摘要:主要介紹華為云在HBase 2.x內核所做的一些MTTR優化實踐,
本文分享自華為云社區《華為云在HBase MTTR上的優化實踐》,作者: 搬磚小能手,
隨著HBase在華為云的廣泛應用,HBase的資料節點規模也越來越大,最新版本的MRS可支持的單集群HBase資料節點規模可達到1024節點,可支持的region數量可達到200w+,面對如此大規模的節點數量,集群的MTTR也面臨著巨大的挑戰,
首先介紹一下HBase故障恢復涉及的幾個主要Procedure:
- ServerCrashProcedure:處理單個RegionServer的恢復的Procedure任務,是所有其他相關任務的Root Procedure;
- SplitWALProcedure:處理單個WAL檔案資料恢復的Procedure任務;
- TransitRegionStateProcedure:處理單個RegionServer上下線的Procedure任務,
RegionServer節點故障恢復流程(基于2.x內核)
當HMaster檢測到RegionServer故障后,會創建一個ServerCrashProcedure任務處理RegionServer的故障恢復,
該Procedure任務主要處理的事務包括WAL Split和Region Assign:
- 其中WAL Split由Sub Procedure:SplitWALProcedure負責,每個WAL檔案對應一個Procedure,所以一個ServerCrashProcedure可能存在多個SplitWALProcedure;
- Region Assign則由Sub Procedure:TransitRegionStateProcedure負責,每個region對應一個Procedure,因此一個ServerCrashProcedure也會存在多個TransitRegionStateProcedure,
由此可以看出,一個RegionServer節點的恢復,中間會涉及到大量的Procedure任務,下面我們介紹一下華為云的HBase這對這部分所做的一些優化實踐,
優化一,異步ServerCrashProcedure
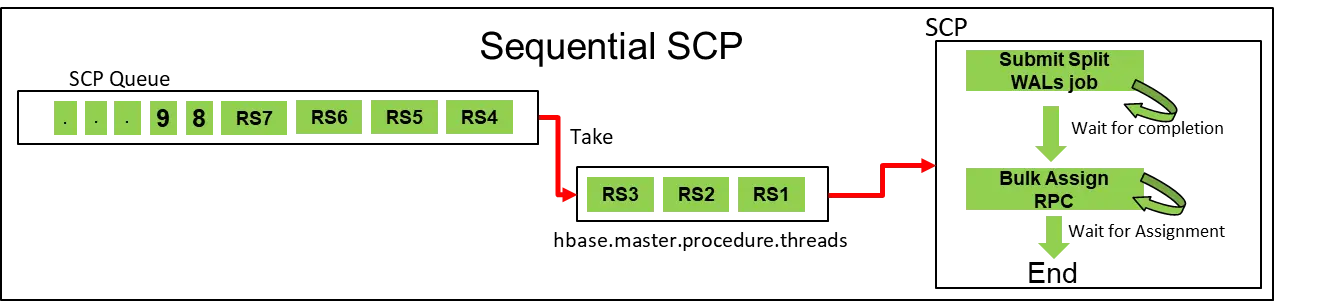
前面提到ServerCrashProcedure會包含多個SplitWALProcedure和TransitRegionStateProcedure,這兩種Procedure在ServerCrashProcedure里面是串行執行的,也就是說TransitRegionStateProcedure只有在所有SplitWALProcedure任務執行完成之后才會開始執行,在WAL Split流程結束之前,整個ServerCrashProcedure會一直占用Procedure的執行緒資源并等待,
在大集群的場景下,由于HMaster的Procedure執行緒池資源有限,這樣會導致有大量的ServerCrashProcedure任務在佇列中等待,
針對這種情況,我們講ServerCrashProcedure任務改為異步執行,在執行WAL Split程序中,將ServerCrashProcedure重新放回佇列并釋放資源給其他待執行的任務,當WAL Split執行完成后,再重新喚醒該任務并繼續提交執行TransitRegionStateProcedure,
優化前:MTTR = (Avg SCP * RS Count) / (hbase.master.procedure.threads)
優化后:MTTR = (Avg Split time) + (RS Count * Avg Assign time)/ (hbase.master.procedure.threads)
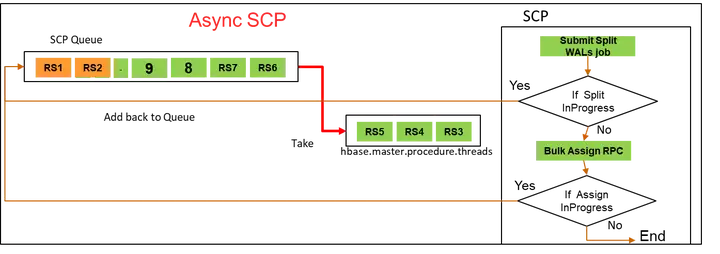
優化二,Split WAL to HAR
通過測驗,我們發現在WAL Split階段會產生大量的檔案IO,主要是因為WAL Split階段會生成大量的recovered.edits檔案,因此,在大集群下,這部分的開銷會導致HDFS的NameNode成為瓶頸,
對此,我們利用Hadoop提供的HAR file對生成的小檔案進行優化,大大減少檔案IO的開支,達到MTTR優化的目的,

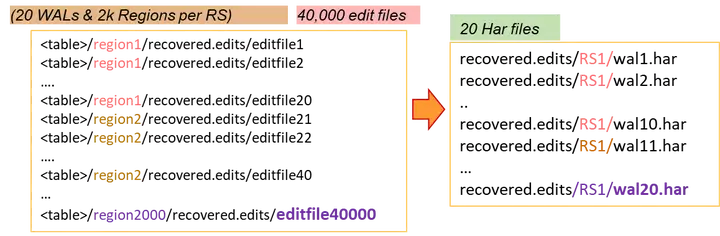
我們以單個RegionServer 20個WAL+2000個region來舉例:
通過HAR優化,單個RS的IO次數將由2000次讀+2000次寫減少為3次讀+3次寫,單個RS生成的檔案資料也由40000個減少為20個,
最終在測驗環境通過對100個RS,每個RS 20個WAL+2000個region的規模進行對比測驗,HDFS的的IO負載下降了70%(RPC請求數從640萬下降到150萬左右),MTTR的時間則從103分鐘下降到26分鐘,
優化三,Batch TRSP
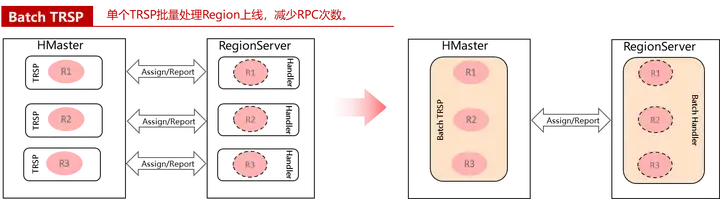
由于TransitRegionStateProcedure只負責處理一個Region,大集群下的region往往都在幾十萬甚至更多,這樣的話,HBase恢復程序中會產生大量的TransitRegionStateProcedure任務,為了減少大量Procedure所帶來的任務開銷,我們優化了TransitRegionStateProcedure,允許一個Procedure任務處理一個RegionServer上所有的region assign,這樣不僅減少了Procedure任務的數量,還大大減少了HMaster跟RegionServer的RPC開銷,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/541407.html
標籤:大數據
上一篇:自動增長配置不合理導致的性能抖動