這段時間,我們對產品本身以及客戶反饋的一些問題進行了持續的更新和優化,包括對離線平臺資料同步功能的更新,資料資產平臺血緣問題的優化等,力求滿足不同行業用戶的更多需求,為用戶帶來極致的產品使用體驗,
以下為袋鼠云產品功能更新報告第五期內容,更多探索,請繼續閱讀,
離線開發平臺
1.支持作業流引數
背景:很多業務場景下一個作業流中需要有一些能生效于整個作業流的引數,統一配置其下所有子節點通用,
新增功能說明:作業流父任務中支持創建作業流層級引數,作業流引數在作業流范圍內生效,作業流下子節點支持通過${引數名稱}的方式來參考該作業流引數,


2.支持專案級引數
背景:
目前離線已支持的引數型別有以下幾種:
? 全域引數-作用于整個數堆疊平臺
? 自定義引數-作用于單個離線任務/作業流子節點
? 任務上下游引數-作用于引入此引數的下游任務
? 作業流引數-作用于單個作業流任務
增加的專案級引數,作用于當前專案之內的所有任務,既不影響別的專案的任務,也可實作專案內某些業務配置批量修改的效果,
新增功能說明:支持在專案的「專案管理->專案引數」中配置專案引數,配置完成后,該專案下的任務都可以進行參考,在任務中可以通過${引數名稱}的方式參考專案引數,


3.系結的專案支持解綁
背景:當前專案系結為非可逆操作,一個專案一旦和另一個專案產生系結后無法解綁也不支持洗掉,但部分已經系結的專案因業務原因可能需要換目標專案系結,或者不再使用需要洗掉,
新增功能說明:可在測驗專案的「專案設定-基本資訊」中操作解綁生產專案,此操作不可逆,解除生產測驗專案系結后,資料源映射、資源組映射、發布至目標專案功能會受到影響,回退至系結前狀態,可按正常邏輯洗掉,


4.補資料支持對各型別引數進行一次性賦值
背景:補資料時可能會存在需要對引數值進行臨時替換的情況,例如跑歷史日期的資料時,補資料的時間引數范圍需要變更,
新增功能說明:在「運維中心-周期任務管理-任務補資料」中進行補資料引數重新賦值操作,補資料實際跑任務的引數值會被補資料時重新賦值的引數值替換,

5.臨時運行可查看運行歷史
背景:周期任務、手動任務提交到調度運行時,都會產生實體,記錄運行狀態和運行日志等資訊,但是周期任務、臨時查詢和手動任務在臨時運行時不存在運行記錄,用戶無法查看歷史臨時運行的運行狀態和運行日志等資訊,導致一些重要的操作無法追蹤,
新增功能說明:在資料開發頁面最左側功能模塊串列中,新增了「運行歷史」功能,在「運行歷史」中,可查看歷史近30天(可自定義)臨時運行的 SQL、日志等資訊,
6.告警接受人支持填寫其他引數
背景:部分客戶希望一些非數堆疊用戶(比如合作方)也能收到任務的告警資訊,而目前平臺支持選的告警接收人范圍為當前專案下的用戶,期望離線側告警配置時能靈活添加一些自定義值:可以是手機號、郵箱、用戶名等資訊,客戶通過自定義告警通道中上傳的 jar 包自定義決議獲取值的內容,再通過自己的系統給決議出的聯系人發送告警,
新增功能說明:在創建告警規則時,支持填寫外部聯系人資訊,通過英文逗號分割,(自定義告警通道中上傳的 jar 需要支持決議)

7.資料同步的讀寫并行度支持分開設定
背景:由于資料同步源端與目標端的資料庫存在資料庫本身性能等因素的影響,讀和寫的速率往往是不一致的,例如讀的速率是5M/s,寫的速率只有2M/s,讀和寫統一用一個并行度控制實際不能達到同步速率的最大優化,反而可能帶來問題,
新增功能說明:在資料同步的通道控制中原“作業并發數”改為“讀取并發數”和“寫入并發數”,兩個引數單獨配置互不影響,用戶可靈活調整讓同步效率最大化,并發數調整范圍上限改為100,

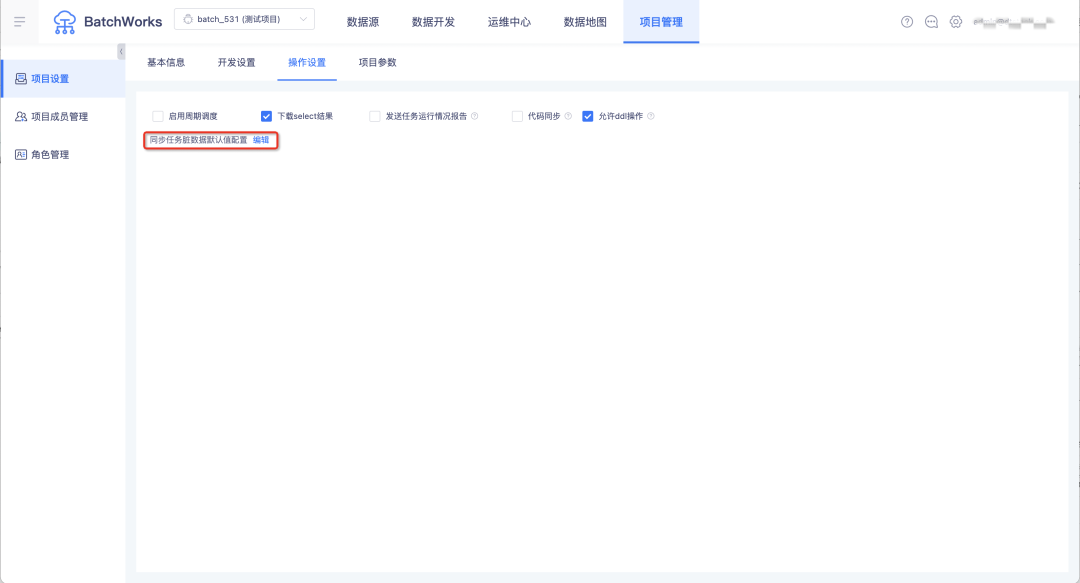
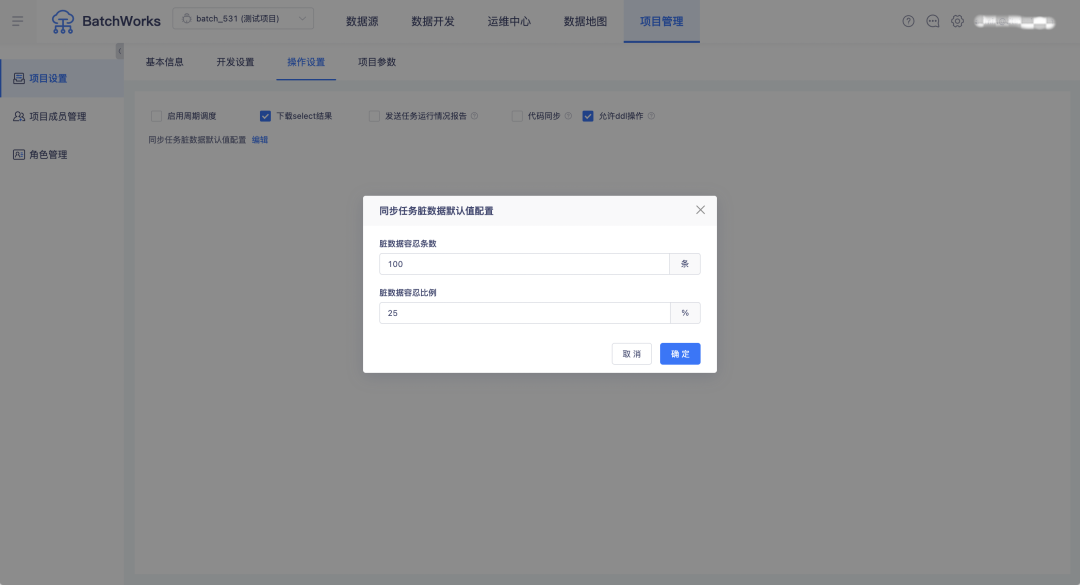
8.臟資料容忍條數支持按專案設定默認值
新增功能說明
背景:同步任務中的臟資料默認容忍條數原本固定是100,部分客戶實際接受的容忍度是0,導致每配置一個同步任務就需要改一下臟資料容忍條數的設定值,使用不便,
新增功能說明:在離線「專案管理->專案設定->操作設定」中,支持設定資料同步任務臟資料默認容忍條數和臟資料默認容忍比例,配置完成后,新建資料同步任務在通道控制模塊會展示默認值,

9.資料同步讀取 hive 表時可選擇讀取多個磁區的資料
背景:資料同步讀取 hive 表時目前僅支持選擇一個磁區讀取,部分客戶場景下需要把多個磁區的資料讀取出來寫入目標表,
新增功能說明:讀 hive 表時磁區可以用 and 作為連接符篩選多個磁區進行資料讀取,

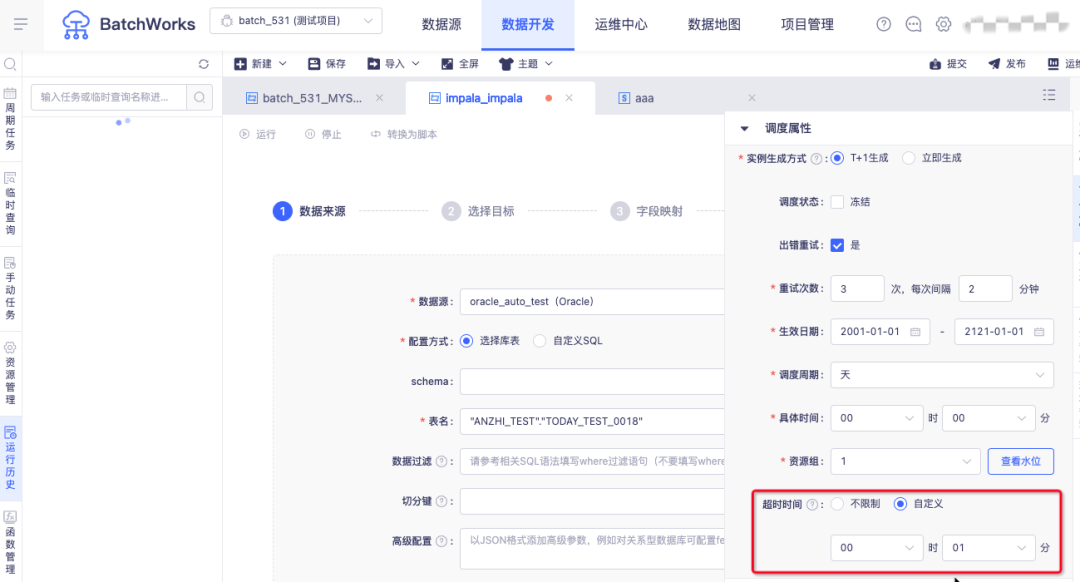
10.任務運行超時中斷
背景:目前所有任務一旦開始運行,無論運行多久平臺都不會自動殺死,導致部分例外任務運行時間長,占用大量資源,
新增功能說明:所有任務在調度屬性處增加了超時時間的配置項,默認不限制,可選擇定義超時時間,運行超時后平臺會自動將其殺死,
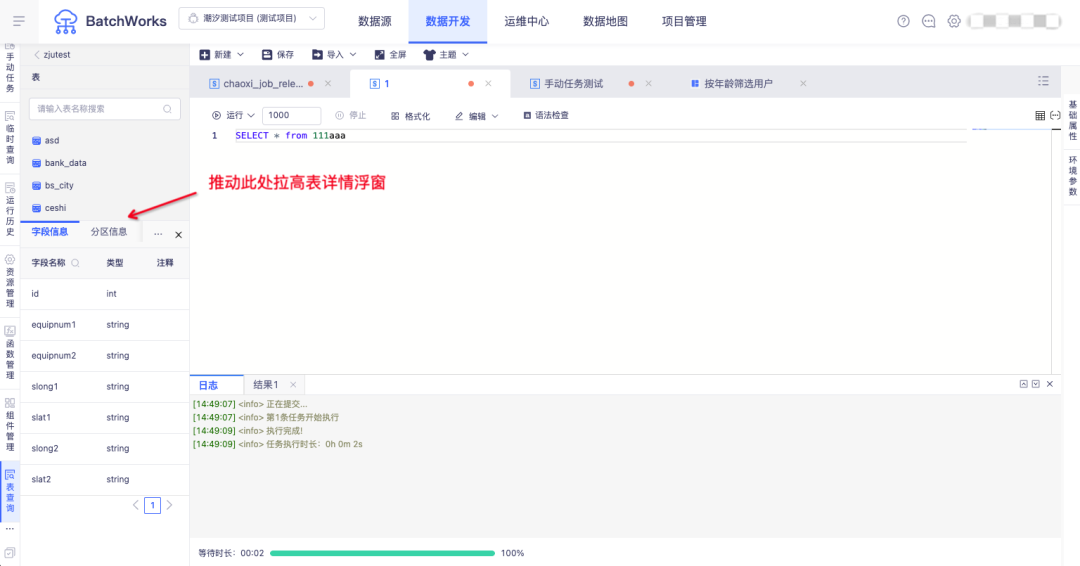
11.表管理的表查看互動優化
背景:點擊表管理中某張表的欄位、磁區等詳細資訊的區域較小,不方便查看,
新增功能說明:對該區域可手動進行拉高,
12.hive 資料同步的磁區支持選擇范圍
當 hive 類資料源作為資料同步的來源時,磁區支持識別邏輯運算子“>”“=”“<”“and”,例如“pt>=202211150016 and pt<=202211200016 ”,即代表讀取范圍在此之間的所有磁區,
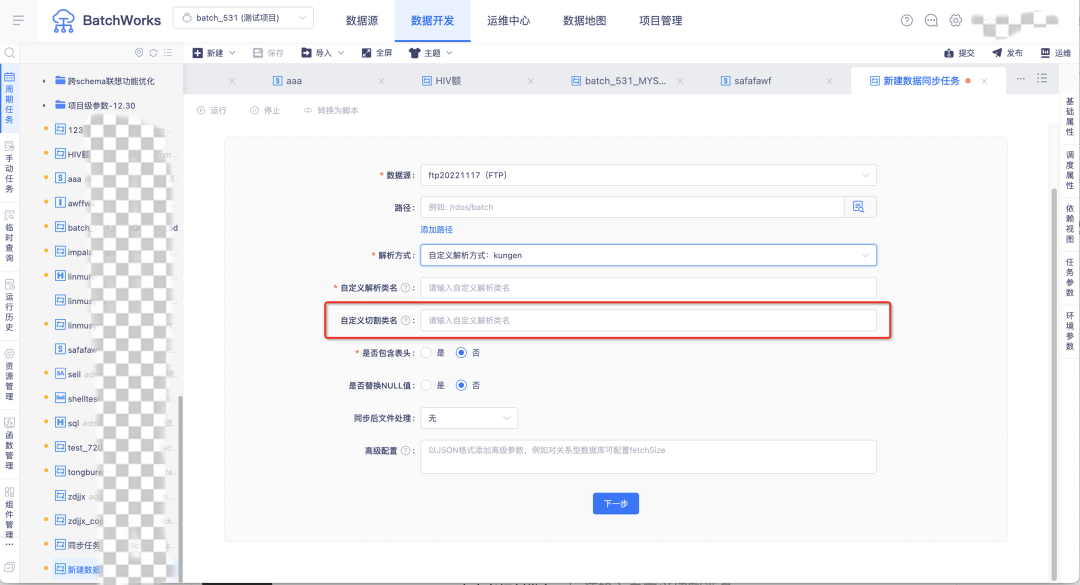
13.FTP 大檔案拆分支持自定義決議檔案的拆分
在用戶決議方式選擇自定義決議方式時,支持用戶上傳自定義 jar 包對 FTP 中的檔案進行切割拆分同步,
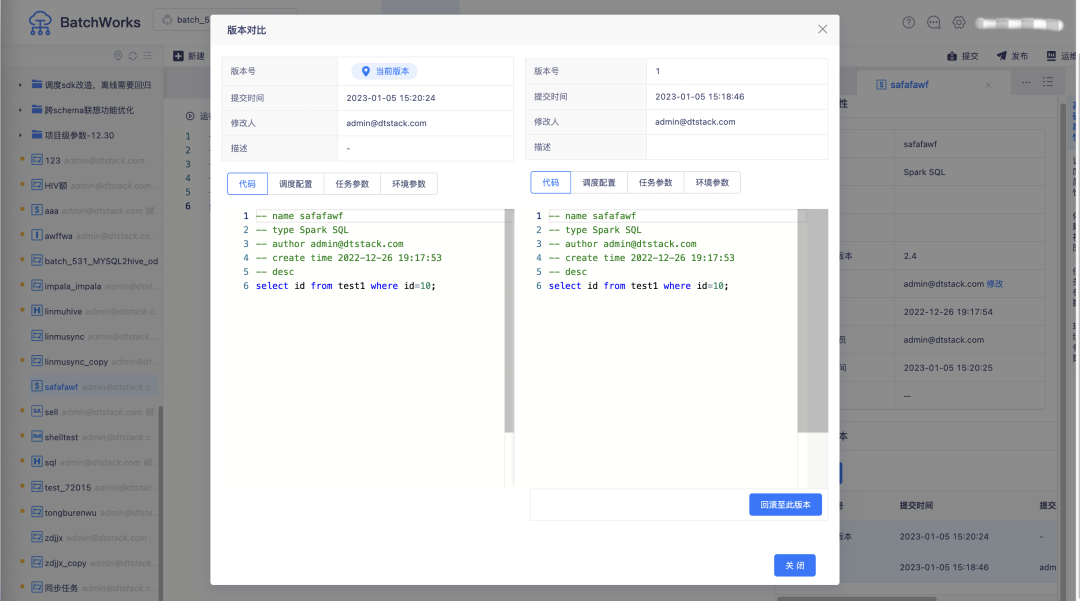
14.版本對比功能優化
· 歷史版本支持查看近50條版本記錄
· 版本對比功能互動調整
? 支持歷史版本間對比

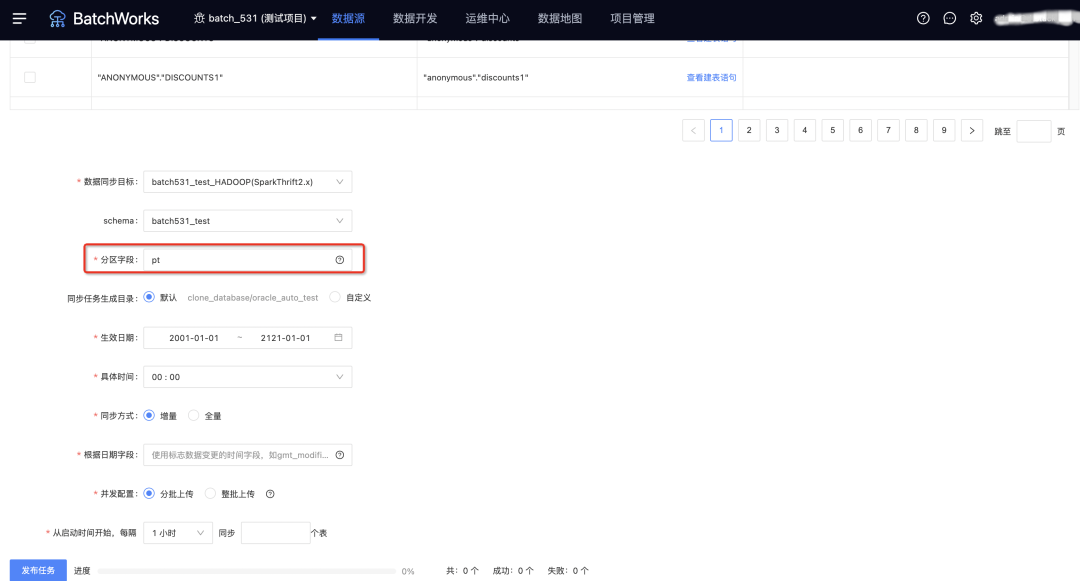
15.整庫同步寫 hive 時支持對磁區表指定磁區名稱
當整庫同步選中 hive 類的資料同步目標時,可以指定磁區欄位的名稱,
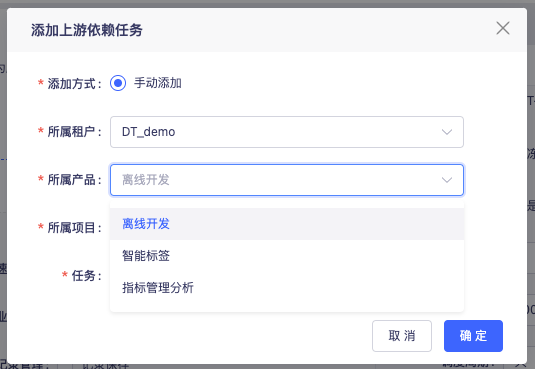
16.離線支持配置指標任務作為上游依賴
目前離線已經支持的跨產品任務依賴包括:質量任務(關聯)、標簽任務,加上指標任務后整個數堆疊的所有離線任務就可實作相互的依賴了,
17.臟資料管理概覽圖顯示具體時間

18.通過右鍵快捷鍵可查看任務日志
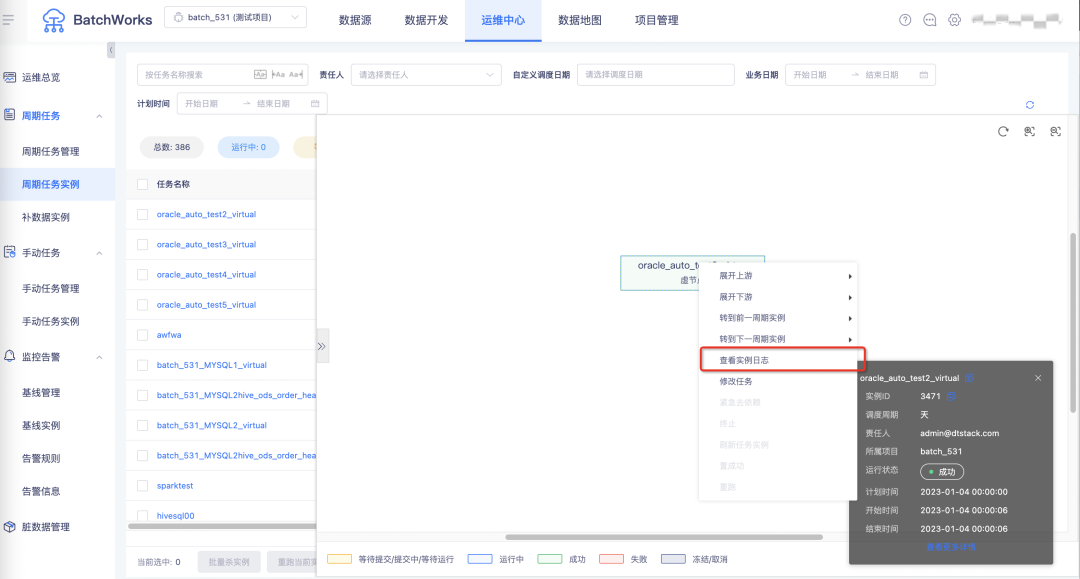
19.任務執行進度優化
執行進度前展示等待時長,

20.其他優化項
· vertica 支持向導模式資料同步
· 任務下線后,支持查看任務實體
· RDB 任務支持在任務間及作業流里的引數傳遞
· 資料同步任務在創建發布包時被選中時支持關聯到表:資料同步任務目標端一鍵生成的目標表,支持關聯至發布包中
· SQL 陳述句支持:Desc database、Show database、Create database、Drop database、Show tables、Create table、Desc table、Alter table、Drop table、Creat function
· 表聯想功能優化:spark sql、hive sql、gp sql 撰寫 SQL 代碼時,支持表聯想功能,聯想范圍:離線對接和創建 schema 下的表
· 洗掉任務、資源等內容時,提示內容名稱
實時開發平臺
1.【資料還原】支持一體化任務
背景:一個任務即可完成存量資料的同步,并無縫銜接增量日志的采集還原,在資料同步領域實作批流一體,常用于需要做實時備份的資料遷移場景,
比如在金融領域,業務庫出于穩定性考慮,無法直接面向各種上層應用提供資料查詢服務,這時候就可以將業務資料實時遷移至外部資料庫,由外部資料庫再統一對外提供資料支撐,
新增功能說明:支持存量資料同步+增量日志還原的一體化任務,支持 MySQL—>MySQL/Oracle,在創建實時采集任務時,開啟【資料還原】,還原范圍選擇【全量+增量資料】,

2.【資料還原】支持采集 Kafka 資料還原至下游
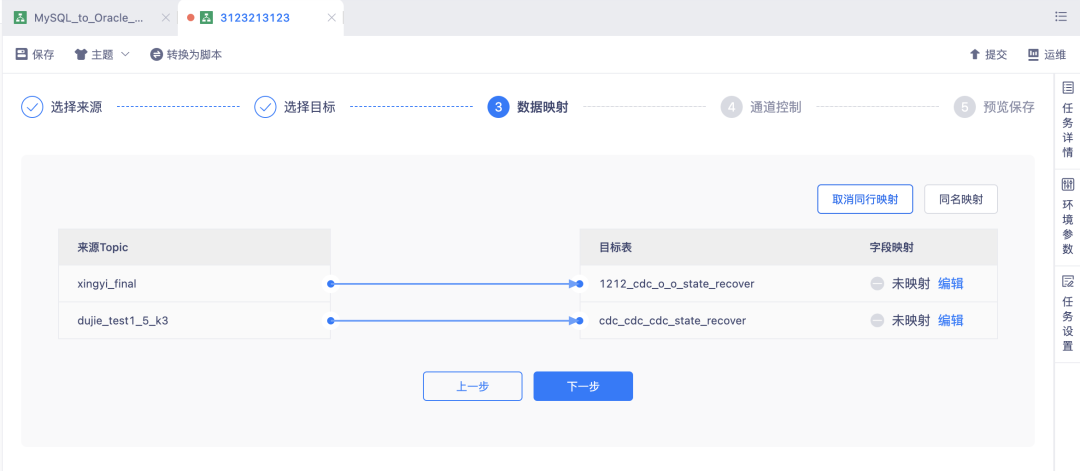
背景:當用戶對 Kafka 資料沒有實時加工的需求,只希望能將 kafka 訊息還原至下游資料庫對外提供資料服務時,可以通過實時采集配置化的方式,批量完整此類采集還原任務,不需要一個個的維護 FlinkSQL 任務,
新增功能說明:支持將 Kafka(OGG格式)資料,采集還原至下游 MySQL/Hyperbase/Kafka 表,在創建實時采集任務時,源表批量選擇 Kafka Topic,目標表批量選擇 MySQL 表,再完成表映射、欄位映射,
3.任務熱更新
背景:目前對于編輯修改實時任務的場景,操作比較繁瑣,需要在【資料開發】頁面完成編輯后,先到【任務運維】處停止任務,然后回到【資料開發】頁面提交修改后的任務,最后再回到【任務運維】頁面向 YARN 提交任務,
新增功能說明:當前更新后,支持修改「環境引數」、「任務設定」后,在資料開發頁面提交任務后,任務運維處自動執行「停止-提交-續跑」操作,
4.資料源
新增 ArgoDB、Vastbase、HUAWEI ES作為 FlinkSQL 的維表/結果表,均支持向導模式,
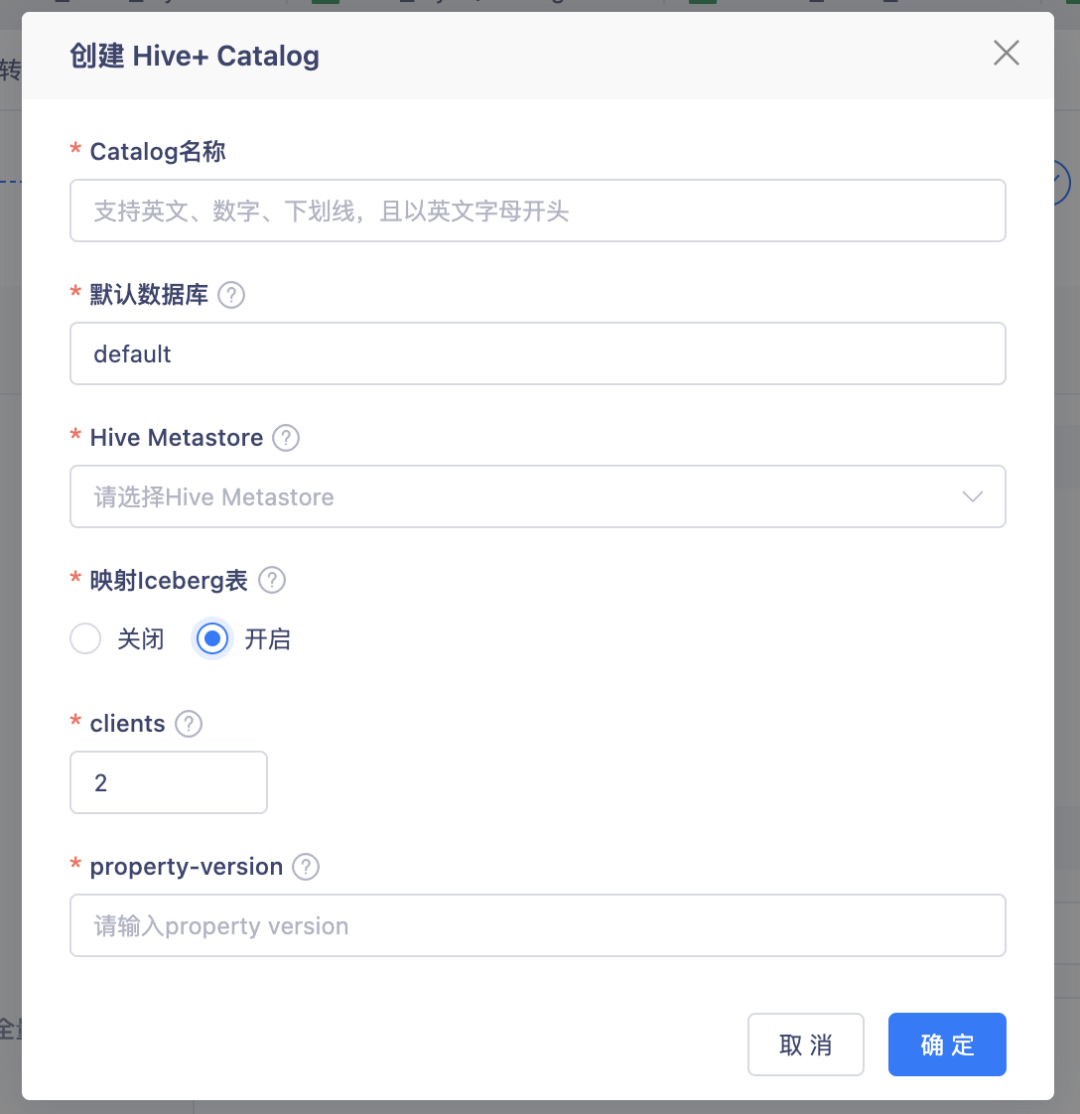
5.【表管理】合并原有的 Hive Catalog 和 Iceberg Catalog
背景:這兩類 Catalog,實際都是依賴 Hive Metastore 做元資料存盤,Iceberg Catalog 只需要在 Hive Catalog 基礎上,開啟額外的一些配置項即可,所以將這兩類 Catalog 做了合并,
體驗優化說明:創建 Hive Catalog,可以選擇是否開啟 Iceberg 表映射,如果開啟了,在這個 Catalog 下創建 Flink Table 時,只支持映射 Iceberg 表,
6.【任務運維】優化任務停止時的狀態說明
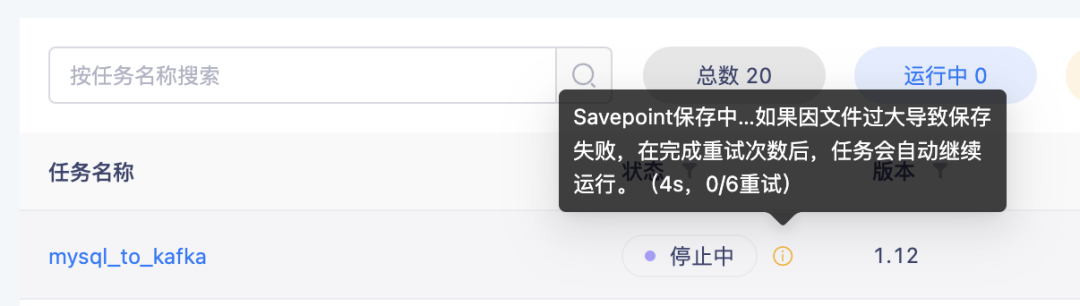
背景:在保存 Savepoint 并停止任務時,因為 Savepoint 檔案可能會比較大,保存時間需要比較久,但是狀態一直顯示「停止中」,用戶無法感知停止流程,并且如果保存失敗了,任務依然會一直顯示「停止中」,任務狀態不符合實際情況,
體驗優化說明:在保存 Savepoint 并停止任務時,「停止中」狀態會顯示當前持續時間,以及保存失敗的重試次數,當最終保存失敗時(代表任務停止失敗),此時任務會自動恢復至「運行中」狀態,
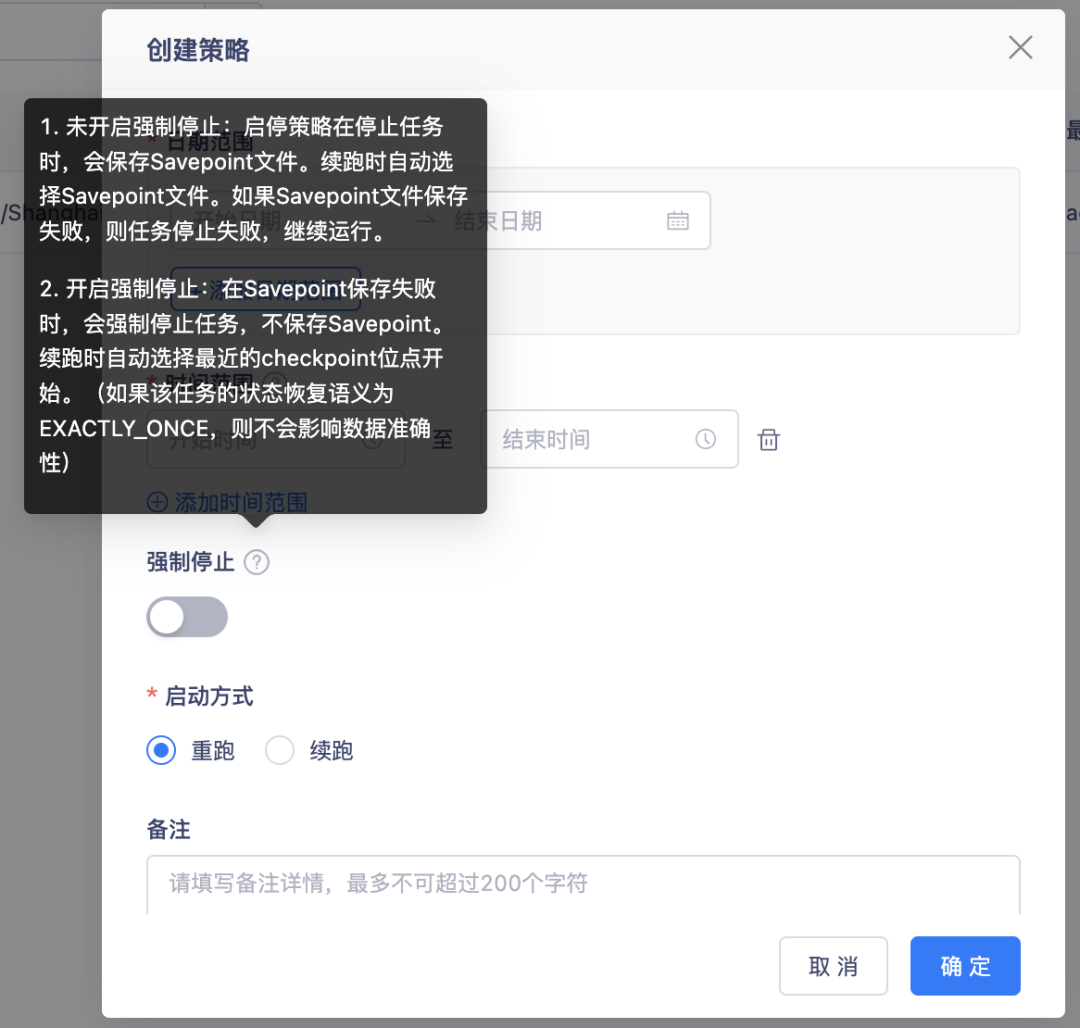
7.【啟停策略】創建啟停策略時,支持強制停止配置項
背景:目前創建的啟停策略,默認都是執行保存 savepoint 的邏輯,但是當保存失敗時,任務不允許自動做出選擇幫用戶丟棄 savepoint 進行強制停止,所以我們將這個的選擇權,放給了用戶,
體驗優化說明:創建啟停策略,有個強制停止的開關,
8.血緣決議
支持過濾鏈路節點型別,支持全屏查看,支持搜索,任務節點支持查看狀態,

9.系統函式
更新內置的系統函式,同步 Flink 官方內容,
10.其他優化項
· 資料還原:開啟資料還原的實時采集任務,支持生成 Checkpoint 并續跑
· UI5.0:更新 UI5.0 前端樣式
資料資產平臺
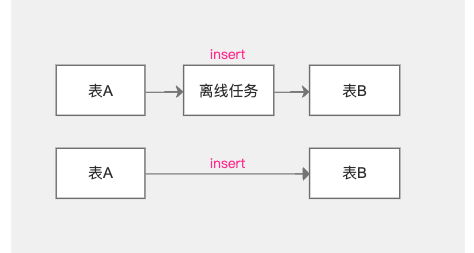
1.【血緣問題】冗余血緣移除
背景:當前現狀當存在血緣關系時,會生成兩條血緣關系,此問題需要解決,否則全鏈路會產生非常多的冗余血緣,
體驗優化說明:只展示一條血緣,
2.【血緣問題】關鍵字支持
· 當表發生 delete、drop、trancate 資料清空時,表與表之間、表與任務之間的血緣關系洗掉
· 當任務下線、洗掉時,表與表之間血緣依舊存在,表與任務之間的血緣關系洗掉
3.【血緣問題】重合資料源
背景:標簽指標對接的是 trino 引擎,離線對接的是 sparkthrift,如果不解決唯一性問題,無法串聯全鏈路血緣,
體驗優化說明:不同鏈路間的血緣不相互影響,但是匯總成同一鏈路展示,

4.【血緣問題】資料源唯一性區分
· 不同的引擎讀取同一張控制臺的 hive 表(如sparkthrift、trino)
· 資料源中心建立的不同的資料源,其實是同一個資料庫
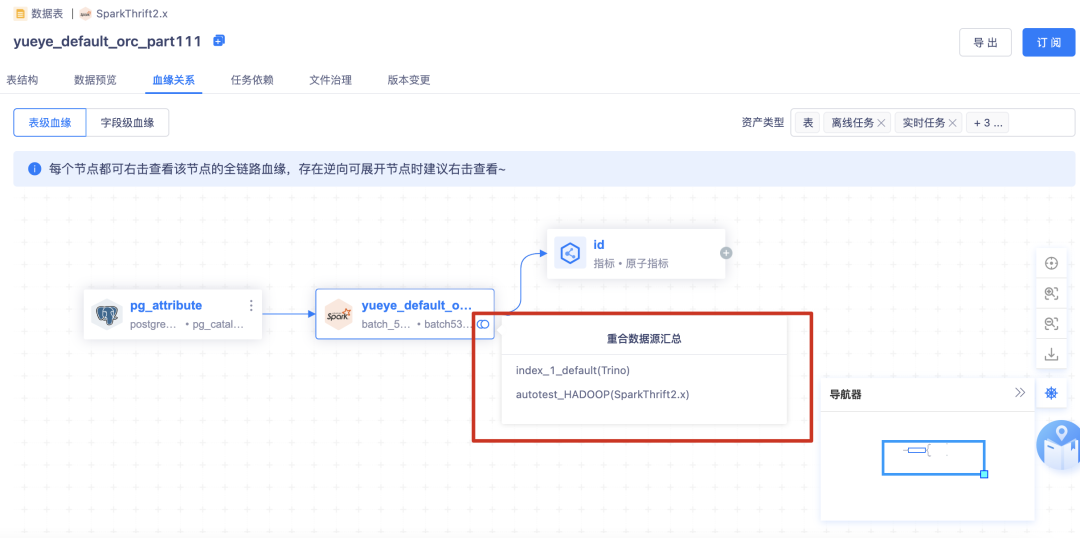
5.【全鏈路血緣】表→指標
資料資產平臺已初步實作數堆疊內部全鏈路血緣關系的打通,包括表、實時任務、離線任務、API、指標、標簽,
表→指標:
? 根據指標平臺的【指標的生成】記錄【表→指標】之間的血緣關系
? 指標的生成包括【向導模式】、【腳本模式】
? 指標平臺如果有變動,比如洗掉、下線了某個指標,資產平臺需要更新血緣視圖
? 支持指標的欄位血緣決議

6.【全鏈路血緣】表→標簽
· 根據標簽平臺的【標簽的生成】記錄【表→標簽】之間的血緣關系
· 標簽通過物體和關系模型創建,物體中需要關聯主表和輔表,關系模型中有事實表和維表,并且關系模型可存盤為實際的物理表,因此血緣鏈路包括資料表、標簽
· 標簽平臺如果有變動,比如洗掉、下線了某個標簽,資產平臺需要更新血緣視圖
· 支持標簽的欄位血緣決議

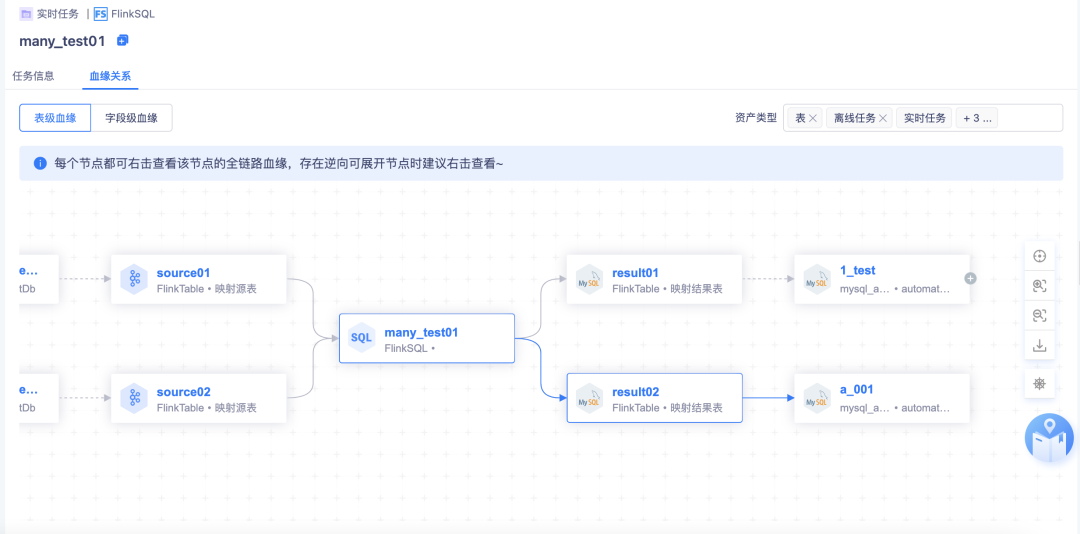
7.【全鏈路血緣】實時任務
· 任務型別有兩種:實時采集任務和 FlinkSQL 任務,FlinkSQL 任務存在欄位血緣關系
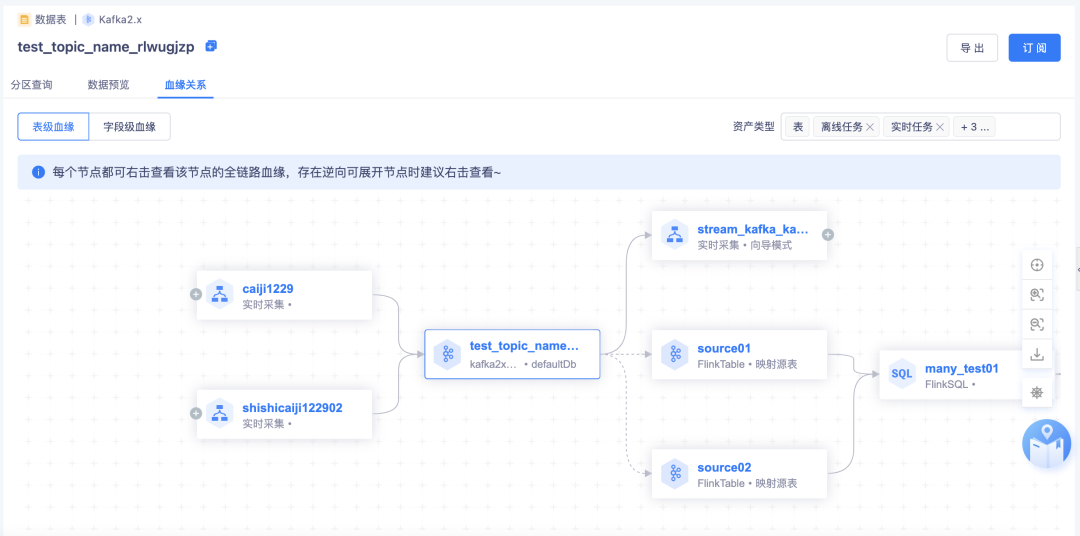
· 支持 kafka 側的血緣關系展示
8.血緣展示優化
· 右上角篩選項:優化為多選選單,表、離線任務、實時任務、API、標簽、指標(默認選中全部維度,當前進入的維度選中且不可取消)
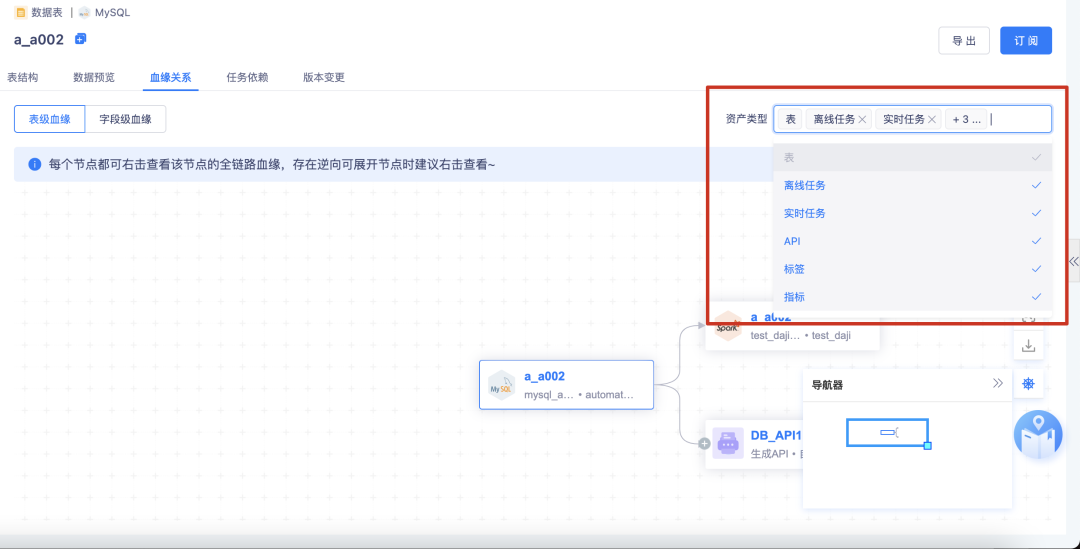
? 欄位血緣:不展示右上角的篩選項
? 逆向血緣全域提示:
a.進入血緣關系頁面,進行全域提示:“進入血緣每個節點都可右擊查看該節點的全鏈路血緣,存在逆向可展開節點時建議右擊查看~”
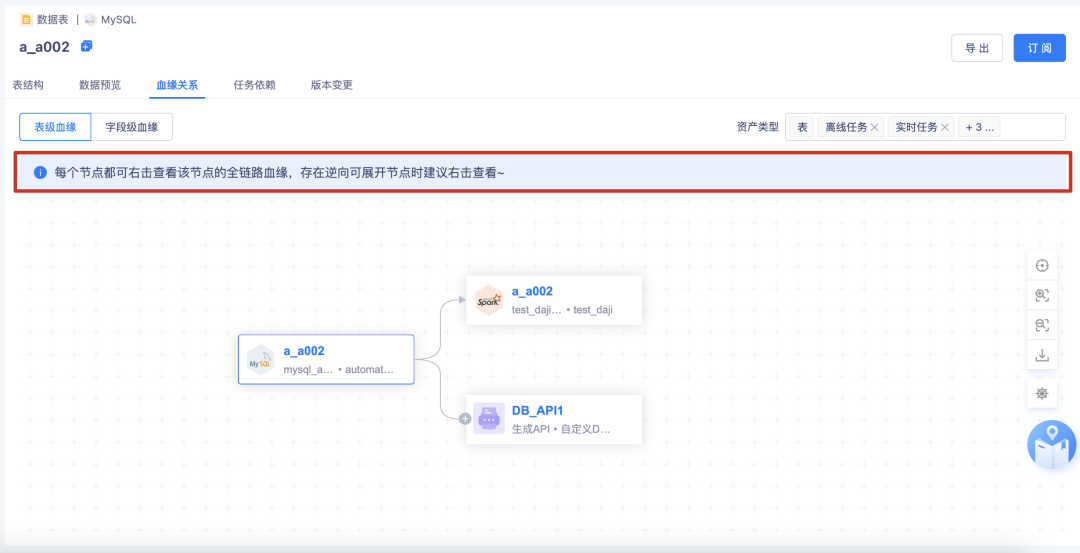
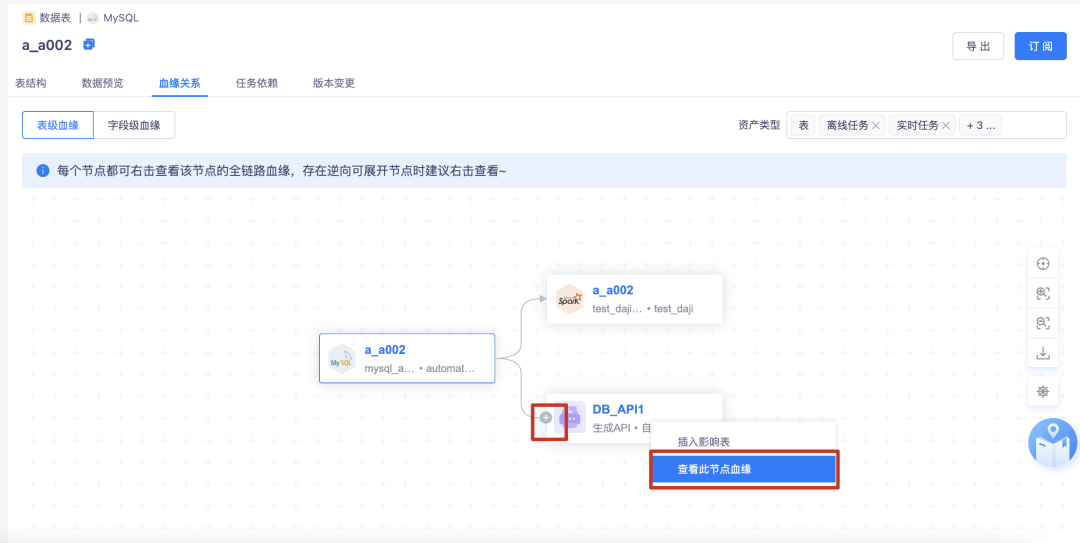
b.右擊查看當前節點的血緣會更完整
9.DatasourceX:【存盤】、【表行數】邏輯優化
背景:直接從 metastore 讀取是不準確的,之前 flinkx 是支持通過腳本更新存盤和表行數,flinkx 升成 datasourcex 之后,相關 analyze 邏輯沒有帶過來,
體驗優化說明:datasourcex 優化了對部分資料源的【存盤】、【表行數】的腳本統計,包括 hive1.x、2.x、3.x(cdp/apache)、sparkthrift、impala、inceptor,
10.DatasourceX:【存盤大小】【檔案數量】更新邏輯優化
背景:資料治理新增了 meta 資料源的檔案數量,又因為檔案數量這個屬性是 datasourcex 支持,普通的資料源也需要新增這個屬性,
體驗優化說明:datasourcex 對部分資料源的【存盤大小】【檔案數量】的腳本統計,資料治理結束后,更新【存盤大小】【檔案數量】邏輯,
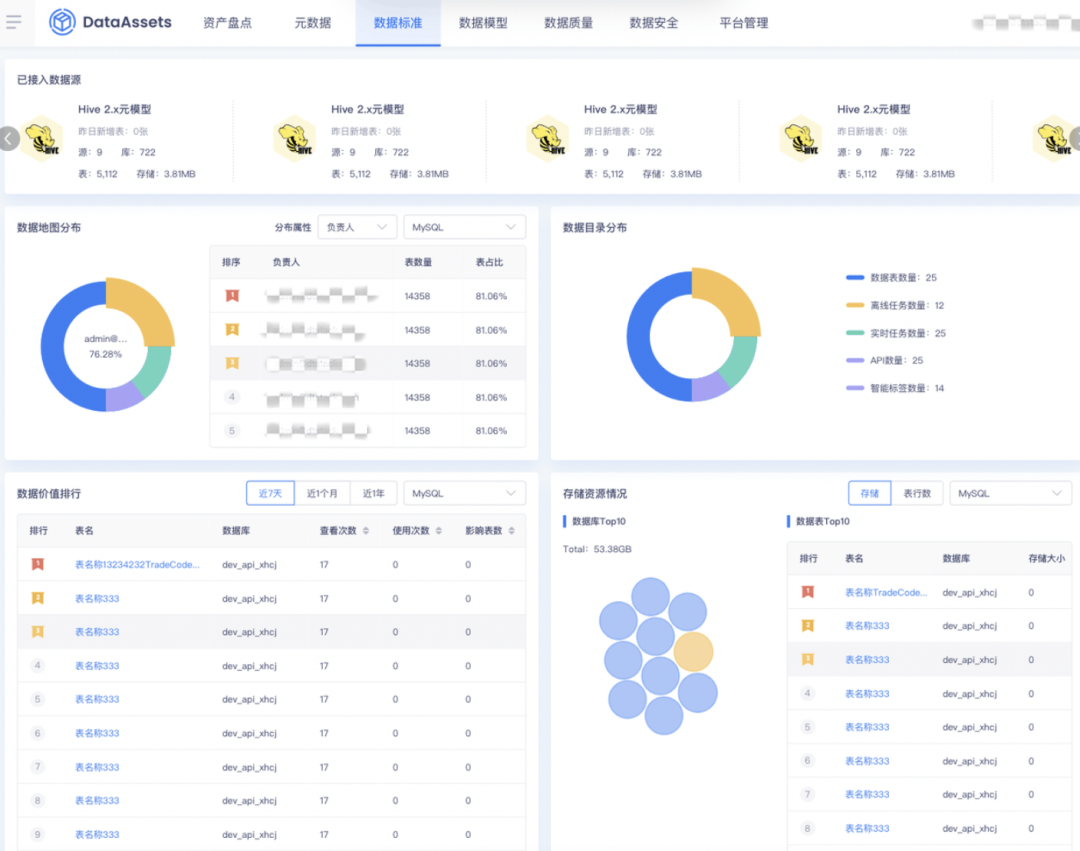
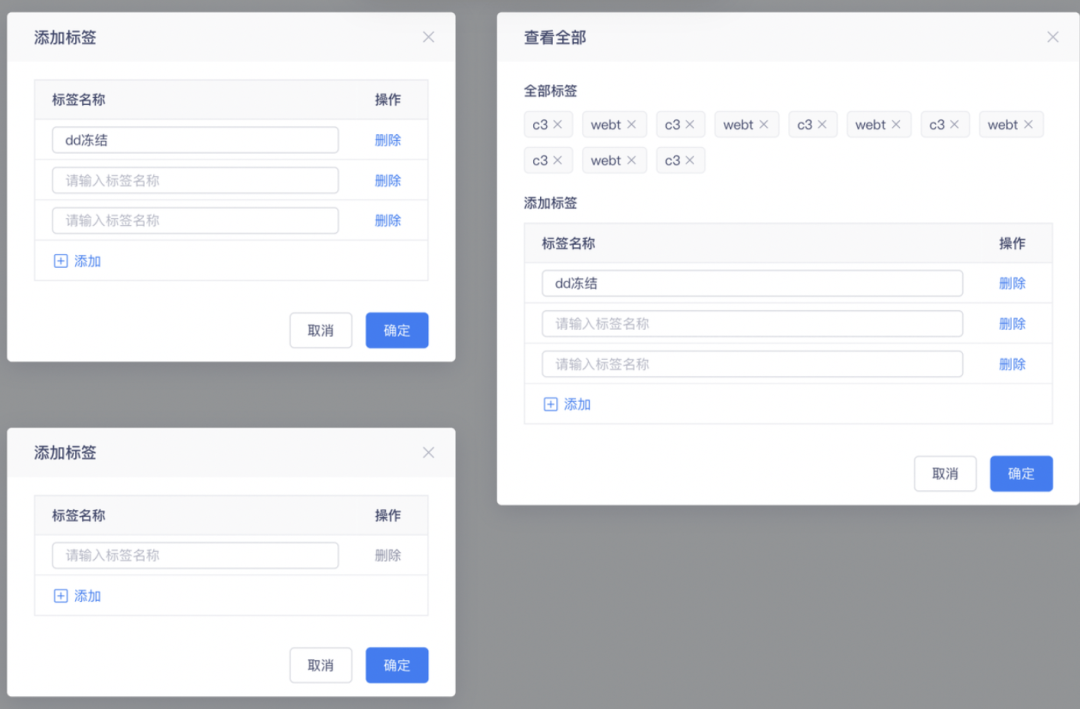
11.前端頁面升級
體驗優化說明
? 資產盤點
? 元資料標簽頁面
? 元模型管理

? 磁區優化
指標管理平臺
1.【demo封裝】demo功能優化
· 資料模型支持 catalog 選擇,catalog 默認采用 DT_demo 租戶下指標系結的 trino 資料源對應的 catalog,schema 資訊默認為 dt_demo,

· 「專案管理」模塊展示,支持查看專案配置資訊,支持設定 API 資料源,但不支持正常專案中可編輯的其他功能的修改,以保障 demo 專案的正常使用,

《數堆疊產品白皮書》:https://www.dtstack.com/resources/1004?src=https://www.cnblogs.com/DTinsight/archive/2023/05/12/szsm
《資料治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=https://www.cnblogs.com/DTinsight/archive/2023/05/12/szsm
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/archive/2023/05/12/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/552365.html
標籤:其他
下一篇:返回列表