在[上一章](https://www.yuque.com/docs/share/adb5b1e4-f3c6-46fd-ba4b-4dabce9b4f2a?# 《現代C++學習指南-型別系統》)我們探討了C++的型別系統,并提出了從低到高,又從高到低的學習思路,本文就是一篇從高到低的學習指南,希望能提供一種新的視角,
什么是標準庫
編程語言一般分為兩個部分,一部分是語法部分,如上一章的型別系統,另一部分則是用這套語法完成的預定義的工具集,如本文的主題——標準庫,標準庫是一堆我們寫代碼時直接可以用的代碼,就像是我們提前寫好的一樣,不僅如此,標準庫還是跨平臺的,還是經過工業級測驗的,所以標準庫有著靠譜,安全的特點,
C++標準庫包括很多方面,有類vector、string等,有物件std::cin,std::cout等,還有函式move,copy等,所以一般按功能來對它們分類
- 容器類
- 演算法類
- 智能指標
- 執行緒相關
- 其他
當然,這些還不是全部,標準庫是在不斷擴充和完善的,學習標準庫的宗旨也應該是學習它們的使用場景,而不是深入用法,比如容器類中就有很多功能類似的類,不同的業務場景有不同的選擇,通過對它們的了解,我們更容易寫出高效,簡潔的代碼,
容器類
容器類就是幫助管理一組資料的類,根據實作方式的不同,分為有序串列,無序串列和映射,
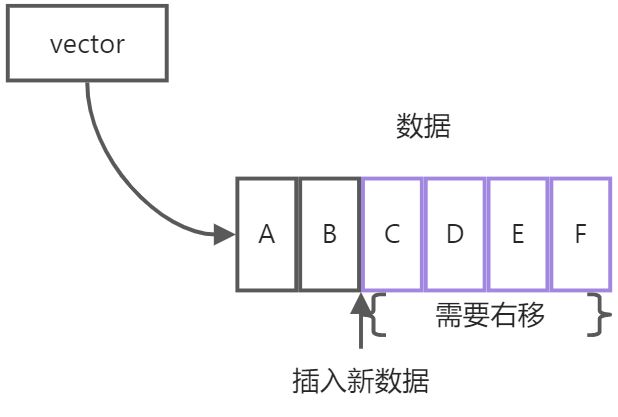
有序串列中的有序是指,資料組保存在一塊連續的記憶體區域里,可以通過插入時的索引直接定位到原資料,因為資料是按順序存入的,所以中途假如需要洗掉或者新增資料,在操作位置右邊的資料都需要移動,操作的代價就比較大,由此也可看出它們的優勢是順序插入和尾部修改,還有直接查找,這方面的代表就是array,vector,
array是對原始陣列的封裝,并且解決了傳遞陣列變成指標這樣的問題,但是缺點是它的大小是固定的,適合用在資料量已知的情況,而vector又是對array的增強,不僅能完成所有array的操作,并且大小可變,所以絕大部分情況下,選擇vector都是理想的選擇,
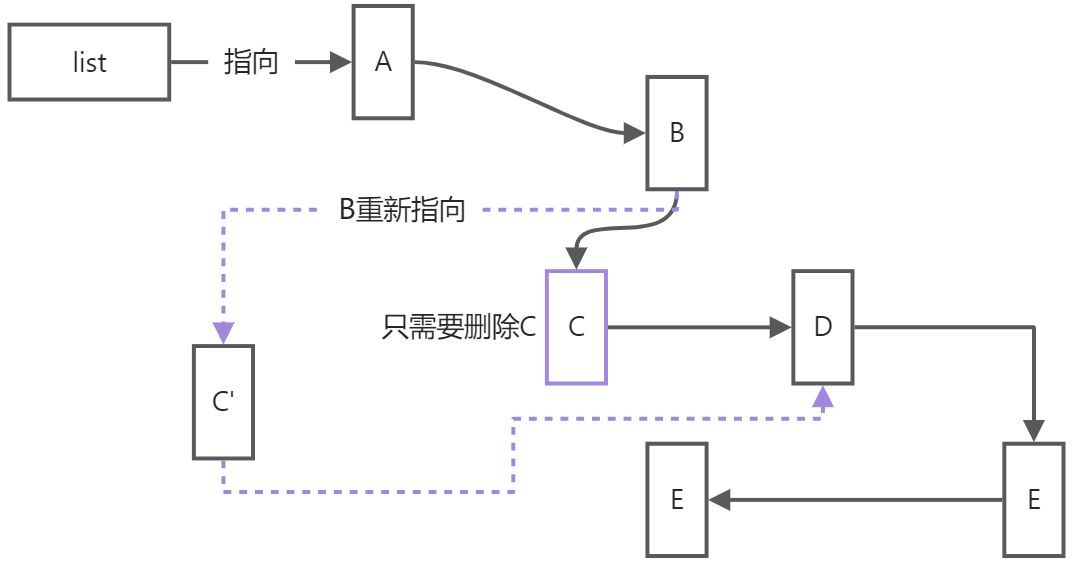
無序串列的元素是單獨存盤的,相互之間用指標來查找相鄰元素,由于指標可以輕易修改指向的指,所以對相鄰元素的修改就變得很快捷,同樣的道理,查找相鄰元素只能靠指標跳轉,查找某個值需要從一個指標開始查找,一次跳轉一條資料,直到找到目標或者沒有資料為止,所以無序串列的優勢是快速地洗掉和插入新資料,不適合查找,其代表有list,forward_list,顯然,有序串列和無序串列是互補的,我們在實際專案中,應該根據資料的操作來確定選擇哪種容器,
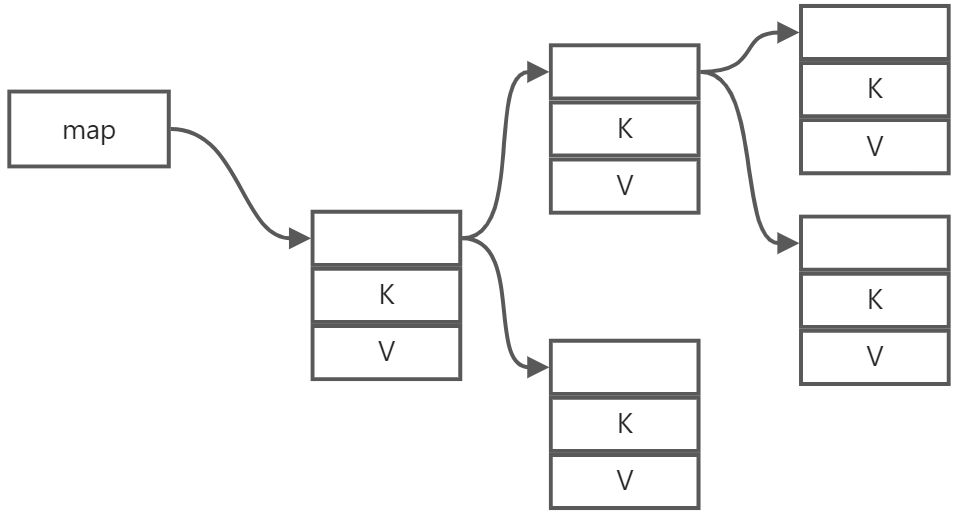
映射則融合了有序串列和無序串列的優點,既可以快速插入和洗掉,又可以快速查找,為了滿足各種使用場景,C++提供了map,multimap,unordered_map,unordered_multimap,從名字上就能看出來它們的差別,為了直觀,我直接列了一個表
| 是否排序 | 是否支持相同值 | 速度 | |
|---|---|---|---|
| unordered_map | ? | ? | ???????? |
| map | ? | ? | ???? |
| multimap | ? | ? | ?? |
| unordered_multimap | ? | ? | ?????? |
映射存盤的是兩個值,不同的型別實作方式不一樣,由于map是需要排序的,所以通常它的實作是一種平衡二叉樹,鍵就是它排序的依據,
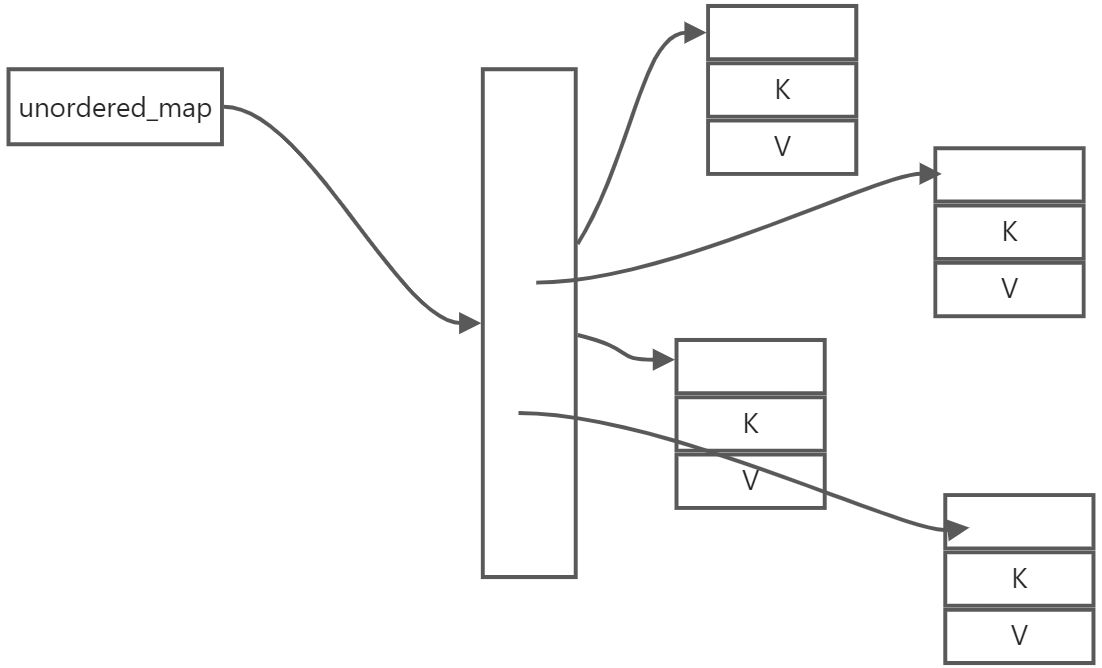
而unordered_map是不需要排序的,所以它的實作通常是哈希表,即根據哈希函式的確定索引位置繼而確定存盤位置,
綜上,容器類提供了一種操作多個同型別資料的介面,開發者通過對容器類方法的呼叫,可以實作對容器內資料的增刪改查,大部分情況下,vector都是靠譜的選擇,它提供了全功能的資料操作介面,支持動態長度,索引查詢,并且簡單高效,如果需要頻繁地插入或者洗掉操作,也可以考慮list或者forward_list,map可以讓資料保持有序,需要更快的速度而不是排序的話unorderer_map是更好的選擇,如果相同值會出現多次就可以使用對應的multi版本,另外容器類也是很好的資料結構學習資源,C++的容器類幾乎提供了資料結構中所有的形式,對資料結構越熟悉選擇的容器類就越完美,
演算法
之所以將演算法放在容器類后面,是因為演算法大部分是對容器類操作的加強,演算法都定義在algorithm檔案頭里,這些演算法都是短小精悍的,可以大大增加代碼可讀性,并且妥善處理了很多容易遺忘的邊界問題,功能上可以分為增刪改查幾種操作,可以在實際有需要的時候在查看檔案,具體可以參閱這里
智能指標
很早以前,我對智能指標的態度不是很好,因為剛開始學習C++時我就知道,不能單獨使用指標,要把指標封裝在類里,利用類的建構式和解構式管理指標,也就是RAII,最開始我以為這就夠了,直到我遇到下面這種情況
public:
Ptr():p{ new int } {}
~Ptr() {
delete p;
}
int& get() {
return *p;
}
void set(const int value) {
*p = value;
}
private:
int* p;
};
void use(Ptr p) {
//傳進來的是復制構造出來的p',函式回傳后p'被銷毀啦,兩個指標指向的地址被回收,外面的p指標成為了野指標
}
int main() {
Ptr p;
p.set(1);
use(p); //p按值傳遞,呼叫了Ptr的復制建構式,構造出了新物件p',它的指標和p的指標指向同一個地方
std::cout << p.get() << std::endl; //p已經被銷毀了,訪問p的地址非法
return 0;
}
呼叫use時,變數p被拷貝,也就出現了兩個指標同時指向一塊記憶體地址的情況,use函式執行完后,它的引數p被回收,也就是呼叫了Ptr的解構式,也就是兩個指標指向的地址被回收,所以24行呼叫get讀取那個已經被回收了的地址就是非法操作,程式崩潰,
這可能是新手比較常遇到的一個問題,當然,解決這個問題也很簡單,還用不到智能指標,只需要將函式use的引數改為參考型別就可以了,因為參考只是別名,不會產生新的指標,這也是我在型別系統篇中極力推薦參考為首選引數型別的原因之一,對于此例,資料不大,直接重寫復制建構式,重新申請一塊記憶體也是一種思路,
此例中用到Ptr的地方只有一個,實際專案中Ptr往往需要用到很多次,我們不能保證不會出現忘記使用參考型別的情況,這種情況下重新申請記憶體也不適用,所以這個時候就需要智能指標來幫忙了,
現在思考另一種情況,某些操作我們不得不暴露出我們的指標供外部使用,隨著業務的嵌套和呼叫鏈增加,很多時候會忘記或者不確定在什么時候呼叫delete釋放記憶體,這也是用智能指標的一個場景,以上兩種情況都是需要分享指標,對應智能指標中的shared_ptr,
shared_ptr顧名思義,它可以幫助開發者完成指標共享的問題,并且完美解決提前釋放,不知何時釋放,誰負責釋放的問題,它的對應關系是一對多,一個實際的記憶體可以被多個shared_ptr共享
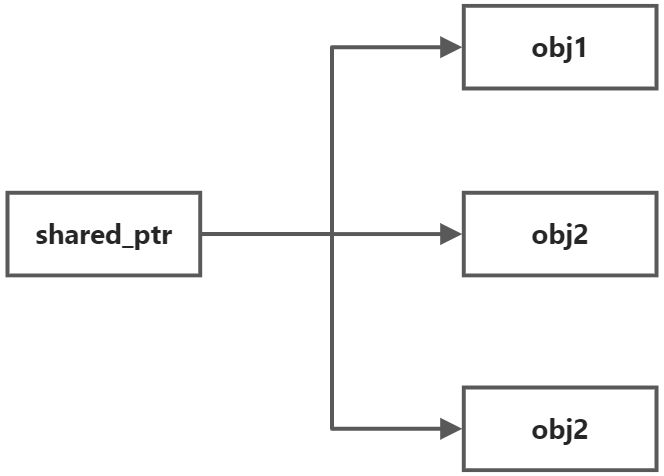
另外一種場景是我們希望自始至終某個指標某個時刻只屬于一個物件,外部想要使用它要么通過擁有該指標的物件方法,要么把指標的所有權轉移到自己身上,這種場景對應智能指標中的unique_ptr,
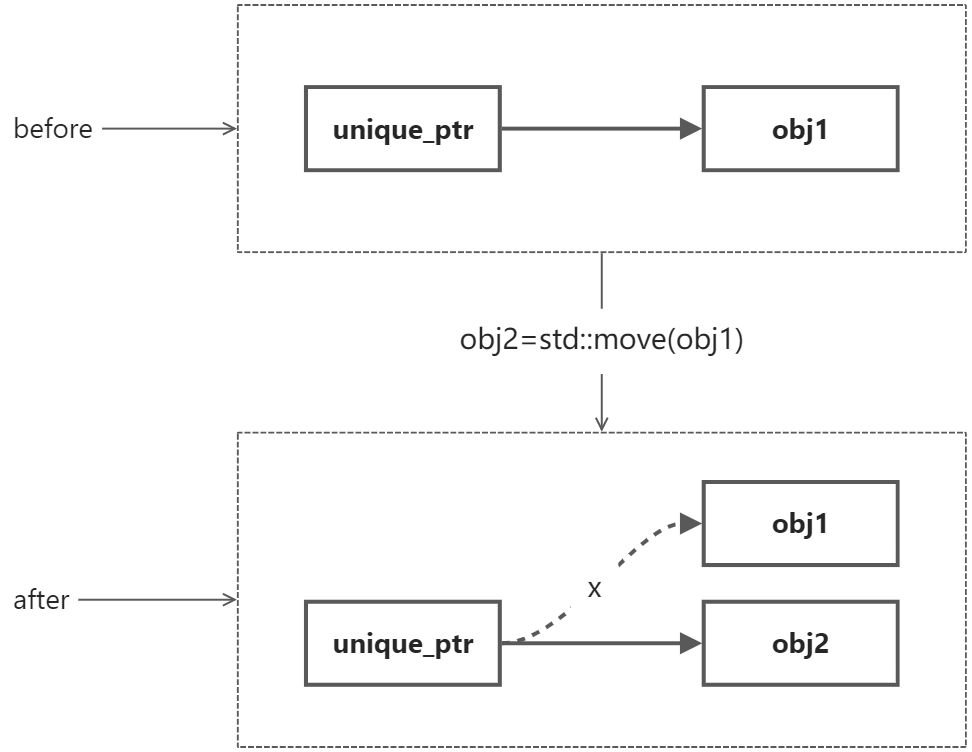
unique_ptr的對應關系是一對一,無論哪個時刻,只能有一個管理者擁有指標,也就只能由它負責釋放了,假如想轉移這種對應關系,只能通過std::move操作,不過這個操作之后,原先物件的指標就失效了,它也不再負責管理,所有的任務移交給了新的物件,這種特性特別適合資源敏感型的應用,
執行緒庫
除了記憶體,執行緒是開發中另一個重要的課題,執行緒的難點在于不僅要管理執行緒物件,還要管理執行緒物件管理的資源,并且保證執行緒間資料同步,當然標準庫已經做得足夠好了,我們需要理解的是使用場景的問題,執行緒庫主要包括執行緒物件thread,條件物件condition_variable,鎖物件mutex,
使用thread可以很方便地把程式寫成多執行緒,只需要三步:
void plus(int a,int b){ //第一步:定義執行緒中要運行的函式
std::cout<<"running at sub thread"<<std::endl;
std::cout<<"a + b = "<<a+b<<std::endl;
}
int main(){
std::thread thread{plus,1,1}; //第二步,定義std::thread物件,將函式作為引數
std::cout<<"continue running at main thread"<<std::endl;
thread.join(); //第三步呼叫執行緒物件的join函式或者detach函式
std::cout<<"sub thread finished!"<<std::endl;
}
//輸出
// continue running at main thread
// running at sub thread
// a + b = 2
// sub thread finished!
難點在執行緒間通信,也就是解決兩個問題
- 執行緒1更新了變數v的值
- 執行緒2馬上能讀取到正確的變數v的值,即執行緒1更新的那個最新值
為了協調這兩個程序,就出現了鎖物件mutex和條件物件condition_variable,鎖物件mutex保證變數按照正確的順序更改,條件物件condition_variable保證更改能被其他執行緒監聽到,
int a,b;
bool ready = false;
std::mutex mux;
std::condition_variable con;
void plus() {
std::cout << "running at sub thread" << std::endl;
//因為我們要讀取ready的最新值,所以要用鎖保證讀取結果的有效性
std::unique_lock<std::mutex> guard{ mux };
if (!ready) {
//資料沒準備好,休息一下!
con.wait(guard);
}
//這里就可以正確讀變數a,b了
std::cout << "a + b =" << a + b << std::endl;
}
int main() {
std::thread thread{ plus};
std::cout << "continue running at main thread" << std::endl;
std::cout << "input a = ";
std::cin >> a;
std::cout << "input b = ";
std::cin >> b;
{
//資料準備好了,該通知子執行緒干活了,用大括號是因為想讓鎖因為guard的銷毀即使釋放,從未保證plus里面能重新獲得鎖
std::unique_lock<std::mutex> guard{ mux };
//更新資料
ready = true;
//通知
con.notify_all();
}
thread.join();
std::cout << "sub thread finished!" << std::endl;
}
多執行緒另一個需要注意的問題就是死鎖,死鎖的前提是有兩個鎖
- 執行緒1得到了鎖a,還想得鎖b
- 執行緒2得到了鎖b,還想得鎖a
然后,再加上一個前提:某一時刻,只有一個執行緒能擁有某個鎖,就不難得出以下結論:執行緒a,b除非某一個放棄已得的鎖,不然兩個執行緒都會因為沒得到需要的鎖而一直死等,形成死鎖,同時解決死鎖的思路也呼之欲出:既然一個得了a,一個得了b,而鎖同一時間只能被一個執行緒得到,那么所有執行緒都按先得a,再得b的順序來就不會有鎖被占用的問題了,另一個思路則可以從放棄上入手,既然都得不到,那么接下來的任務也做不了,不如直接放棄已經得到的,所以可以考慮使用timed_mutex,
其他
還有很多常用的庫,如字串string,時間chrono,還有在定義函式變數時常用的functional,例外exception,更多的內容可以在cplusplus找的參考,
總結
總的來說,標準庫提供了一個展現C++語言能力的平臺:幫助開發者更好更快完成開發任務的同時,還能啟迪開發者實作更好的抽象和實踐,如我就從標準庫中學到了更規范地定義函式引數,更好的封裝,以及其他好的思路,學習標準庫不僅更好地掌握了語言本身,還掌握了更全面地分析問題,解決問題的方法,是值得花費一段時間學習的,
容器類是幾乎所有專案都會用到的,也是比較好掌握的,主要可以從資料結構方面對照學習;智能指標則是處理指標問題的好幫手;執行緒相關的庫是比較難掌握的,關鍵是要想明白使用場景和極端情況下的邊界問題,很多時候邊界問題可能不那么直觀,如執行緒要求獲得鎖的情況就分為:鎖空閑,鎖被其他執行緒占有,鎖被自己占有,不同的邊界對于不同的鎖,預期結果也是不同的,只有在明確場景的情況下,才能更好地理清鎖的關系,從而解決好問題,
最好的學習還是在實踐中主動使用,對于我,通常在遇到新問題的時候會先查查標準庫有沒有相應的庫,有的話就是學習這個庫的好時機,可以先概類別庫的定義和解決的問題,然后分析它提供的類,函式,物件等,再將自己的理解轉換為專案中的代碼,最后在實際效果中檢驗和修正想法,完成庫的學習,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/555556.html
標籤:其他
上一篇:Python 標準類別庫-并發執行之multiprocessing-基于行程的并行
下一篇:返回列表