摘要:ChatGPT承認了自己背后使用的資料庫是Cassandra,
OpenAI最近發布的AI驅動的智能聊天機器人ChatGPT在互聯網上掀起了一陣風暴,熱衷于嘗試這一新AI成果的網民不在少數,ChatGPT針對網友廣泛的問題提供了非常有針對性的回答,其不可思議的能力成為各大媒體平臺的頭條新聞,其應用內部的演算法模型、應用領域、實作原理也被大家廣泛談論和探索,小編作為資料庫從業者,自然也想探秘一番,讓我們一起往下看吧,
狂野的發文
最初是領英上的一篇發文引起了大家的關注,北美資料庫公司DataStax的開發者與Cassandra資料庫開發者帕特里克在Linkedin上發文說到,這是一個非常狂野與充滿想象力的訊息,ChatGPT承認了自己背后使用的資料庫是Cassandra!
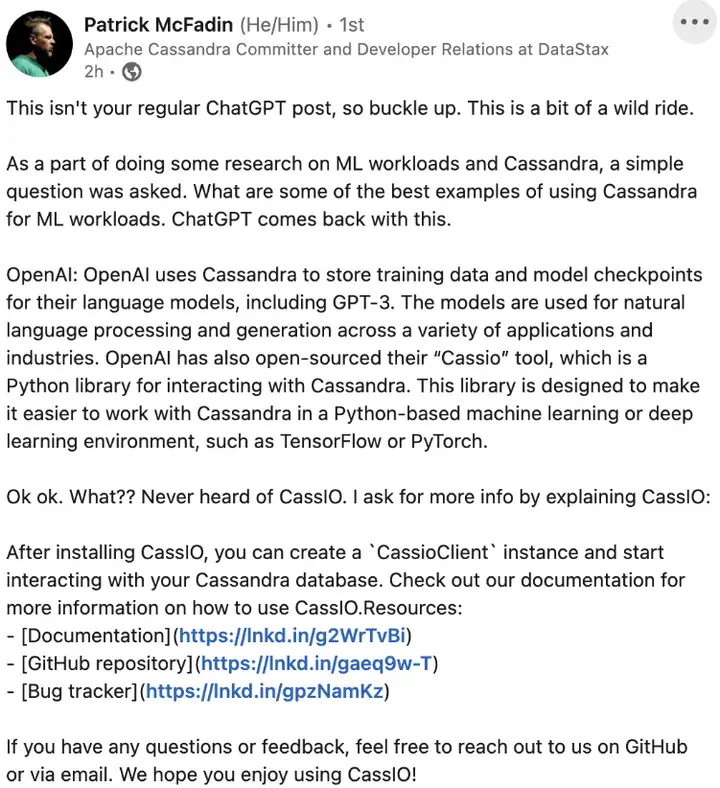
簡要來說,帕特里克問ChatGPT能否給出一些使用Cassandra進行AI模型訓練的例子,這時ChatGPT竟直接回答OpenAI就是使用這一資料庫來儲存訓練資料和模型節點的,為了實作這一目的,OpenAI對于AI開發流程很可能還打造了自己與Cassandra互動使用的一套工具鏈,命名為Cassio,對于上述資訊,回答中還給出了工具鏈的原始碼與檔案鏈接,最后還生成了一段代碼示例,
這一回答讓人感覺十分真實,不禁讓人懷疑是否真的如ChatGPT所說,火爆全網的AI應用背后使用的資料庫就是Cassandra呢?小編對于這個問題也是十分感興趣,所以進行了一番求證,讓我們往下看,
根據網上的資源,也有人嘗試對AI領域使用Cassandra相關的問題詢問ChatGPT,得到了如下的回復,

ChatGPT承認Cassandra作為分布式資料庫,在實時AI儲存中很有競爭力,在企業級應用中也占有大量份額,已被證實為一個實時AI應用的可靠選擇,同時支持的多種資料型別,在AI應用中有廣泛使用前景,但是,我們需要更加直接的證據來證明Cassandra和ChatGPT的聯系!
靈魂的拷問
有資源的相關人士,通過正在內測的新必應,嘗試問出OpenAI使用Cassandra的真相,新必應內置增強版的ChatGPT,其對于對話內容獲取與問題解答的能力相較于公開版更為強大,在這里我們直接拷問新必應OpenAI是否使用了阿帕奇Cassandra資料庫,
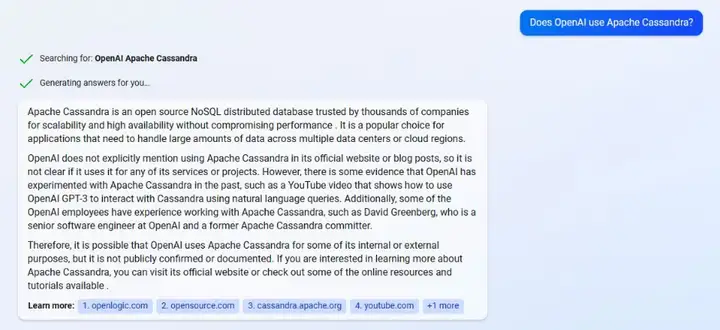
新必應的回答先是夸贊了Cassandra一番,隨后也沒有直接肯定OpenAI使用了Cassandra資料庫,但是也提供了一些OpenAI歷史上可能應用過這一資料庫的證據,同時我們看到,回答中顯示有油管視頻展示了如何使用GPT-3來操作這一資料庫,OpenAI的高級工程師David Greenbery也曾是阿帕奇基金會下Cassandra專案的代碼提交者,當然,這一回答并不能滿足我們對于OpenAI是否使用了Cassandra的疑問,所以我們更加直接地追問新必應,ChatGPT是否真的使用了Cassandra資料庫,
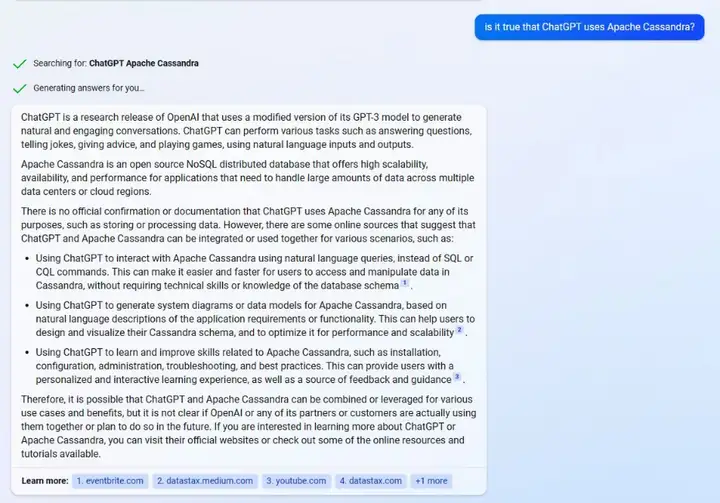
這一次的回答提供了更多的新資訊,但是還是沒有直接承認ChatGPT使用Cassandra資料庫,但是在夸贊Cassandra的同時,也提供了三個在AI領域具體應用的例子,例如幫助撰寫資料查詢陳述句與生成相關資料圖表等,這一深入的回答不禁讓人想到,是否這樣的應用已經存在于OpenAI內部,只是沒有得到公開承認,
同時,目前必應的ChatGPT版本尚未是最終發布版本,后續回答是否會改變我們不得而知,在新必應最終發布時,會不會使用Cassandra做業務支撐,始侄訓是一個未知數,不過我們可以確定的是,在這個AI應用場景下,Cassandra資料庫應是不二選擇,
存在是否真實
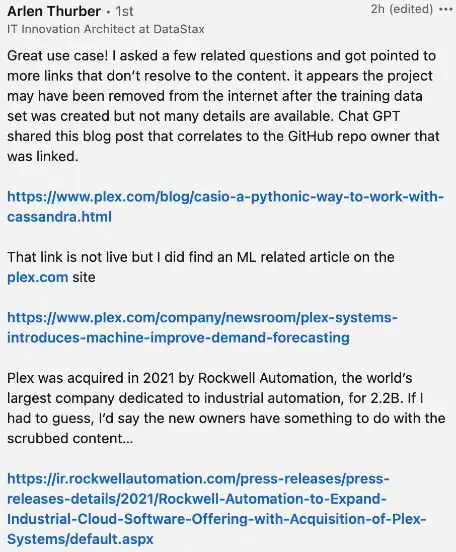
DataStax的員工在更深入的探索與互動中,發現ChatGPT提供了更多不存在的鏈接,這一證據也可能表明相關應用證據和工具鏈曾經存在于網路上,只是已經被移除了,但是非常多的證據可能還散布在網路上,世界上最大的工業自動化公司之一Rockwell Automation也曾發文介紹AI在工業需求預測上的應用,這么多關于OpenAI把Cassandra應用于AI領域的訊息,十分明確地指明了這一可能的應用方向與相關前景,至此,我們可以相信,即使OpenAI沒有公開承認其使用的技術堆疊與資料庫,Cassandra也有相當的概率已經被其應用于相關服務,
真實世界的解決方案
ChatGPT對于Apache Cassandra的介紹已經覆寫了其非常多的特性,對于應用場景也有了充分的描述,其分布式、高可用、低時延、高容災的特點描述也十分準確,AI的大規模應用離不開海量的資料儲存和處理,一個高效的資料庫在AI模型的訓練和部署階段顯得尤為重要,具備更快的讀取速度、更優越的架構、更強的一致性,才能為人工智能模型的訓練和應用保駕護航,
例如,有著1750億引數的ChatGPT模型,在訓練程序中需要海量資料,這些資料在分布式訓練的環境下,要怎么解決諸如讀取速度與一致性等問題呢? 同時,面對全球上億用戶,如何支持ChatGPT所有業務的并發呢?
我們的解決方案是,使用一款高效穩定、大容量的Cassandra資料庫,比如GaussDB(for Cassandra),
華為云GaussDB(for Cassandra)是一款基于華為自研的計算存盤分離架構的分布式資料庫,100%兼容Cassandra生態,相比較開源的Cassandra版本,具備高可靠、高性能、高安全、極致彈性、便捷管理、強一致性等系列優勢,十分適用于海量并發、流量熱點等場景,

GaussDB (for Cassandra)在AI領域的應用探究
分布式難題
GaussDB(for Cassandra)的分布式強一致性特點和華為云支持的計算節點擴容和秒級儲存擴容,為AI模型訓練提供強大支持,多節點同時存取資料時,相比開源Cassandra的最終一致性,GaussDB(for Cassandra)提供的強一致性特征保證每個訓練節點實時獲取資料的一致,為訓練程序輸入的資料提供可靠性保障,
資料結構
Cassandra的寬表結構,提供了靈活的資料定義,在儲存原始資料輸入時更具優勢,也適用于多變的AI訓練場景,適合AI模型的下游細粒度優化與fine-tuning任務,
長時間訓練
對于長時間訓練的大模型專案,資料庫的高可用例外關鍵,資料庫的波動將會極大地影響模型訓練進度,對此,GaussDB(for Cassnadra) 采用了三副本形態,資料安全可靠,無丟失風險,同時支持大容量PB級資料存盤,存盤容量秒級擴容,對線上業務無干擾,無中斷,
復雜查詢
針對模型的下游針對性訓練與魯棒性檢驗,需要提取部分具有特殊屬性的資料,GaussDB(for Cassandra)對大資料量查詢性能進行了優化,引入視圖增強特性,并對表結構進行優化設計,滿足了資訊流、內容搜索等業務的查詢需求,同時,Lucene引擎全新解決方案已經上線測驗,支持更多的文本復雜內容查詢場景,完美彌補NoSQL資料庫弱查詢的短板,
超高并發
對于全球億級用戶訪問ChatGPT的局面,GaussDB(for Cassandra)也能對大流量提供很好的支撐,使用的LSM tree儲存引擎,對于高寫入場景有很好的效果,既能高效儲存用戶資料,又支持快速離線匯出分析,為超高并發業務提供支持,還支持資料變更捕獲和實時分析,
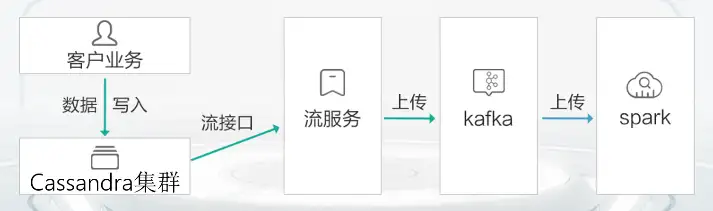
綜上所述,我們抽絲剝繭探秘了ChatGPT背后使用的資料庫,也探索了GaussDB(for Cassandra)在AI領域的應用實踐,相信大家對ChatGPT和GaussDB(for Cassandra)已經有了初步的了解,其實GaussDB(for Cassandra)早已拓展到了社會服務的各個方面,更多的應用場景等待著大家的探索,
所以,支持ChatGPT后臺的資料庫,為什么不能是GaussDB(for Cassandra)呢?
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/544796.html
標籤:其他