注意:本文使用的Hadoop版本為3.2.1版本
目錄
一、HDFS多目錄存盤
1.1 生產環境服務器磁盤情況
1.2 在hdfs-site.xml檔案中配置多個目錄,需要注意新掛載磁盤的訪問權限問題,
二、集群資料均衡
2.1 節點間資料均衡
1)開啟資料均衡命令
2)停止資料均衡命令
2.2 磁盤間資料均衡
1)生成均衡計劃
2)執行均衡計劃
3)查看當前均衡任務的執行情況
4)取消均衡任務
三、配置LZO壓縮
1)下載hadoop-lzo開源組件并編譯
3)同步hadoop-lzo-0.4.20.jar到集群中的其他節點
4)core-site.xml增加配置支持LZO壓縮
5)同步core-site.xml至集群中的其他節點
四、LZO創建索引
1)創建LZO檔案的索引,LZO壓縮檔案的可切片特性依賴于其索引,所以需要手動為LZO壓縮檔案創建索引,若無索引,則LZO檔案的切片只有一個,
2)測驗
3)注意:如果以上任務,在運行程序中報如下例外
五、Hadoop集群基準測驗
1) 測驗HDFS寫性能
2)測驗HDFS讀性能
3)洗掉測驗生成資料
4)使用Sort程式評測MapReduce
六、Hadoop引數調優
6.1 HDFS引數調優hdfs-site.xml
6.2 YARN引數調優yarn-site.xml
一、HDFS多目錄存盤
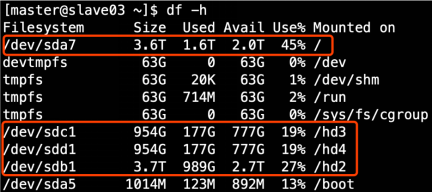
1.1 生產環境服務器磁盤情況
1.2 在hdfs-site.xml檔案中配置多個目錄,需要注意新掛載磁盤的訪問權限問題,
HDFS中DataNode節點保存資料的路徑由dfs.datanode.data.dir引數決定,其默認值為file://${hadoop.tmp.dir}/dfs/data,若服務器中有多個磁盤,必須對改引數進行修改,如服務器磁盤如上圖所示,則該引數應修改為如下的值,
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>多目錄之間用逗號作為分隔符,另外,值得注意的是,每臺服務器掛載的磁盤不一定一樣,所以沒臺節點的多目錄配置一般是不同的,需要手動的到每臺服務器下去配置該項,
二、集群資料均衡
2.1 節點間資料均衡
1)開啟資料均衡命令
start-balancer.sh -threshold 10對于引數10,代表的是急群眾各個節點的磁盤空間利用率相差不超過10%,可根據實際情況進行調整,
2)停止資料均衡命令
stop-balancer.sh2.2 磁盤間資料均衡
1)生成均衡計劃
hdfs diskbalancer -plan hadoop1012)執行均衡計劃
hdfs diskbalancer -execute hadoop101.plan.json3)查看當前均衡任務的執行情況
hdfs diskbalancer -query hadoop1014)取消均衡任務
hdfs diskbalancer -cancel hadoop101.plan.json切記在集群空閑的時候進行操作,不然的話rpc跨節點網路傳輸很考費資源,可能造成集群任務長時間獲取不到資源而運行失敗,
三、配置LZO壓縮
1)下載hadoop-lzo開源組件并編譯
hadoop本身并不支持lzo壓縮,所以需要使用twitter提供的hadoop-lzo開源組件,hadoop-lzo需依賴hadoop和lzo進行編譯,編譯步驟如下,
0. 環境準備
maven(下載安裝,配置環境變數,修改sitting.xml加阿里云鏡像)
gcc-c++
zlib-devel
autoconf
automake
libtool
通過yum安裝即可,yum -y install gcc-c++ lzo-devel zlib-devel autoconf automake libtool1. 下載、安裝并編譯LZO
wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gz
tar -zxvf lzo-2.10.tar.gz
cd lzo-2.10
./configure -prefix=/usr/local/hadoop/lzo/
make
make install
2. 編譯hadoop-lzo原始碼
2.1 下載hadoop-lzo的原始碼,下載地址:https://github.com/twitter/hadoop-lzo/archive/master.zip
2.2 解壓之后,修改pom.xml
<hadoop.current.version>3.1.3</hadoop.current.version>
2.3 宣告兩個臨時環境變數
export C_INCLUDE_PATH=/usr/local/hadoop/lzo/include
export LIBRARY_PATH=/usr/local/hadoop/lzo/lib
2.4 編譯
進入hadoop-lzo-master,執行maven編譯命令
mvn package -Dmaven.test.skip=true
2.5 進入target,hadoop-lzo-0.4.21-SNAPSHOT.jar 即編譯成功的hadoop-lzo組件
2)將編譯好的hadoop-lzo-0.4.20.jar放入${HADOOP_HOME}/share/common/
3)同步hadoop-lzo-0.4.20.jar到集群中的其他節點
4)core-site.xml增加配置支持LZO壓縮
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>5)同步core-site.xml至集群中的其他節點
四、LZO創建索引
1)創建LZO檔案的索引,LZO壓縮檔案的可切片特性依賴于其索引,所以需要手動為LZO壓縮檔案創建索引,若無索引,則LZO檔案的切片只有一個,
hadoop jar /opt/install/hadoop/share/common/hadoop-lzo.jar com.hadoop.compression.lzo.DistributedLzoIndexer big_file.lzo2)測驗
(1)將bigtable.lzo(200M)上傳到集群的根目錄
hdfs dfs -mkdir /input
hdfs dfs -put bigtable.lzo /input(2)執行wordcount程式
hadoop jar /opt/install/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /input /output1
(3)對上傳的LZO檔案建索引
hadoop jar /opt/install/hadoop/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/bigtable.lzo(4)再次執行WordCount程式
hadoop jar /opt/install/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /input /output2
3)注意:如果以上任務,在運行程序中報如下例外
Container [pid=8468,containerID=container_1594198338753_0001_01_000002] is running 318740992B beyond the 'VIRTUAL' memory limit. Current usage: 111.5 MB of 1 GB physical memory used; 2.4 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1594198338753_0001_01_000002 :解決辦法:在hadoop101的/opt/install/hadoopetc/hadoop/yarn-site.xml檔案中增加如下配置,然后分發到hadoop102、hadoop103服務器上,并重新啟動集群,
<!--是否啟動一個執行緒檢查每個任務正使用的物理記憶體量,如果任務超出分配值,則直接將其殺掉,默認是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否啟動一個執行緒檢查每個任務正使用的虛擬記憶體量,如果任務超出分配值,則直接將其殺掉,默認是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>五、Hadoop集群基準測驗
1) 測驗HDFS寫性能
測驗內容:向HDFS集群寫10個128M的檔案
hadoop jar /opt/install/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.2.1-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
-------------------------------------------------------------------------------------------
2021-08-21 16:24:54,075 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2021-08-21 16:24:54,075 INFO fs.TestDFSIO: Date & time: Sat Aug 21 16:24:54 CST 2021
2021-08-21 16:24:54,075 INFO fs.TestDFSIO: Number of files: 10
2021-08-21 16:24:54,075 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-08-21 16:24:54,075 INFO fs.TestDFSIO: Throughput mb/sec: 7.67
2021-08-21 16:24:54,075 INFO fs.TestDFSIO: Average IO rate mb/sec: 7.73
2021-08-21 16:24:54,075 INFO fs.TestDFSIO: IO rate std deviation: 0.67
2021-08-21 16:24:54,075 INFO fs.TestDFSIO: Test exec time sec: 37.47
2021-08-21 16:24:54,076 INFO fs.TestDFSIO:
-------------------------------------------------------------------------------------------2)測驗HDFS讀性能
測驗內容:讀取HDFS集群10個128M的檔案
hadoop jar /opt/install/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.2.1-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
-------------------------------------------------------------------------------------------
2021-08-21 16:28:11,894 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2021-08-21 16:28:11,894 INFO fs.TestDFSIO: Date & time: Sat Aug 21 16:28:11 CST 2021
2021-08-21 16:28:11,894 INFO fs.TestDFSIO: Number of files: 10
2021-08-21 16:28:11,894 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-08-21 16:28:11,894 INFO fs.TestDFSIO: Throughput mb/sec: 659.11
2021-08-21 16:28:11,894 INFO fs.TestDFSIO: Average IO rate mb/sec: 750.62
2021-08-21 16:28:11,894 INFO fs.TestDFSIO: IO rate std deviation: 299.71
2021-08-21 16:28:11,894 INFO fs.TestDFSIO: Test exec time sec: 17.37
2021-08-21 16:28:11,894 INFO fs.TestDFSIO:
-------------------------------------------------------------------------------------------3)洗掉測驗生成資料
hadoop jar /opt/inistall/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.2.1-tests.jar TestDFSIO -clean4)使用Sort程式評測MapReduce
(1)使用RandomWriter來產生亂數,每個節點運行10個Map任務,每個Map產生大約1G大小的二進制亂數
hadoop jar /opt/install/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar randomwriter random-data(2)執行Sort程式
hadoop jar /opt/install/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar sort random-data sorted-data(3)驗證資料是否真正排好序了
hadoop jar /opt/install/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.2.1-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data六、Hadoop引數調優
6.1 HDFS引數調優hdfs-site.xml
<!--The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一個作業執行緒池,用來處理不同DataNode的并發心跳以及客戶端并發的元資料操作,
對于大集群或者有大量客戶端的集群來說,通常需要增大引數dfs.namenode.handler.count的默認值10,-->
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>dfs.namenode.handler.count=![]() ,比如集群規模為8臺時,此引數設定為41,可通過簡單的python代碼計算該值,代碼如下,
,比如集群規模為8臺時,此引數設定為41,可通過簡單的python代碼計算該值,代碼如下,
python
Python 2.7.5 (default, Aug 11 2021, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import math
>>> print int(20*math.log(8))
41
>>> quit()6.2 YARN引數調優yarn-site.xml
(1)情景描述:總共7臺機器,每天幾億條資料,資料源->Flume->Kafka->HDFS->Hive
面臨問題:資料統計主要用HiveSQL,沒有資料傾斜,小檔案已經做了合并處理,開啟的JVM重用,而且IO沒有阻塞,記憶體用了不到50%,但是還是跑的非常慢,而且資料量洪峰過來時,整個集群都會宕掉,基于這種情況有沒有優化方案,
(2)解決辦法:
記憶體利用率不夠,這個一般是Yarn的2個配置造成的,單個任務可以申請的最大記憶體大小,和Hadoop單個節點可用記憶體大小,調節這兩個引數能提高系統記憶體的利用率,
(a)yarn.nodemanager.resource.memory-mb
表示該節點上YARN可使用的物理記憶體總量,默認是8192(MB),注意,如果你的節點記憶體資源不夠8GB,則需要調減小這個值,而YARN不會智能的探測節點的物理記憶體總量,
(b)yarn.scheduler.maximum-allocation-mb
單個任務可申請的最多物理記憶體量,默認是8192(MB),
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295597.html
標籤:其他