前言
本篇文章主要介紹的關于本人從剛作業到現在使用Sql一些使用方法和經驗,從最基本的SQL函式使用,到一些場景的業務場景SQL撰寫,
SQL基礎函式使用
1.欄位轉換
CASE WHEN
意義: If(a==b) a=c;
用法:
1, CASE 欄位 WHEN 欄位結果1 THEN 欄位顯示結果1 WHEN 欄位結果2 THEN 欄位顯示結果2 END
2, CASE WHEN 欄位1=欄位結果1 THEN 欄位顯示結果1 WHEN 欄位2=欄位結果2 THEN 欄位顯示結果2 END

2.替換空值
意義: if(a==null) a=0;
MySQL:IFNULL
用法:IFNULL(欄位,0)別名
Oracle:NVL
用法:NVL(欄位,0)別名
Sybase: ISNULL
用法:ISNULL(欄位,0)別名


3.合計函式
GROUP BY
例:SELECT 欄位1, 【如sum】函式名(欄位2) FROM 表名 GROUP BY 欄位1

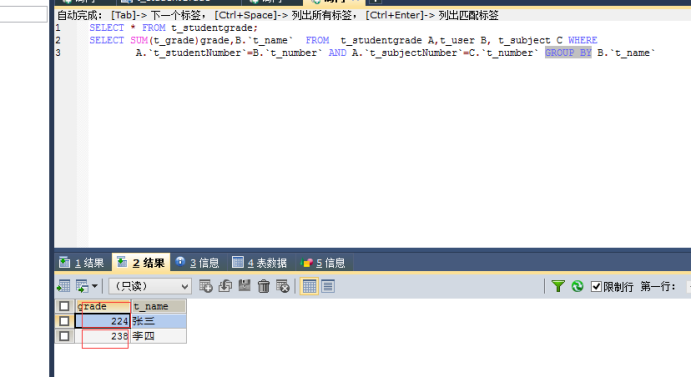
4.取某段資料
Mysql: LIMIT
用法: select * from 表 LIMIT 數字 ----取零到數字中的資料
select * from 表 LIMIT 數字1,數字2 ----取數字1到數字2中的資料
Oracle: rownum
用法:select * from 表 rownum<=2 ----取表中的頭兩條資料
Sybase : TOP
用法: SELECT TOP 2 * FROM 表名 ----選取表中的頭兩條資料
SELECT TOP 50 PERCENT * FROM 表名 ----選取表中50%的記錄


5.截取字串
substr
例:
select substr(欄位名,起始位置,長度)自定義名 from 表名

6.查詢結果增加序號
SET @rownum=0;
SELECT @rownum := @rownum +1 AS aid, h.* FROM household h;

7.查詢平均小于的某某的資料
group by 和having的使用
SELECT user_id FROM t_user GROUP BY user_id HAVING AVG(user_age)<22;
8.洗掉重復的元素,保留一條
delete from 表名 where 主鍵 in
(select 主鍵 from 表名 group by 洗掉的欄位資料名 having count(1) > 1)
and 主鍵 not in (select min(主鍵) from 表名 group by 洗掉的欄位資料名 having count(1)>1)
9. 日期格式使用
DATE_FORMAT 可以把日志格式化成想要的格式
DATE_FORMAT(date, format)
sql設定日期格式TO_DATE(欄位名,YYYY-MM-DD)欄位名
時間格式化:
SELECT DATE_FORMAT(a.`update_time`,'%Y-%m-%d %H:%i:%S') AS updateTime,
a.`update_time` FROM t_user a
例如:
SELECT DATE_FORMAT('2018-10-10 00:00:00', '%Y%m%d')
查詢結果為 20181010
根據日期得到星期幾DAYOFWEEK是從周日開始,所以要減一,WEEKDAY是從0開始,所有要加一
SELECT DAYOFWEEK('2021-4-22')-1,WEEKDAY('2021-4-20')+1
10.UNION和UNION All比較
UNION在進行表鏈接后會篩選掉重復的記錄 UNION ALL只是簡單的將兩個結果合并后就回傳
例:SELECT 欄位 FROM 表1
UNION
SELECT 欄位 FROM 表2
SELECT 欄位 FROM 表1
UNION ALL
SELECT 欄位 FROM 表2
11. sql之left join、right join、inner join的區別
left join(左聯接) 回傳包括左表中的所有記錄和右表中聯結欄位相等的記錄
左表回傳的值一定大于或等于右表的值
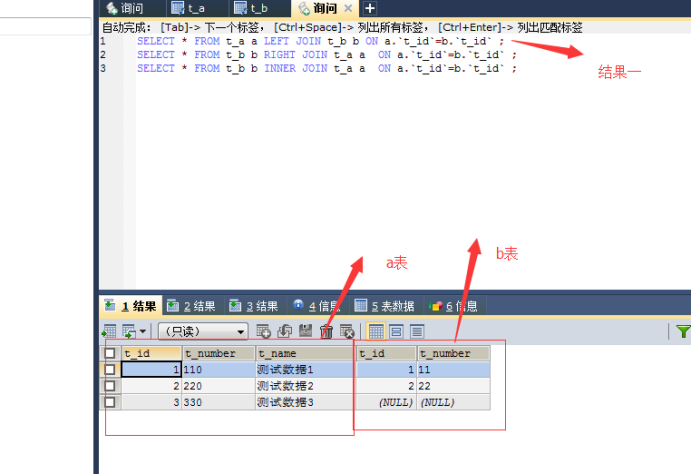
right join(右聯接) 回傳包括右表中的所有記錄和左表中聯結欄位相等的記錄
右表回傳的值一定大于或等于左表的值

inner join(等值連接) 只回傳兩個表中聯結欄位相等的行
左表回傳的值一定等于右表回傳的值

常用SQL
1.解鎖sql表
MySql
1.查看是否有鎖表
SHOW OPEN TABLES WHERE In_use > 0;
2.查詢產生鎖的具體sql
select a.trx_id 事務id ,a.trx_mysql_thread_id 事務執行緒id,a.trx_query 事務sql from INFORMATION_SCHEMA.INNODB_LOCKS b,INFORMATION_SCHEMA.innodb_trx a where b.lock_trx_id=a.trx_id;
3.殺死產生鎖的事物執行緒
根據具體的sql判斷是不是死鎖,具體是什么業務,是否可以進行kill,
然后根據結果 kill掉產生鎖的事物執行緒:
select concat('KILL ',a.trx_mysql_thread_id ,';') from INFORMATION_SCHEMA.INNODB_LOCKS b,INFORMATION_SCHEMA.innodb_trx a where b.lock_trx_id=a.trx_id;
批量kill :
select concat('KILL ',a.trx_mysql_thread_id ,';') from INFORMATION_SCHEMA.INNODB_LOCKS b,INFORMATION_SCHEMA.innodb_trx a where b.lock_trx_id=a.trx_id into outfile '/tmp/kill.txt';
SqlServer
查看被鎖表:
select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableName from sys.dm_tran_locks where resource_type='OBJECT'
spid 鎖表行程
tableName 被鎖表名
解鎖:
declare @spid int Set @spid = 57
declare @sql varchar(1000)set @sql='kill '+cast(@spid as varchar)
exec(@sql)
2.查看一個欄位的在那些表中
SELECT DISTINCT TABLE_NAME FROM information_schema.`COLUMNS` WHERE COLUMN_NAME='ip' AND TABLE_SCHEMA='guard_scan' AND TABLE_NAME NOT LIKE 'vm%';
SqlServer:
select table_name from user_tab_columns where COLUMN_NAME='欄位'
3. 查詢所有表及其欄位和備注
SELECT t.table_name,
t.colUMN_NAME,
t.DATA_TYPE || '(' || t.DATA_LENGTH || ')',
t1.COMMENTS
FROM User_Tab_Cols t, User_Col_Comments t1
WHERE t.table_name = t1.table_name
AND t.column_name = t1.column_name;
4.sql資料自我復制
insert into test(name,age,gender)
select name,age,gender from test
5.洗掉重復資料,保留最小id的那一條
delete from table_name as ta where ta.唯一鍵 <> ( select max(tb.唯一鍵) from table_name as tb where ta.判斷重復的列 = tb.判斷重復的列);
6.SQL查詢相隔天數陳述句
--今天
select * from 表名 where to_days(時間欄位名) = to_days(now());
--昨天
SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 時間欄位名) = 1
--本周
SELECT * FROM 表名 WHERE YEARWEEK( date_format( 時間欄位名,'%Y-%m-%d' ) ) = YEARWEEK( now() ) ;
--本月
SELECT * FROM 表名 WHERE DATE_FORMAT( 時間欄位名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) ,'%Y%m' )
--上一個月
SELECT * FROM 表名 WHERE PERIOD_DIFF(date_format(now(),'%Y%m'),date_format(時間欄位名,'%Y%m') =1
--本年
SELECT * FROM 表名 WHERE YEAR( 時間欄位名 ) = YEAR( NOW( ) )
--上一月
SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 時間欄位名, '%Y%m' ) ) =1
--查詢本季度資料
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(now());
--查詢上季度資料
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(DATE_SUB(now(),interval 1 QUARTER));
--查詢本年資料
select * from `ht_invoice_information` where YEAR(create_date)=YEAR(NOW());
--查詢上年資料
select * from `ht_invoice_information` where year(create_date)=year(date_sub(now(),interval 1 year));
--查詢當前這周的資料
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now());
--查詢上周的資料
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now())-1;
--查詢當前月份的資料
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(now(),'%Y-%m')
--查詢距離當前現在6個月的資料
select name,submittime from enterprise where submittime between date_sub(now(),interval 6 month) and now();
--查詢上個月的資料
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(DATE_SUB(curdate(), INTERVAL 1 MONTH),'%Y-%m')
7.mysql經緯度圓周計算
單位為米
SELECT st_distance_sphere(POINT('114.43107891381024', '30.52764363752110'), POINT('114.42638694658900', '30.54681469735225')) AS distcance
8.mysql的ip地址段查詢判斷
ip查詢前三段
SELECT SUBSTRING_INDEX(ip,'.',3) FROM t_ip
示例:
SELECT SUBSTRING_INDEX(tia.ip_addr,'.',3),ip_addr FROM t_ip_all tia
WHERE SUBSTRING_INDEX(tia.ip_addr,'.',3) = '192.168.21'
9.mysql的地址段大小查詢判斷
使用INET_ATON函式進行轉換
SELECT
*
FROM
表名
WHERE
INET_ATON(ip) between INET_ATON("192.168.21.0")
AND INET_ATON("192.168.1.255")
其他
MySQL
1.查詢所有資料庫
show databases;
2.查詢指定資料庫中所有表名
select table_name from information_schema.tables where table_schema='database_name' and table_type='base table';
3.查詢指定表中的所有欄位名
select column_name from information_schema.columns where table_schema='database_name' and table_name='table_name';
4.查詢指定表中的所有欄位名和欄位型別
select column_name,data_type from information_schema.columns where table_schema='database_name' and table_name='table_name';
SQLServer
1.查詢所有資料庫
select * from sysdatabases;
2.查詢當前資料庫中所有表名
select * from sysobjects where xtype='U';
xtype='U':表示所有用戶表,xtype='S':表示所有系統表,
3.查詢指定表中的所有欄位名
select name from syscolumns where id=Object_Id('table_name');
4.查詢指定表中的所有欄位名和欄位型別
select sc.name,st.name from syscolumns sc,systypes st where sc.xtype=st.xtype and sc.id in(select id from sysobjects where xtype='U' and name='table_name');
Oracle
1.查詢所有資料庫
由于Oralce沒有庫名,只有表空間,所以Oracle沒有提供資料庫名稱查詢支持,只提供了表空間名稱查詢,
select * from v$tablespace;--查詢表空間(需要一定權限)
2.查詢當前資料庫中所有表名
select * from user_tables;
3.查詢指定表中的所有欄位名
select column_name from user_tab_columns where table_name = 'table_name';--表名要全大寫
4.查詢指定表中的所有欄位名和欄位型別
select column_name, data_type from user_tab_columns where table_name = 'table_name';--表名要全大寫
業務場景SQL
這是在一些常見的場景中個人撰寫以及收集的一些SQL,從剛開始作業的時候就有記錄,如有不妥或有更好的寫法,歡迎指出~
學生排名統計
一張表t,有class(班級)、name(學生)、score(成績)欄位
查詢每個班級成績最高的學生
思路:根據分組函式 group by 和最大值 max來實作,
Select name,class,max(score) from t group by class;
查找出每個班級成績前三的學生
思路: 通過雙重子查詢來查找
先對學生的成績進行排名,相同的為一列,然后在跟進這個結果得到前三成績的學生,
SELECT *
FROM( SELECT NAME,score , class,(SELECT COUNT(*)+1 FROM t WHERE score>b.score AND class = b.class ) rank
FROM t b) e
WHERE e.rank<=3
ORDER BY class,rank ASC;
思路二
直接找到每個班級學生的排名然后進行比較得出前三成績的學生
SELECT * FROM t a
WHERE 4 >(SELECT count(*)+1 FROM t WHERE class = a.class and score>a.score)
ORDER BY a.class,a.score DESC;
查找出每個班級成績第二的學生,
思路: 在條件里面發現最大的,然后去除最大的就是第二大的
SELECT class, MAX(score) FROM t WHERE score NOT IN (SELECT MAX(score) FROM t GROUP BY class) GROUP BY class
查詢每名學生的學科總分并排名
思路: 先用group by和sum得到總分排名,然后再利用order by將結果進行排名
SELECT *,SUM(scroe)scroe FROM a GROUP BY sID ORDER BY scroe DESC;
查詢用一條SQL 陳述句 查詢出每門課都大于80 分的學生姓名
思路一:利用group by和having 函式來查詢
SELECT * FROM a GROUP BY scroe HAVING AVG(scroe) >80;
思路二:利用子查詢來查詢
SELECT * FROM a c WHERE scroe NOT IN (SELECT scroe FROM a b WHERE scroe<='80') GROUP BY sID;
在學生成績表中進行排名,相同的成績在同一列
場景一、分數相同排名相同(如果有兩個第二,就沒有第三名)
思路: 通過子查詢的分數進行查詢比較,然后在通過子查詢的結果進行排序
不包含班級
SELECT id,NAME,score, (SELECT COUNT(*)+1 FROM t_student WHERE score>t.score) rank FROM t_student t ORDER BY rank ASC;
根據班級進行區分
SELECT class,NAME,score,(SELECT COUNT(*)+1 FROM t WHERE score>b.`score` AND class=b.`class` )rank FROM t b ORDER BY class,rank;
場景二、分數相同排名相同(如果有兩個第二,有第三名)
思路:需要使用一個額外的變數進行查詢比較
SELECT id, NAME, score ,
CASE
WHEN @prevRank = score THEN @curRank
WHEN @prevRank := score THEN @curRank := @curRank + 1
END AS rank
FROM t_student t,
(SELECT @curRank :=0, @prevRank := NULL) r
ORDER BY score
組織部門查詢
一張部門表,有id(主鍵)、name(名稱)、parent_id(父級ID)欄位
建表陳述句和測驗資料
CREATE TABLE `department` (
`id` int(11) NOT NULL,
`parent_id` int(11) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO department (id, parent_id, NAME) VALUES
(1, NULL, '總公司'),
(2, 1, '人事部'),
(3, 1, '財務部'),
(4, 1, '市場部'),
(5, 2, '招聘組'),
(6, 2, '培訓組'),
(7, 5, '招聘一部'),
(8, 5, '招聘二部'),
(9, 6, '培訓一部'),
(10, 6, '培訓二部'),
(11, 4, '推廣組'),
(12, 11, '線上推廣部'),
(13, 11, '線下推廣部'),
(14, 12, 'SEM'),
(15, 12, 'SEO');
根據部門ID查詢該部門下面所有的子部門
思路: 由于不清楚部門層級,這里需要使用遞回查詢,需要定義一個變數和FIND_IN_SET函式來實作遞回查詢,當查詢到一個部門時,將其ID添加到一個變數中,然后繼續查詢其子部門,直到所有子部門都被查詢到為止,
SELECT au.id, au.name, au.parent_id
FROM (SELECT * FROM department WHERE parent_id IS NOT NULL) au,
(SELECT @pid := ?) pd
WHERE FIND_IN_SET(parent_id, @pid) > 0
AND @pid := CONCAT(@pid, ',', id)
UNION
SELECT id, NAME, parent_id
FROM department
WHERE id = ?
ORDER BY id;
如果是MySql8.0,可以使用WITH RECURSIVE關鍵字實作遞回查詢
WITH RECURSIVE cte AS (
SELECT id, name, parent_id
FROM department
WHERE id = ?
UNION ALL
SELECT d.id, d.name, d.parent_id
FROM department d
INNER JOIN cte ON d.parent_id = cte.id
)
SELECT *
FROM cte;
根據一個部門ID,查詢所有的上級部門
思路: 這篇的作者講得很詳細,這里就不在贅述了.
https://www.cnblogs.com/liuxiaoji/p/15219091.html
SELECT t2.id, t2.name, t2.parent_id
FROM (SELECT @r as _id,
(SELECT @r := parent_id FROM department WHERE id = _id) as pid,
@l := @l + 1 as lvl
FROM (SELECT @r := ?, @l := 0) vars, dept as h
WHERE @r <> 0) t1
JOIN department t2
ON t1._id = t2.id
ORDER BY T1.lvl DESC;
如果是MySql8.0,可以使用WITH RECURSIVE關鍵字實作遞回查詢
WITH RECURSIVE cte AS ( SELECT id, name, parent_id FROM department WHERE id = ? UNION ALL SELECT d.id, d.name, d.parent_id FROM department d JOIN cte ON cte.parent_id = d.id ) SELECT id, name, parent_id FROM cte WHERE id <> ?;
其他
手記系列
記載個人從剛開始作業到現在各種雜談筆記、問題匯總、經驗累積的系列,
手記系列
- 手記系列之一 ----- 關于微信公眾號和小程式的開發流程
- 手記系列之二 ----- 關于IDEA的一些使用方法經驗
- 手記系列之三 ----- 關于使用Nginx的一些使用方法和經驗
- 手記系列之四 ----- 關于使用MySql的經驗
一首很帶感的動漫鋼琴曲~
<iframe frameborder="no" border="0" margin marginheight="0" height="86" src="https://www.cnblogs.com//music.163.com/outchain/player?type=2&id=38574228&auto=0&height=66"></iframe>原創不易,如果感覺不錯,希望給個推薦!您的支持是我寫作的最大動力!
著作權宣告:
作者:虛無境
博客園出處:http://www.cnblogs.com/xuwujing
CSDN出處:http://blog.csdn.net/qazwsxpcm
個人博客出處:https://xuwujing.github.io/
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/554633.html
標籤:MySQL
上一篇:《SQL 必知必會》全決議
下一篇:返回列表