1 zookeeper必備知識
- zk的整體結構很像java中的數,zk的單個節點很像java中的接待,也就是一個Node由value值和nexts指標構成;也就是ls /作為根節點,其它節點都派生于此
- ls時用于查看目錄結構的命令,比如 ls / 該命令就是查看根目錄下的子目錄;目錄可以理解為zk節點中 指標所表示的內容,而每個節點也有自己的值,可以通過get {path} 即可獲到節點的值
- 有的節點只是為了存盤值而已,也有的節點完全起到目錄的作用,不會存盤值(null),比如kafka存盤在zookeeper上的節點資訊中 /brokers,/ids只是作為目錄;而/controller_epoch只是作為
- Node 可以分為持久節點和臨時節點兩類,所謂持久節點是指一旦這個 ZNode 被創建了,除非主動進行 ZNode 的移除操作,否則這個 ZNode 將一直保存在 ZooKeeper 上,而臨時節點就不一樣了,它的生命周期和客戶端會話系結,一旦客戶端會話失效,那么這個客戶端創建的所有臨時節點都會被移除,
- Watcher(事件監聽器),是 ZooKeeper 中的一個很重要的特性,ZooKeeper 允許用戶在指定節點上注冊一些 Watcher,并且在一些特定事件觸發的時候,ZooKeeper 服務端會將事件通知到感興趣的客戶端上去,該機制是 ZooKeeper 實作分布式協調服務的重要特性,
2 zk節點和watcher在kafka中的體現
Kakfa Broker集群受Zookeeper管理,所有的Kafka Broker節點一起去Zookeeper上注冊一個臨時節點,因為只有一個Kafka Broker會注冊成功(共同注冊/controller,但最終只有一個成功),其他的都會失敗,所以這個成功在Zookeeper上注冊臨時節點的這個Kafka Broker會成為Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower,也就是為/Controller節點在ZooKeeper注冊Watch,這個Controller會監聽其他的Kafka Broker的所有資訊,如果這個kafka broker controller宕機了,在zookeeper上面的那個臨時節點就會消失,此時所有的kafka broker又會一起去 Zookeeper上注冊一個臨時節點,因為只有一個Kafka Broker會注冊成功,其他的都會失敗,所以這個成功在Zookeeper上注冊臨時節點的這個Kafka Broker會成為Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower ,例如:一旦有一個broker宕機了,這個kafka broker controller會讀取該宕機broker上所有的partition在zookeeper上的狀態,并選取ISR串列中的一個replica作為partition leader(如果ISR串列中的replica全掛,選一個幸存的replica作為leader; 如果該partition的所有的replica都宕機了,則將新的leader設定為-1,等待恢復,等待ISR中的任一個Replica“活”過來,并且選它作為Leader;或選擇第一個“活”過來的Replica(不一定是ISR中的)作為Leader),這個broker宕機的事情,kafka controller也會通知zookeeper,zookeeper就會通知其他的kafka broker,
在Kafka的設計中,選擇了使用Zookeeper來進行所有Broker的管理,kafka組態檔中有關kafka和zookeeper的配置如下,意思是每個broker上的本地zookeeper都會注冊整個kafka集群的服務資訊
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
以下是每個broker服務上zookeeper的連接配置
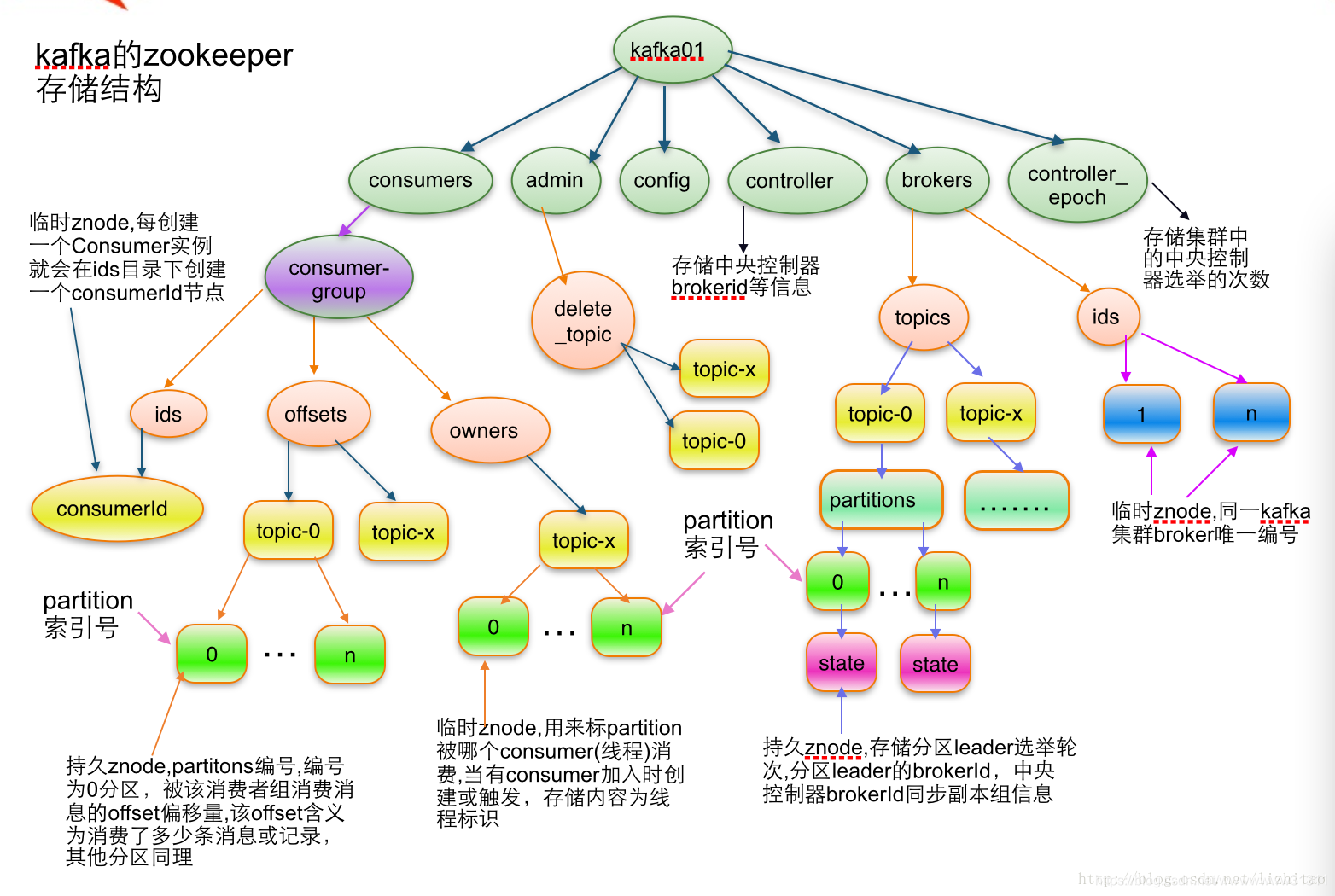
/brokers/ids專門用來進行kafka集群服務器串列記錄的點;
/brokers/topics專門用來記錄kafka集群服務器中的全部topic;
/brokers/topics/{topicName}:記錄名為xxx的topic
/brokers/topics/topic-n/partitions:記錄每個topic下的全部磁區資訊,包括一個【offse】
/brokers/topics/topic-n/partitions/{partitionNo}:0代表0號磁區,1代表1號磁區,以此類推
/brokers/topics/topic-n/partitions/{partitionNo}/state:存盤中央控制器controller選取次數、leader partition所在broker的id,leader選舉此時,初始時0,isr資訊
/controller:kafka 存盤服務器集群注冊到zookeeper時成為controller的broker這個節點資訊
/controller_epcho:kafka 存盤服務器集群注冊到zookeeper時成為controller的broker這個節點資訊
宣告:0.9之前offset存盤在zk下,也就是consumer相關的資訊存在zk下的consumers下了,但是0.9版本后consumer的資訊存盤在了brokers上的一塊記憶體中了 /brokers/topics/__consumer_offsets/下存盤,其中offset時以topic的磁區為單位進行存盤的,offset在通過javaapi些代碼時會接觸到
每個Broker服務器在啟動時,都會到Zookeeper上進行注冊,即創建/brokers/ids/[0-N]的節點,然后寫入IP,埠等資訊,Broker創建的是臨時節點,所有一旦Broker上線或者下線,對應Broker節點也就被洗掉了,因此我們可以通過zookeeper上Broker節點的變化來動態表征Broker服務器的可用性,Kafka的Topic也類似于這種方式,
Kakfa Broker Leader的選舉:
前提是整個kafka集群連接同一套zookeeper, Kakfa Broker集群受Zookeeper管理,所有的Kafka Broker節點一起去Zookeeper上注冊一個臨時節點,因為只有一個Kafka Broker會注冊成功,其他的都會失敗,所以這個成功在Zookeeper上注冊臨時節點的這個Kafka Broker會成為Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower,(這個程序叫Controller在ZooKeeper注冊Watch),這個Controller會監聽其他的Kafka Broker的所有資訊,如果這個kafka broker controller宕機了,在zookeeper上面的那個臨時節點就會消失,此時所有的kafka broker又會一起去 Zookeeper上注冊一個臨時節點,因為只有一個Kafka Broker會注冊成功,其他的都會失敗,所以這個成功在Zookeeper上注冊臨時節點的這個Kafka Broker會成為Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower ,例如:一旦有一個broker宕機了,這個kafka broker controller會讀取該宕機broker上所有的partition在zookeeper上的狀態,并選取ISR串列中的一個replica作為partition leader(如果ISR串列中的replica全掛,選一個幸存的replica作為leader; 如果該partition的所有的replica都宕機了,則將新的leader設定為-1,等待恢復,等待ISR中的任一個Replica“活”過來,并且選它作為Leader;或選擇第一個“活”過來的Replica(不一定是ISR中的)作為Leader),這個broker宕機的事情,kafka controller也會通知zookeeper,zookeeper就會通知其他的kafka broker,
消費者生產者負載均衡
生產者需要將訊息合理的發送到分布式Broker上,這就面臨如何進行生產者負載均衡問題,
對于生產者的負載均衡,Kafka支持傳統的4層負載均衡,zookeeper同時也支持zookeeper方式來實作負載均衡,
(1)傳統的4層負載均衡
根據生產者的IP地址和埠來為其定一個相關聯的Broker,通常一個生產者只會對應單個Broker,只需要維護單個TCP鏈接,這樣的方案有很多弊端,因為在系統實際運行程序中,每個生產者生成的訊息量,以及每個Broker的訊息存盤量都不一樣,那么會導致不同的Broker接收到的訊息量非常不均勻,而且生產者也無法感知Broker的新增與洗掉,
(2)使用zookeeper進行負載均衡
很簡單,生產者通過監聽zookeeper上Broker節點感知Broker,Topic的狀態,變更,來實作動態負載均衡機制,當然這個機制Kafka已經結合zookeeper實作了,
4.記錄訊息磁區于消費者的關系,都是通過創建修改zookeeper上相應的節點實作,而且還會記錄訊息消費進度Offset記錄,都是通過創建修改zookeeper上相應的節點實作,
kafka日志資料分離操作
原因:kafka中的資料存盤配置欄位為logs.dir,容易讓人誤解為日志,事實上kafka的日志和資料都是存在/kafka/logs下的,需要手動進行分離,但并非一定要分離,看個人愛好
- 洗掉kafka集群下kafka/logs檔案夾
- 洗掉zk集群下的zookeeper/zkData中的version檔案
資料分離后創建一個磁區數何副本數都為2的topic first,那么/kafka-data下會生成first-0和first-1兩份資料檔案分別代表first兩個磁區的檔案,另外的兩個副本分別在其它位置,這里起到了資料庫的作用,在一段時間記憶體儲資料 => 主題是邏輯上的,磁區時物理上的
kafka的每個磁區資料如果不加以控制就會無限堆積,所以kafka的磁區存在分片機制即每超過1g就進行分片segement,每個分片單獨具有一個log和一個index,log是實實在在存盤資料的,index可以看著是log的索引

00000000000000170410.log這個檔案記錄了第170411到~(下一個log檔案編號)的訊息,
00000000000000170410.index:假設這個訊息中有N條訊息,第3條訊息在index檔案中對應的是348,也就是說在log檔案中,第3條訊息的偏移量為348,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295592.html
標籤:其他