELECT
log_time,
request_line,
status_code,
size
FROM stream_warehouse .dws_db .server_logs
Demo 模式
學會了上?三種開發?式后,如果你還對 FlinkSQL 的開發邏輯?較陌?,那么建議你可以通過袋鼠云實時開發平臺的代碼模版中?去完成?個完整的任務開發,
在模版中?,我們提供了??余種常?的業務場景及其對應的 FlinkSQL 代碼邏輯,如各類窗?的寫法、各類 Join 的寫法等等,你可以根據真實的業務場景去套?模版,快速地完成任務開發,


總結
每種開發模式沒有絕對的好壞之分,需要根據不同企業的實時計算場景和階段,采?不同的開發模式,才能真正達到降本增效的目的,
· 當企業剛接觸實時計算,資料開發?員對 FlinkSQL 熟悉度較低時,DEMO 模式是最好的選擇;
· 當企業已經上?實時計算,但是任務量還不?時,腳本模式或者向導模式是不錯的選擇;
· 當企業實時計算達到?定規模,需要進?類似離線數倉的管理?式時,Catalog 模式是最優的選擇,
《數堆疊產品白皮書》:https://www.dtstack.com/resources/1004?src=https://www.cnblogs.com/DTinsight/archive/2023/07/05/szsm
《資料治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=https://www.cnblogs.com/DTinsight/archive/2023/07/05/szsm
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/archive/2023/07/05/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/556666.html
標籤:其他
上一篇:Mysql進階篇(一)之存盤引擎
下一篇:返回列表