
文章摘要:用一杯星巴克的錢,自己動手2小時的時間,就可以擁有自己訓練的開源大模型,并可以根據不同的訓練資料方向加強各種不同的技能,醫療、編程、炒股、戀愛,讓你的大模型更“懂”你…..來吧,一起嘗試下開源DolphinScheduler加持訓練的開源大模型!
導讀
讓人人都擁有自己的ChatGPT
ChatGPT的誕生無疑讓我們為人工智能的未來充滿期待,它以其精細的表達和強大的語言理解能力,震撼了全球,但是在使用ChatGPT的時候,因為它是SaaS,所以個人隱私泄露,企業資料安全問題是每一個人、每一個企業都擔心的問題,而現在越來越多的開源大模型出現,讓個人/企業擁有自己的大模型成為可能,但是,開源大模型上手、優化、使用要求門檻都比較高,很難讓大家簡單的使用起來,為此,我們借助Apache DolphinScheduler,一鍵式地支持了開源大模型訓練、調優和部署,讓大家可以在極低的成本和技術儲備下,用自己的資料訓練出專屬于自己的大模型,當然,開源大模型的功力距離ChatGPT還有距離,但是經過測驗我們看到7、8成的功力還是有的,而且這是可以根據你的場景和領域知識特殊訓練過的,針對性更強,同時,我們堅信將來隨著技術發展,開源大模型的能力會越來越強,讓用戶體驗越來越好,來吧,我們準備開始,
面向人群——每一個螢屏面前的你
我們的目標是,不僅專業的AI工程師,更是任何對GPT有需求和興趣的人,都能享受到擁有更“懂”自己的模型的樂趣,我們相信,每一個人都有權利和能力去塑造自己的AI助手,而Apache DolphinScheduler可見即所得的作業流程為此提供了可能,順帶介紹下Apache DolphinScheduler,這是一個Star超過1萬個的大資料和AI的調度工具,它是Apache開源基金會旗下的頂級專案,這意味著你可以免費使用它,也可以直接修改代碼而不用擔心任何商業問題,
無論你是業界專家,尋求用專屬于你的資料來訓練模型,還是AI愛好者,想嘗試理解并探索深度學習模型的訓練,我們下面的這個作業流程都將為你提供便捷的服務,它為你解決了復雜的預處理、模型訓練、優化等步驟,只需1-2個小時幾個簡單的操作,加上20小時的運行時間,就可以構建出更“懂”你的ChatGPT大模型:
https://weixin.qq.com/sph/AHo43o
那么,我們一起開啟這個神奇的旅程吧!讓我們把AI的未來帶到每一個人的手中,
僅用三步,構造出更“懂”你的ChatGPT
- 用低成本租用一個擁有3090級別以上的GPU顯卡
- 啟動DolphinScheduler
- 在DolphinScheduler頁面點擊訓練作業流和部署作業流,直接體驗自己的ChatGPT吧
1. 準備一臺3090顯卡的主機
首先需要一個3090的顯卡,如果你自己有臺式機可以直接使用,如果沒有,網上也有很多租用GPU的主機,這里我們以使用AutoDL為例來申請,打開 https://www.autodl.com/home,注冊登錄,后可以在算力市場選擇對應的服務器,根據螢屏中的1,2,3步驟來申請:
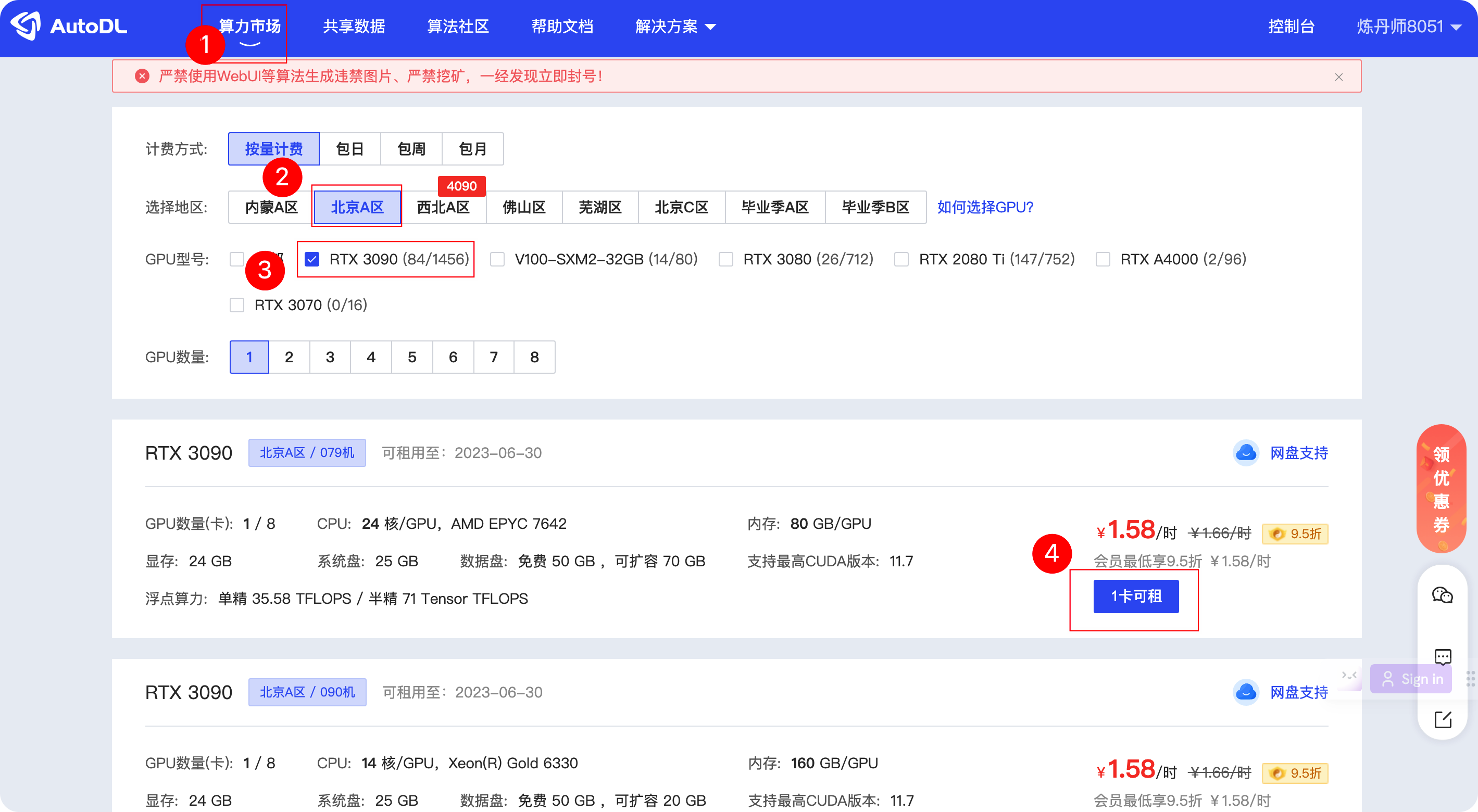
這里,建議選擇性價比較高的RTX3090,經過測驗支持1-2個人在線使用3090就可以了,如果想訓練速度和回應速度更快,可以選擇更強的顯卡,訓練一次大約需要20小時左右,使用測驗大概2-3個小時,預算40元就可以搞定了,
鏡像
點擊社區鏡像,然后在下面紅框出輸入 WhaleOps/dolphinscheduler-llm/dolphinscheduler-llm-0521 之后,即可選擇鏡像,如下如所示,目前只有V1版本的,后面隨著版本更新,有最新可以選擇最新
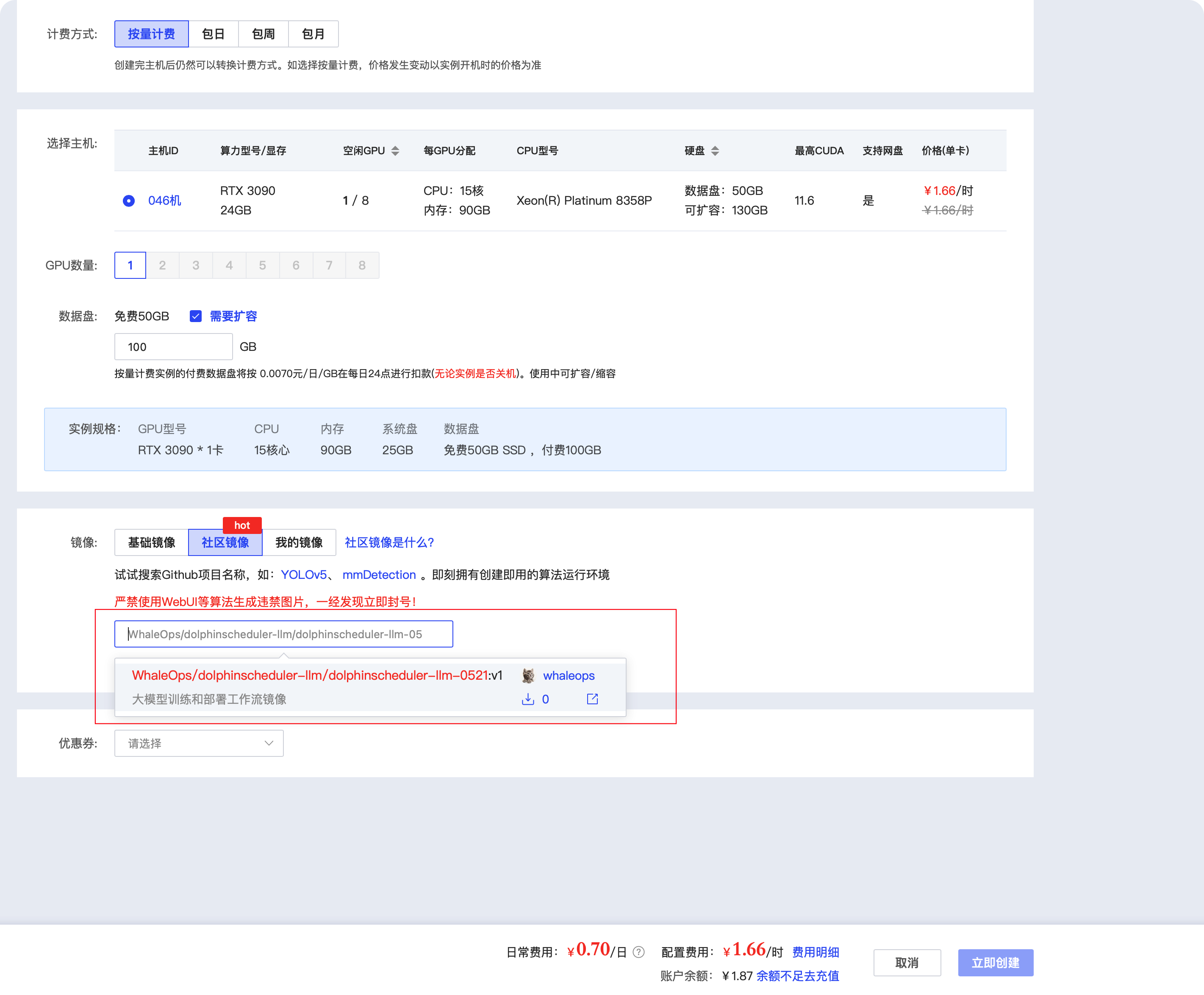
如果需要多次訓練模型,建議硬碟擴容一下,建議100G即可,
創建后,等待下圖所示的進度條創建完成即可,

2. 啟動DolphinScheduler
為了可以在界面上部署除錯自己的開源大模型,需要啟動DolphinScheduler這個軟體,我們要做以下配置作業:
進入服務器
進入服務器的方式有兩種,可以按照自己的習慣進行:
通過JupyterLab頁面登錄(不懂代碼的請進)
點擊如下JupyterLab按鈕
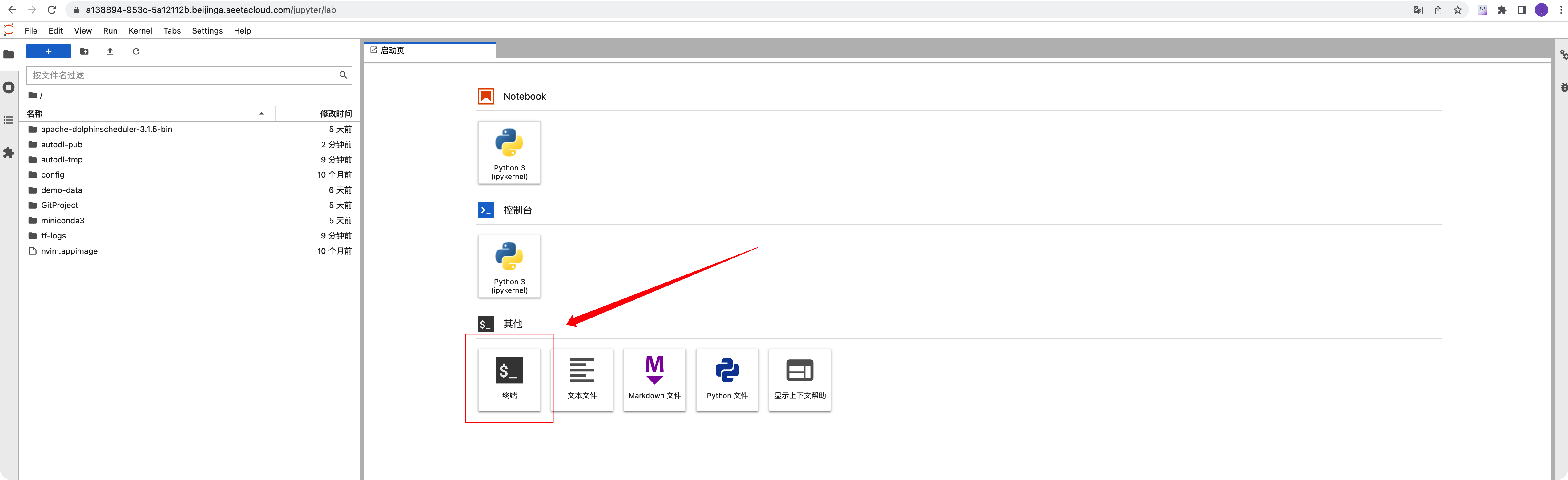
頁面跳轉到JupyterLab,后可以點擊這里的終端進入

通過終端登錄(懂代碼的請進)
我們可以從下圖這個按鈕獲取SSH連接命令

并通過終端鏈接

匯入DolphinScheduler的元資料
在DolphinScheduler中,所有的元資料都存盤在資料庫中,包括作業流的定義,環境配置,租戶等資訊,為了方便大家在使用時能夠啟動DolphinScheduler時候就能夠看到這些作業流,我們可以直接匯入已經做好的作業流定義資料,照螢屏copy進去,
修改匯入MySQL的資料的腳本
通過終端如下命令,進入到以下目錄
cd apache-dolphinscheduler-3.1.5-bin
敲擊命令,vim import_ds_metadata.sh 打開 import_ds_metadata.sh 檔案
檔案內容如下
#!/bin/bash
# 設定變數
# 主機名
HOST="xxx.xxx.xxx.x"
# 用戶名
USERNAME="root"
# 密碼
PASSWORD="xxxx"
# 埠
PORT=3306
# 匯入到的資料庫名
DATABASE="ds315_llm_test"
# SQL 檔案名
SQL_FILE="ds315_llm.sql"
mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD -e "CREATE DATABASE $DATABASE;"
mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD $DATABASE < $SQL_FILE
把 xxx.xxx.xxx.x 和 xxxx 修改成你公網上一個mysql的一個資料庫的資料(可以自己在阿里云、騰訊云申請或者自己安裝一個),然后執行
bash import_ds_metadata.sh
執行后,如果有興趣可在資料庫中看到相應的元資料(可連接mysql查看,不懂代碼的略過),
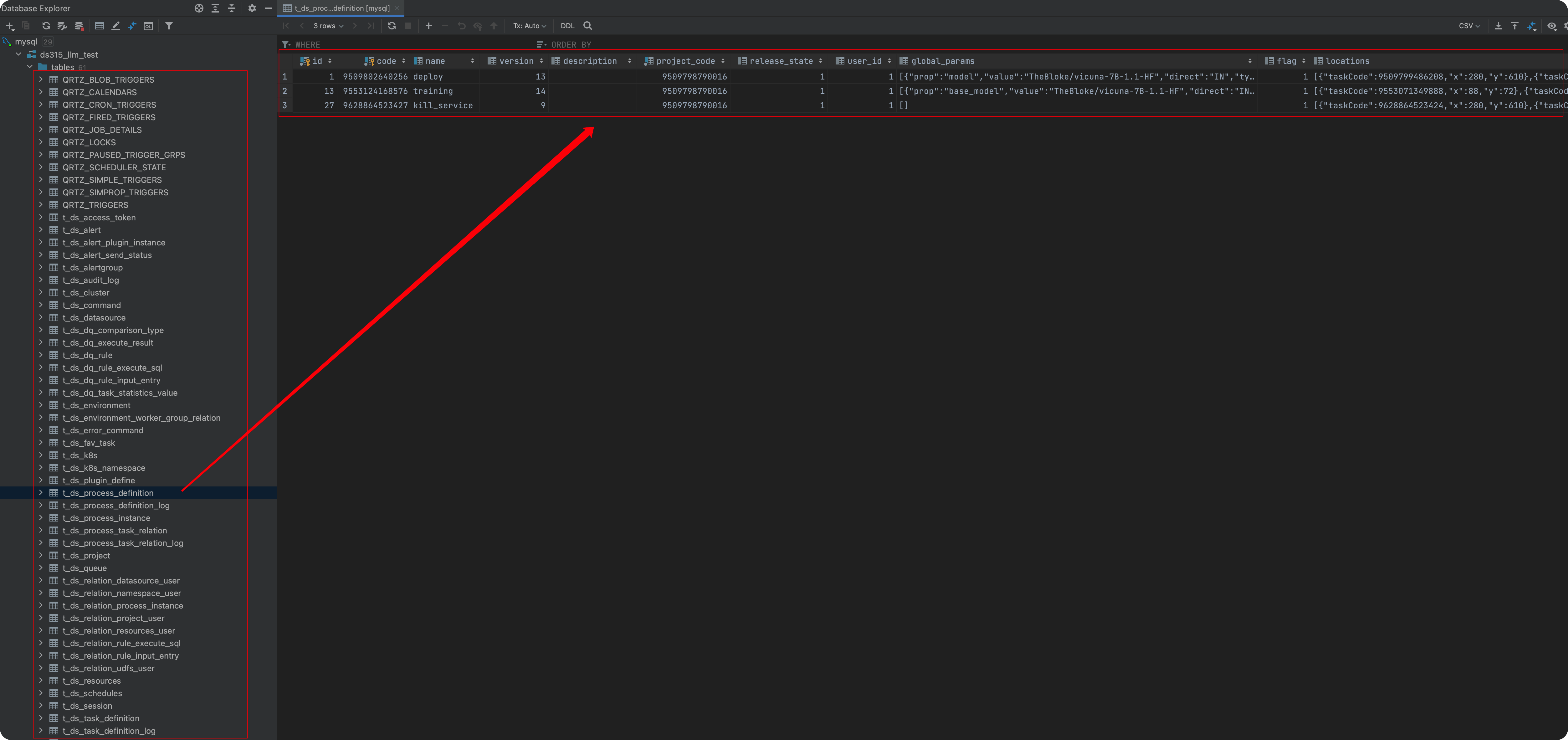
啟動DolphinScheduler
在服務器命令列里,打開下面的檔案,修改配置到DolphinScheduler連接剛才的資料庫
/root/apache-dolphinscheduler-3.1.5-bin/bin/env/dolphinscheduler_env.sh
修改資料庫部分的相關配置,其他部分不用修改,把’HOST’和’PASSWORD’的值改為剛才匯入的資料庫的相關配置值 xxx.xxx.xxx.x 和 xxxx:
......
export DATABASE=mysql
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://HOST:3306/ds315_llm_test?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME="root"
export SPRING_DATASOURCE_PASSWORD="xxxxxx"
......
配置完成后執行(也在這個目錄下 /root/apache-dolphinscheduler-3.1.5-bin )
bash ./bin/dolphinscheduler-daemon.sh start standalone-server
執行完成后,我們可以通過 tail -200f standalone-server/logs/dolphinscheduler-standalone.log 查看日志,這時候,DolphinScheduler就正式啟動了!
啟動服務后,我們可以在AutoDL控制臺中點擊自定義服務(紅框部分)會跳轉到一個網址:
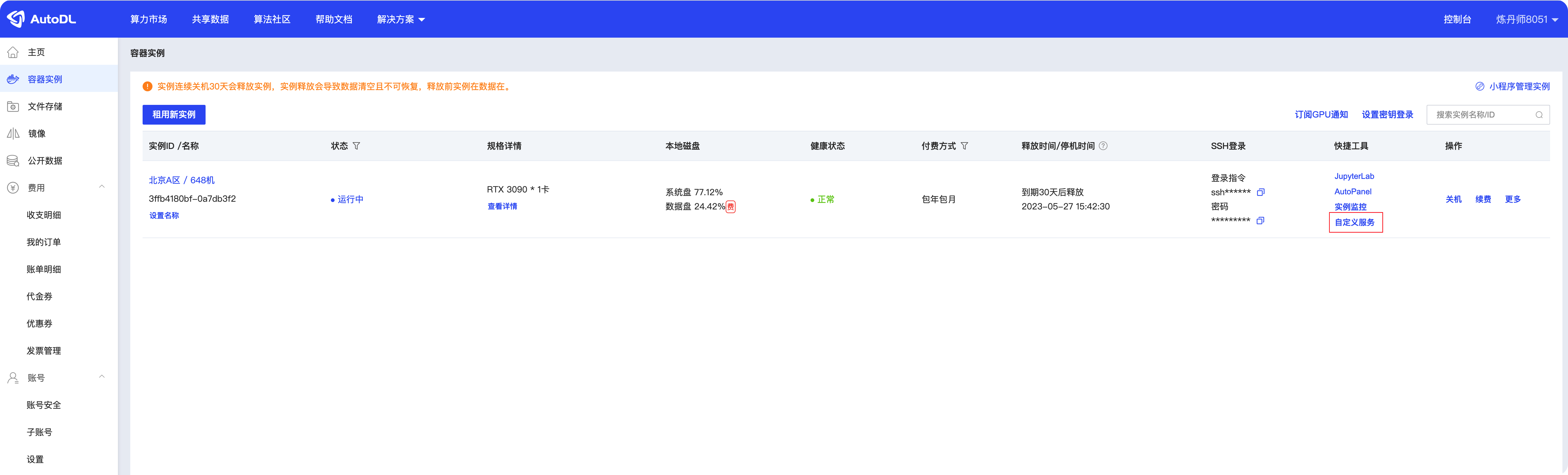
打開網址后發現是404,別著急,我們補充一下url的后綴 /dolphinscheduler/ui 即可

AutoDL模塊開放一個6006的埠,我們將DolphinScheduler的埠配置成6006之后,可以通過上面的入口進入,但是因為跳轉的url補全,所以404,因此我們補全URL即可
登錄用戶名密碼
用戶名: admin
密碼: dolphinscheduler123
登錄后點擊 專案管理,即可看到我們預置的專案 vicuna,再次點擊 vicuna后,我們即可進入該專案,

3. 開源大模型訓練與部署
作業流定義
進入vicuna專案后,點擊作業流定義,我們可以看到三個作業流,Training,Deploy,Kill_Service,下面解釋下這幾個功能的用途和內部選擇大模型和訓練你自己的資料的配置:

我們可以點擊下面的運行按鈕運行對應的作業流
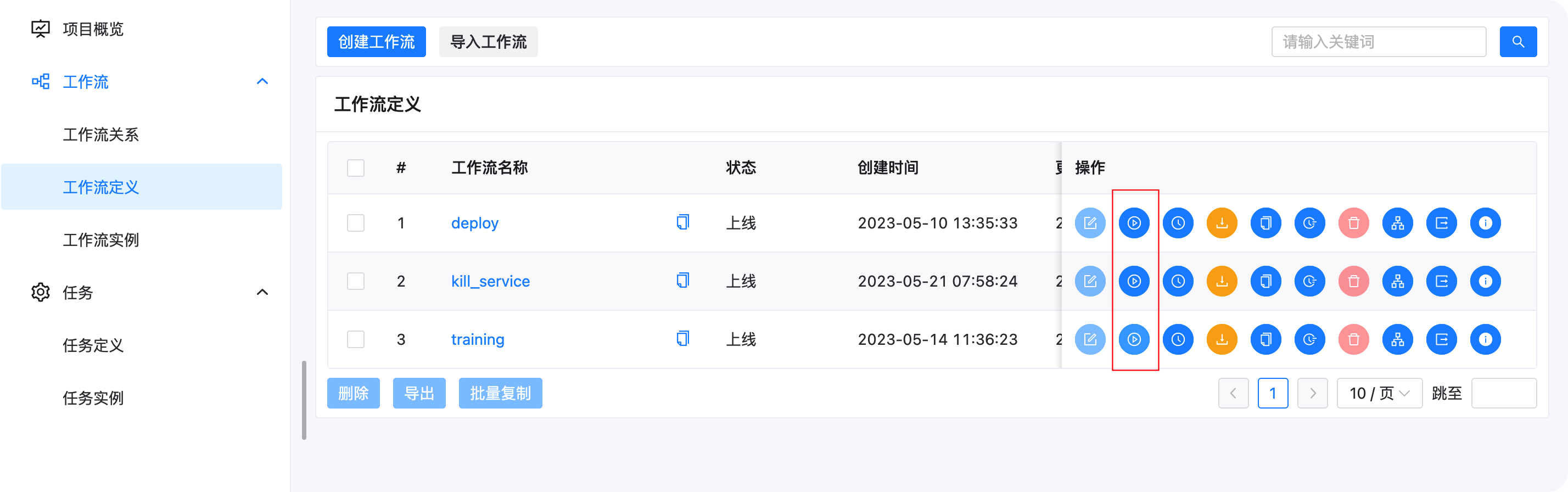
Training
點擊后可以看到作業流的定義,包含兩個,一個是通過lora finetune模型,一個是將訓練出來的模型與基礎模型進行合并,得到最終的模型,
具體的任務定義,可以雙擊對應的圖示查看,
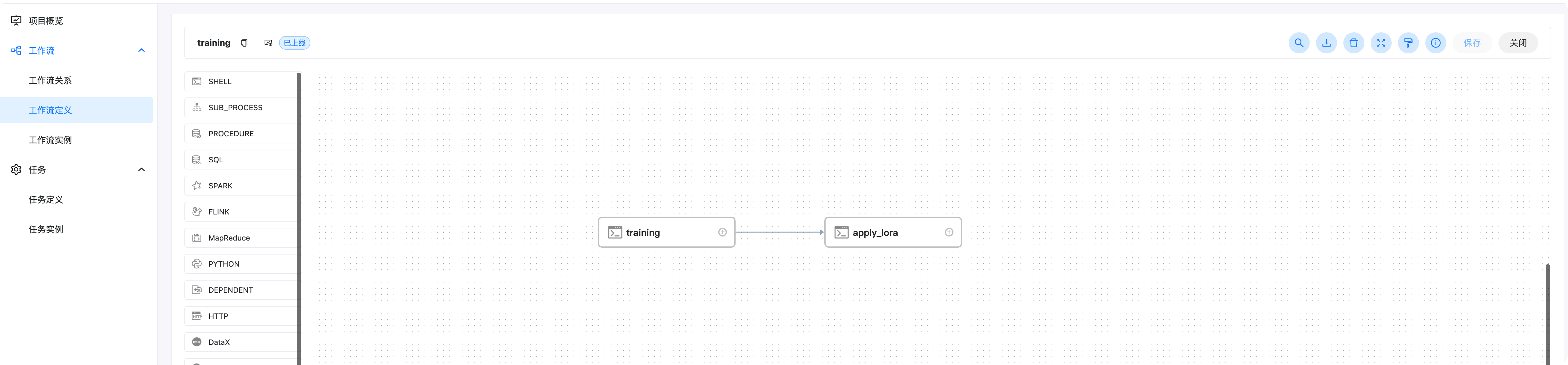
該作業流具有以下引數(點擊運行后彈出)
- base_model: 基礎模型,根據個人情況選擇自行下載,注意開源大模型僅為學習和體驗用途,目前默認為
TheBloke/vicuna-7B-1.1-HF - data_path: 你要訓練的個性化資料和領域資料的路徑,默認為
/root/demo-data/llama_data.json - lora_path: 訓練出來的lora權重的保持路徑
/root/autodl-tmp/vicuna-7b-lora-weight - output_path: 將基礎模型和lora權重合并之后,最終模型的保存路徑,記下來部署的時候需要用到
- num_epochs: 訓練引數,訓練的輪次,可以設為1用于測驗,一般設為3~10即可
- cutoff_len: 文本最大長度,默認1024
- micro_batch_size: batch_size

Deploy
部署大模型的作業流,會先參考kill_service殺死已經部署的模型,在依次啟動 controller,然后添加模型,然后打開gradio網頁服務,
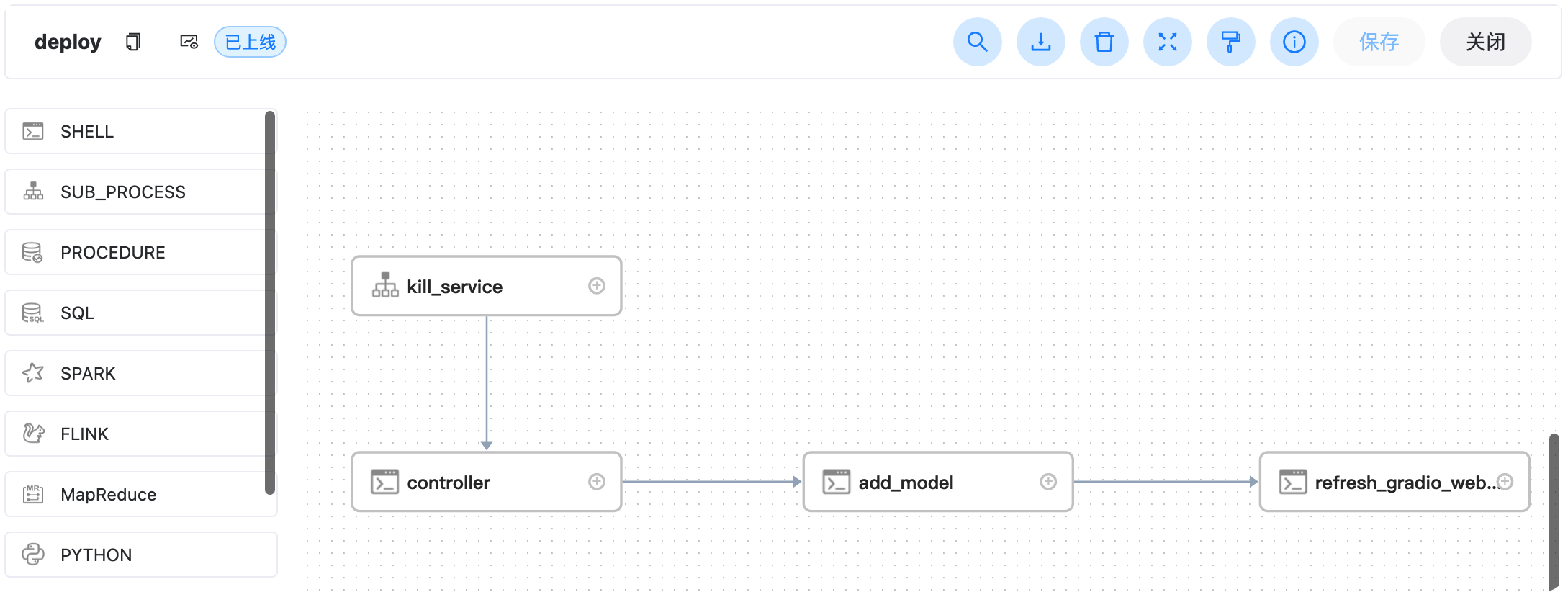
啟動引數如下

- model: 模型路徑,可以為huggingface的模型id,也可以為我們訓練出來的模型地址,即上面training作業流的output_path,默認為
TheBloke/vicuna-7B-1.1-HF使用默認,將直接部署vicuna-7b的模型
Kill_service
這個作業流用于殺死已經部署的模型,釋放顯存,這個作業流沒有引數,直接運行即可,
如果一些情況下,我們要停掉正在部署的服務(如要重新訓練模型,顯存不夠時)我們可以直接執行kill_service作業流,殺死正在部署的服務,
看過經過幾個實體,你的部署就完成了,下面我們實操一下:
大模型操作實體演示
訓練大模型
啟動作業流
可以直接執行training的作業流,選擇默認引數即可
啟動后,可以點擊下圖紅框部分作業流實體,然后點擊對應的作業流實體查看任務執行情況
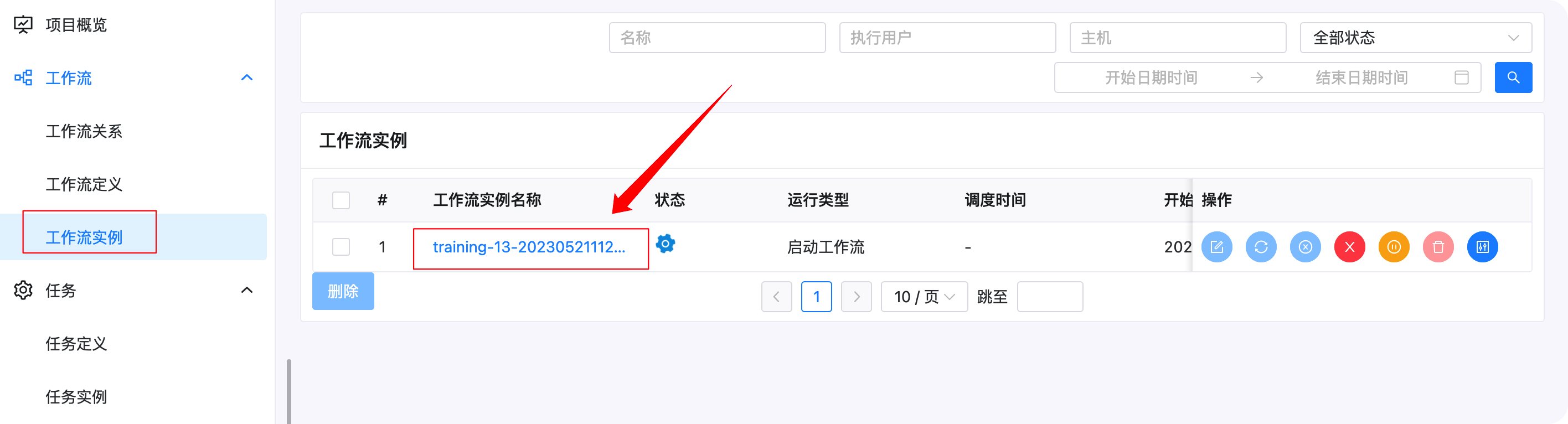
右鍵對應的任務,可以查看對應的日志,如下
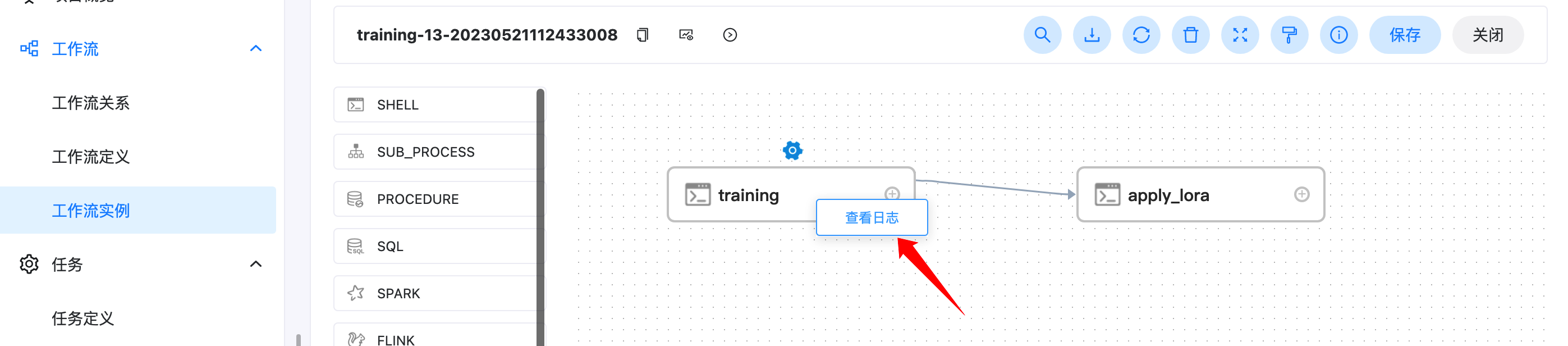
也可以在左邊欄最下面的任務實體欄中,查看對應的任務狀態和日志等資訊
在訓練程序中,也可以通過查看日志查看具體訓練的進度(包括當前的訓練步數,loss指標,剩余時間等),有個進度條一直顯示目前在第幾個step,step = 資料量 * epoch / batchsize

訓練完成后日志如下


更新自己個性化訓練資料
我們默認的資料是在 /root/demo-data/llama_data.json ,當前資料來源于下面華佗,一個使用中文醫學資料finetune的醫學模型,對,我們樣例是訓練一個家庭醫生出來:

如果自己有特定領域的資料,可以指向自己的資料,資料格式如下
一行一個json,欄位含義為
instruction****: 指令,為給模型指令input: 輸入output: 期望模型的輸出
如以下
{"instruction": "計算算數題", "input": "1+1等于幾", "output": "2"}
溫馨提示,可以將 instruction 和 input 合并為 instruction , input為空也可以,
按照格式制作資料,訓練時修改data_path 引數執行自己的資料即可,
注意事項
第一次執行訓練,會從你指定的位置拉取基礎模型,例如TheBloke/vicuna-7B-1.1-HF ,會有下載的程序,稍等下載完成即可,這個模型下載是由用戶指定的,你也可以任選下載其他的開源大模型(注意使用時遵守開源大模型的相關協議),
因為網路問題,第一次執行Training的時候,有可能會下載基礎模型到一半失敗,這個時候可以點擊重跑失敗任務,即可重新繼續訓練,操作如下所示

如果要停止訓練,可以點擊停止按鈕停止訓練,會釋放訓練占用的顯卡顯存

部署作業流
在作業流定義頁面,點擊運行deploy作業流,如下如所示即可部署模型

如果自己沒有訓練出來的模型的話,也可以執行默認引數 TheBloke/vicuna-7B-1.1-HF,部署vicuna-7b的模型,如下圖所示:
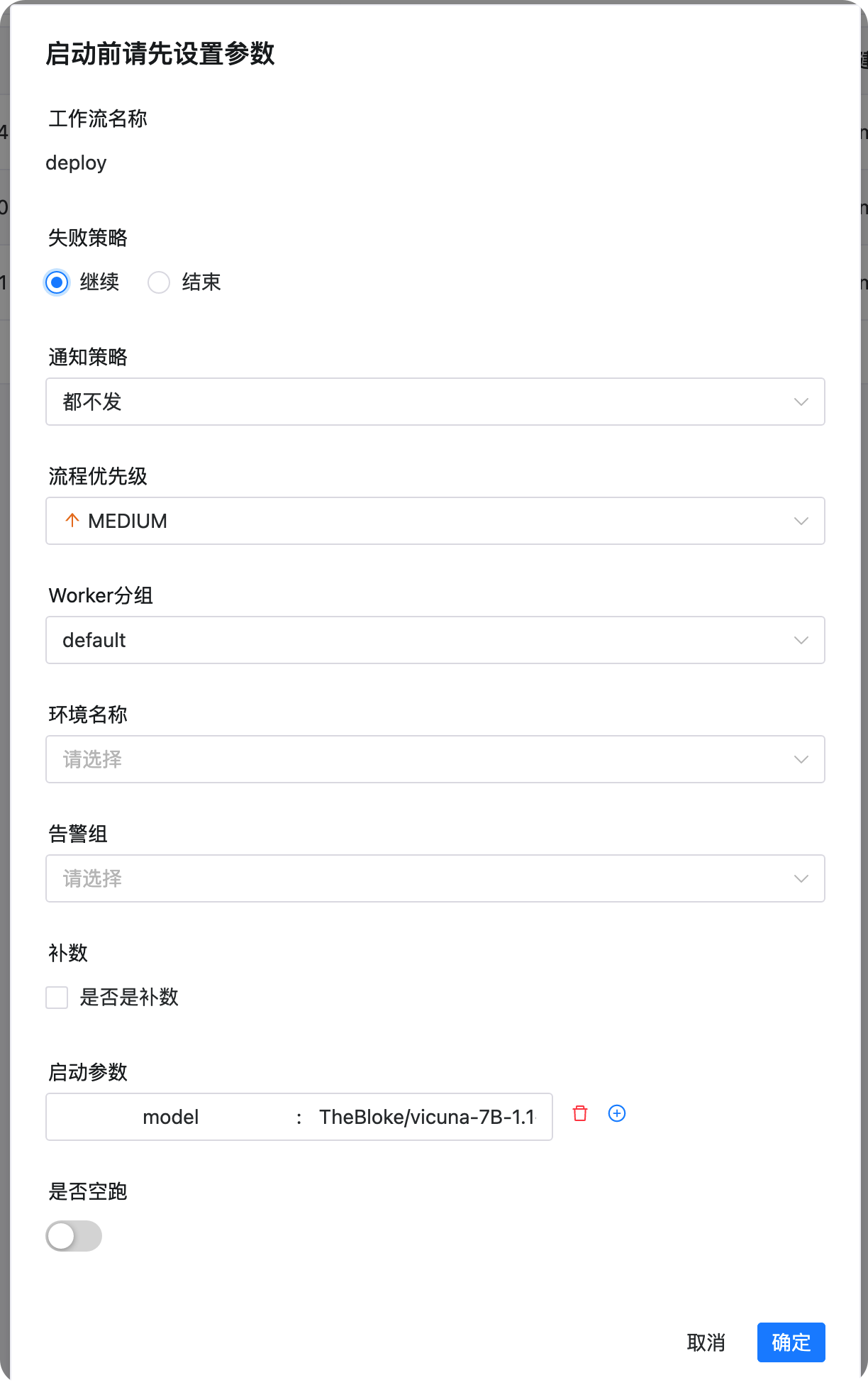
如果在上一步我們進行了模型訓練,我們可以部署我們的模型了,部署之后就可以體驗我們自己的大模型了,啟動引數如下,填入上一步的模型的output_path即可
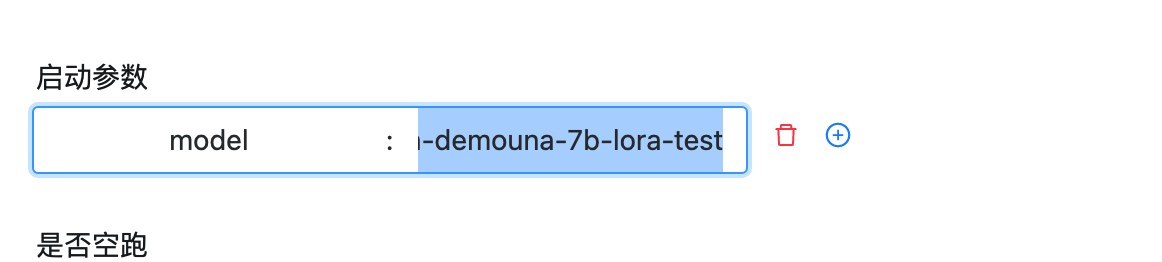
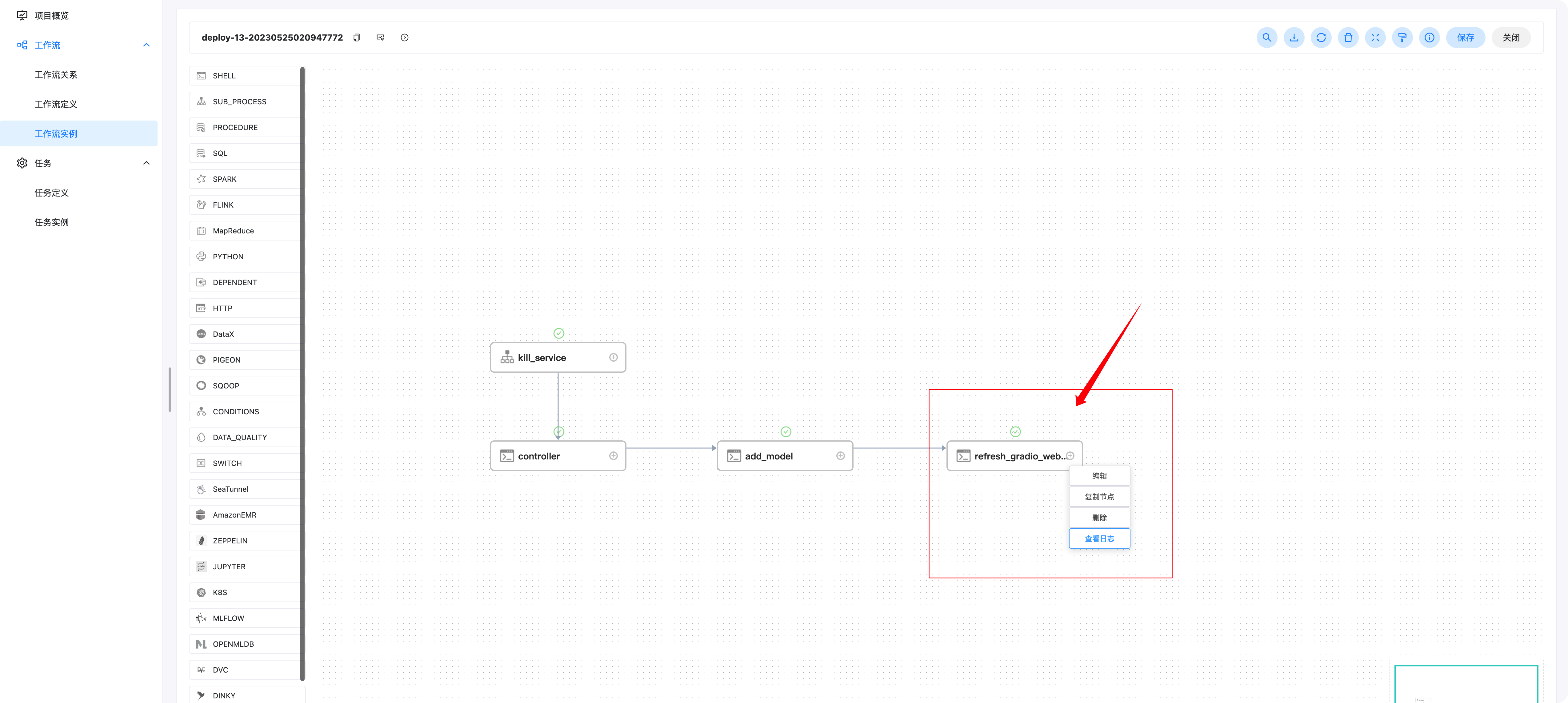
下面我們進入部署的作業流實體,如下圖所示,先點擊作業流實體,然后點擊deploy前綴的作業流實體即可

右鍵點擊refresh_gradio_web_service后可以查看任務日志,找到我們大模型鏈接的位置,操作如下
在日志的最后,我們可以看到一個鏈接,可以公網訪問,如下

這里有兩個鏈接,一個是0.0.0.0:7860 因為AutoDL只開放了6006埠,并且已經用于dolphinscheduler,所以我們暫時無法訪問該介面,我們可以直接訪問下面的鏈接
[https://81c9f6ce11eb3c37a4.gradio.live](https://81c9f6ce11eb3c37a4.gradio.live) 這個鏈接每次部署都會不一樣,因此需要從日志找重新找鏈接,
進入后,即可看到我們的對話頁面
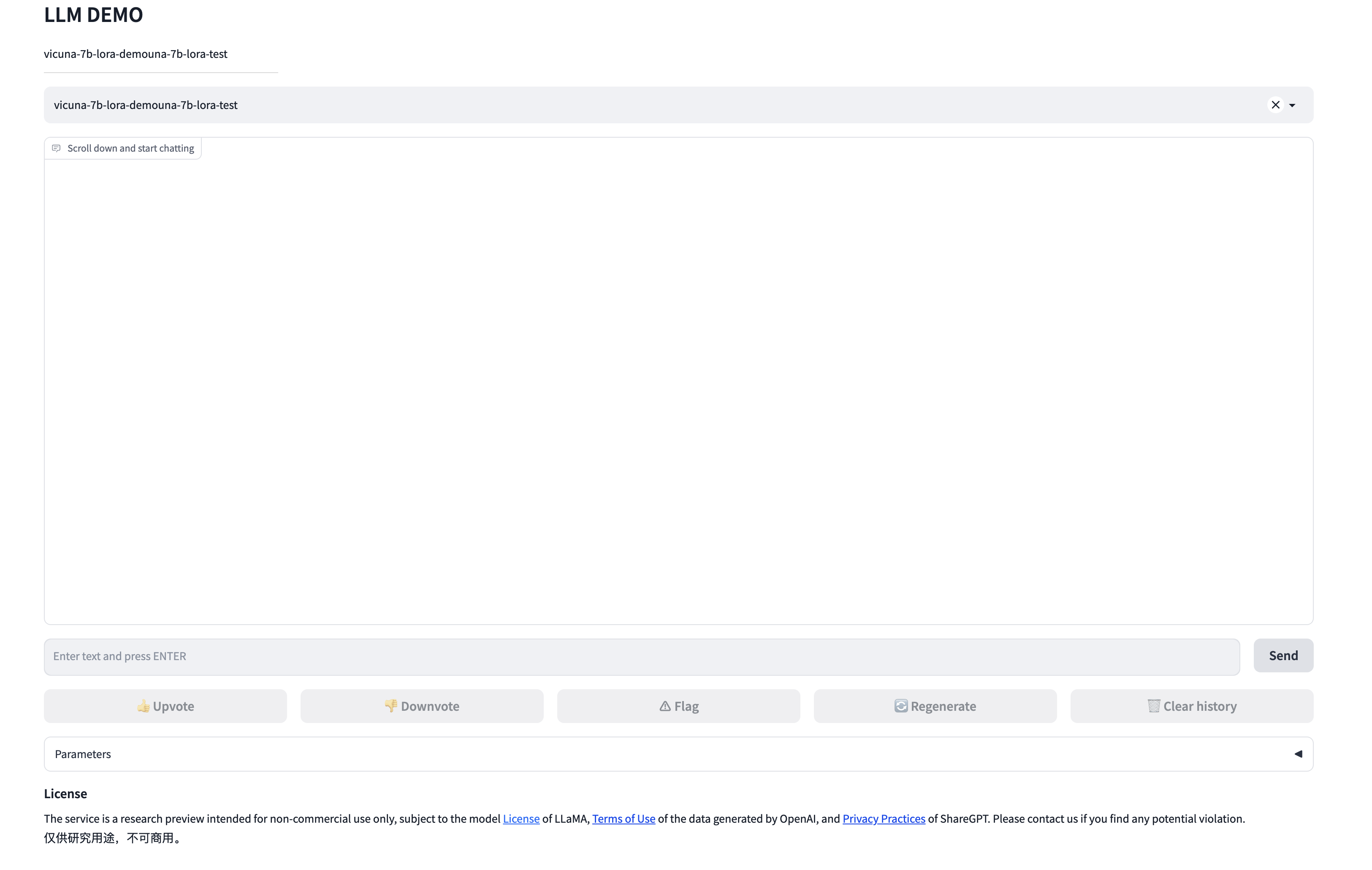

對!就這樣你就擁有了你自己的ChatGPT了!而且它的資料僅服務于你自己!而且!你只花了不到一杯咖啡的錢哦~~
體驗一下,你自己的私有化ChatGPT吧!
總結
在這個以資料和技術驅動的世界中,擁有一個專屬的ChatGPT模型具有無法估量的價值,隨著人工智能和深度學習的日益發展,我們正處在一個可塑造個性化AI助手的時代,而訓練和部署屬于自己的ChatGPT模型,可以幫助我們更好地理解AI,以及它如何改變我們的世界,
總的來說,自訓練和部署ChatGPT模型可以幫助你更好地保護資料安全和隱私、滿足特定的業務需求、節約技術成本,同時通過作業流工具如DolphinScheduler使訓練程序自動化,并更好地遵守當地的法律法規,這都使得自訓練和部署ChatGPT模型成為一個值得考慮的選擇,
附注意事項:
資料安全與隱私
當你使用公共API服務使用ChatGPT時,你可能會對資料的安全性和隱私有所顧慮,這是一個合理的擔憂,因為你的資料可能會在網路中被傳播,通過自己訓練和部署模型,你可以確保你的資料僅在你自己的設備或你租用的服務器上存盤和處理,保障資料安全與隱私,
特定領域知識
對于具有特定業務需求的組織或個人來說,通過訓練自己的ChatGPT模型,可以確保模型具有與業務相關的最新和最相關的知識,無論你的業務領域是什么,一個專門針對你的業務需求訓練的模型都會比通用模型更有價值,
投入成本
使用OpenAI的ChatGPT模型可能會帶來一定的費用,同時如果要自己訓練和部署模型,也需要投入一定的資源和技術成本,40元就可以體驗除錯大模型,如果長期運行建議自己采購3090顯卡,或者年租云端服務器,因此,你需要根據自己的具體情況,權衡利弊,選擇最適合自己的方案,
DolphinScheduler
通過使用Apache DolphinScheduler的作業流,你可以使整個訓練程序自動化,大大降低了技術門檻,即使你不具備深厚的演算法知識,也可以依靠這樣的工具,順利地訓練出自己的模型,支持大模型訓練的同時,它也支持大資料調度、機器學習的調度,幫助你和你的企業非技術背景的員工簡單上手的做好大資料處理、資料準備、模型訓練和模型部署,而且,它是開源且免費的,
開源大模型法律法規約束
DolphinScheduler只是可視化AI作業流,本身不提供任何開源大模型,用戶在使用下載開源大模型時,你需要注意自行選擇不同的開源大模型使用約束條件,本文中的開源大模型所舉的例子僅供個人學習體驗使用,使用大模型時需要注意遵守開源大模型開源協議合規性,同時,不同國家都不同嚴格的資料存盤和處理規定,在使用大模型時,你必須對模型進行定制和調整,以適應你所在地的具體法律法規和政策,這可能包括對模型輸出的內容進行特定的過濾等,以滿足當地的隱私和敏感資訊處理規定,
本文由 白鯨開源 提供發布支持!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/553890.html
標籤:大數據
下一篇:返回列表