我有以下資料框
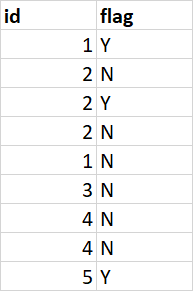
我想按 id 分組并添加一個包含 Y 的標志列,如果任何時候 Y 發生在 id 上,結果 DF 想要
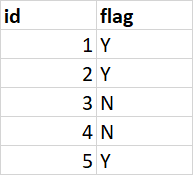
這是我的方法,太耗時且不確定正確性
temp=pd.DataFrame()
j='flag'
for i in df['id'].unique():
test=df[df['id']==i]
test[j]=np.where(np.any((test[j]=='Y')),'Y',test[j])
temp=temp.append(test)
uj5u.com熱心網友回復:
你可以這樣groupby max做Y > N:
df.groupby('id', as_index=False)['flag'].max()
id flag
0 1 Y
1 2 Y
2 3 N
3 4 N
4 5 Y
uj5u.com熱心網友回復:
比較flag、Y分組id和使用any:
new_df = (df['flag'] == 'Y').groupby(df['id']).any().map({True:'Y', False:'N'}).reset_index()
輸出:
>>> new_df
id flag
0 1 Y
1 2 Y
2 3 N
3 4 N
4 5 Y
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/470700.html