
本文根據digoal(德哥)在〖2019 DAMS中國資料智能管理峰會〗現場演講內容整理而成,
講師介紹
digoal(德哥),PostgreSQL中國社區發起人之一、常委、兼任社區大學校長,阿里云資料庫首席專家團隊成員,提供資料庫首席專家服務,現任職于阿里云資料庫團隊,主要負責阿里云PostgreSQL產品線,包括RDS PG、PPAS(兼容Oracle)、POLARDB兼容PG、Oracle語法引擎的產品設計、推廣、應用落地與生態構建,
分享概要
1、PG社區的獨特性
2、PG的商業能力和創新能力
3、PG新版本與新特性
4、PG on 云
最近幾年我在推過PG的活動中,走過差不多15、16個國內城市,遇到不少參會者問到這樣一些問題:
- 學生非常關心學習PG能從事什么樣的作業、未來發展機會如何?
- 用戶特別關心遷移到PG是不是最終狀態?它是不是未來的趨勢?
- 作為一個開源資料庫,背后是不是有商業公司在控制著它?
所以,我首先會分享PG社區的內容,
一、PG社區的獨特性
如果說99%的開源資料庫都是被商業公司控制的,那么PG是那1%,要說商業公司為什么要把資料庫開源出來?為什么要改協議?這個我們先來分析一下:今天你要研發一款資料庫,并且得到市場的認可,如果不開源的話,你會發現這個資料庫必須要有很好的渠道才能賺錢,所以商業公司選擇開源,培養背書群體,擴大生態,收割大客戶,至于為什么要改協議?我們看到許多商業開源資料庫都有對應的付費版本,例如企業版,高級周邊工具等,隨著上云成為了大趨勢,“云開源資料庫服務”吞噬著開源資料庫市場,用戶更多選擇的是云服務,而不是開源資料庫的企業版,這就造成了商業開源公司與云發生利益沖突,改協議是商業開源資料庫廠商被迫的選擇,而PG是一個純社區的資料庫,背后沒有被任何一家公司所控制,我們來看一下以下這張圖:
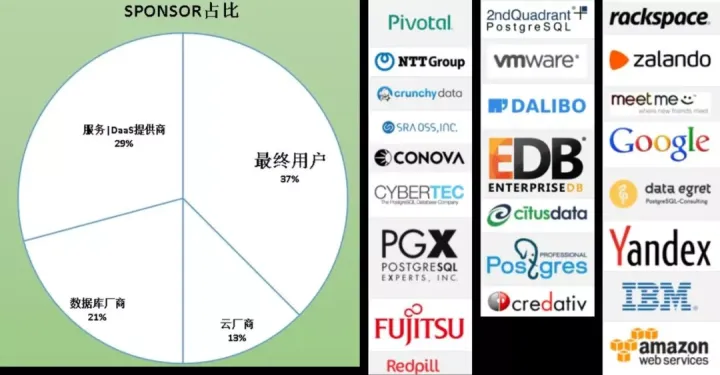
餅圖展現的是給PG貢獻代碼的占比,我們先看資料,后面再跟大家分析一下原因,看圖你會發現占最大頭的是用戶,第二是資料庫服務商,這里的服務包括培訓、技術支持類的服務等,這兩大塊加起來就有66%了,剩下的就是資料庫廠商和云廠商,

上圖是給PG貢獻代碼的國家分布,上面沒有中國有點遺憾,但可能是因為這個至少要貢獻兩年以上才入列,所以中國估計過兩年會出現在這里,
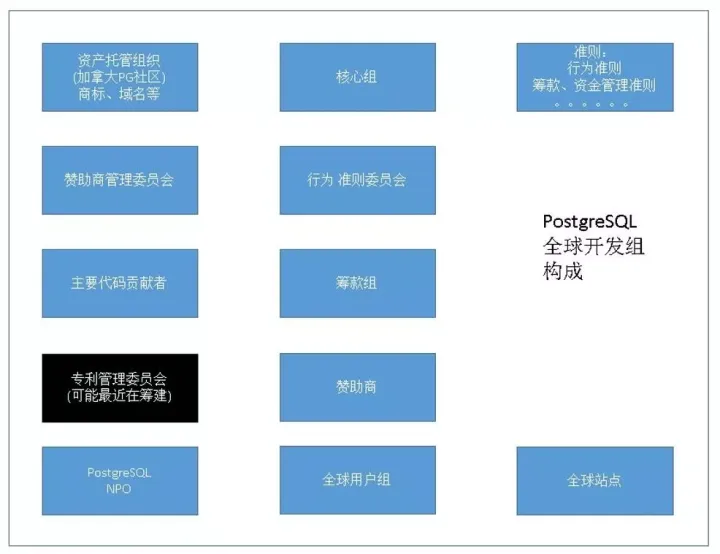
PG作為一個開源的社區資料庫活了這么久(追述到ingres的話有43年歷史),感覺牙齒不但沒掉還越來越鋒利,憑什么?PG有組織有紀律,從上圖可以看到首先是資產托管組織,包括商標、域名等,每年的開發者峰會在加拿大舉辦,
另外還有核心組、行為準則團隊,類似于組織部,有專門管贊助的委員會、籌款組等等,將來可能會組建專門負責管理專利的委員會,因為作為開源資料庫會發現專利可能是一個非常容易存在的漏洞點,PG對專利控制還是比較嚴格的,
回過頭分析剛剛給PG社區貢獻代碼的企業,他們為什么要持續貢獻核心代碼?
對于資料庫廠商來說,推一款新的商業資料庫通常都需要背書,試問小廠產品誰為你背書?
- 只有技術的廠商,很難挑戰已有資料庫市場格局,
- 只有渠道的廠商,需要抓住視窗期,快速占領市場,避免重復造輪子,需要一款可以無法律風險,二次開發與分發的開源資料庫,
目前達到商業化成熟度的唯有PG,所以資料庫廠商需要通過貢獻核心代碼,社區所有的用戶都可以為之背書,
對于資料庫服務提供商來說,開源產品的服務提供商,怎么才能體現他們的能力?誰能證明他們的牛逼?貢獻代碼,貢獻代碼之后用PG的那些人就可以為之背書,
對于最終用戶來說,他們希望社區長久,期望可以享受免費的、可持續發展的、開源的、不被任何商業公司、不被任何國家控制的企業級的資料庫,而且PG用的人越多,越多人背書,使用越靠譜,就像滾雪球一樣越滾越大,所以最終用戶愿意貢獻代碼,實際上是在推動開源產品的發展,對客戶自己也是有利的,
對于云廠商來說,自己做一款資料庫在云上賣需要培養生態,需要市場背書,需要大量研發資源,可能還需要重復造輪子,那么基于PG,就能免去自己培養生態,避免重復造輪子,而且PG的代碼基礎已經具備商業化基礎,另外,不斷提供代碼也是防止其他廠商控制PG失去市場主導能力的方法,
開源許可獨特性
除了以上這些原因,還有很重要的一點,開源許可獨特性,PG的開源許可是類BSD許可,可以隨意分發、閉源或開源,可以被用于商業目的或其他場合,

PG開源中心的這行字(見紅框),說的是不管怎么使用、拷貝、修改、分發這個軟體,只要把這一行放到你的輸出版本里面去就行了,是不是活雷鋒?所以云廠商選擇這么友好的純社區版本感覺像揀到寶一樣,
架構獨特性
作為一款開源出來拿去直接用的資料庫,PG采用了開放介面的設計,是最具擴展能力的資料庫,基于PG的圖資料庫、流資料庫、GIS、時序資料庫、推薦資料庫、搜索引擎等;圍繞PG的應用垂直化插件機器學習、影像識別、分詞、向量計算、MPP等,基本上都是使用PG擴展介面擴展出來的,
商業趨勢
目前全球都在提高安全、合規、正版化意識,對于資料庫廠商、云廠商來說,從長遠來看,純社區具有這么強的可擴展能力的資料庫,PG可以說是首選,生態已經擺在這里了,還有不去用的理由嗎?
技術趨勢
首先,PG是一款遠遠超越當前關系資料庫的多模資料庫,因為它的開放性,可以隨意擴展,
其次,在內置并行計算方面,我接觸過很多用戶的資料庫就跟蜘蛛網一樣,為什么?因為用戶的業務需求很多,關系資料庫處理不了,需要將資料同步到其他引擎:最常見的有計算平臺、搜索引擎,還有一些客戶要同步到流計算平臺,空間,時序資料庫平臺等,同步會帶來硬體、管理、開發成本的增加,同時會引入資料丟失、延遲等風險,如果資料庫提供并行計算、搜索、時空等多模能力的話,沒必要把平臺建這么復雜,
再次,PG開始在內核中支持存盤引擎的擴展,可以解決行存、列存、記憶體引擎,多樣化的多版本控制,等不同場景不同需求的問題,
最后,在芯片支持方面,PG對芯片友好,例如ARM芯片的支持,
以上四方面滿足市場的既要又要還要的需求,即:既要SQL通用性,又要NOSQL擴展性,還要多模開發便捷性;既要OLTP又要OLAP,
二、PG的商業能力與創新能力
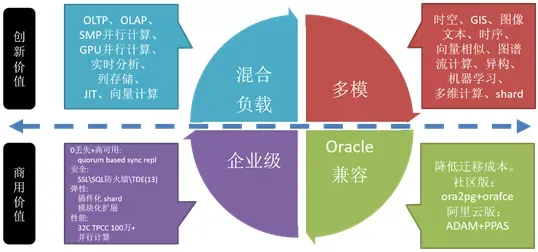
對于資料庫的商用價值來講,首先是能不能扛住企業級的需求,也就是能不能做到零丟失、高可用、安全;彈性這一塊就是能不能橫向擴展、能不能做模塊化;而性能這一塊TP、AP都可以跑,Oracle兼容性體現兩塊:社區版本有這樣的插件,加完這個插件在Oracle資料型別然后還有函式,還有操作服務這一塊做的兼容,包括包也做的一些,因為用戶我見過大量的使用PLsql的存盤程序或函式,一個業務部就有上百萬行,使用PG的plpgsql可以改造這些oracle plsql存盤程序代碼,
另一方面嗎,阿里云提供兼容Oracle的資料庫PPAS(實際上也是基于PG的),我們兼容了PLsql語法,能夠減輕用戶區改造存盤程序到PG的作業,所以說這個東西熟悉之后你會發現PLPgsql能夠滿足功能差不多,沒有會弱到哪里去,其實做得挺好的,
在創新能力上,其實我們剛剛講到了一塊關于邊緣計算,邊緣計算分兩塊:基于GPU的并行,對用戶是透明的,資料庫會根據sql的成本、代價去啟動GPU并行計算,
阿里在這里同樣開源,阿里因為在線上有很多的用戶,包括影像處理、移動跟蹤做了GPU加速,這就是創新價值,
多模使得PG這個資料庫得以滿足那些你曾經想都不敢想的需求,
三、PG新版本與新特性
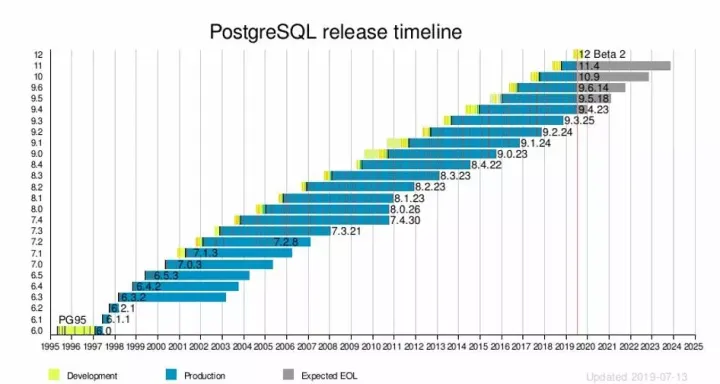
上圖展示的是PG版本發布節奏,如果每年股票是這樣漲的話大家肯定很開心,作為背后沒有商業公司沒有驅動的開源資料庫,PG每年發一個大版本,每個大版本會持續維護五年,有組織有紀律就是不一樣,
PG 11新特性
PG 11是去年發的,有什么新特性?在此說明一下,我這里說的特性全部基于PG自己,比如基于11以前的版本,其實有很多功能很早之前就已經支撐,
1)磁區表增強
- hash磁區;
- 支持觸發器;
- 支持默認磁區;
- 允許修改磁區欄位,
2)并行計算增強
對業務完全透明的并行計算,幾乎覆寫所有的場景,平均20倍的提升,

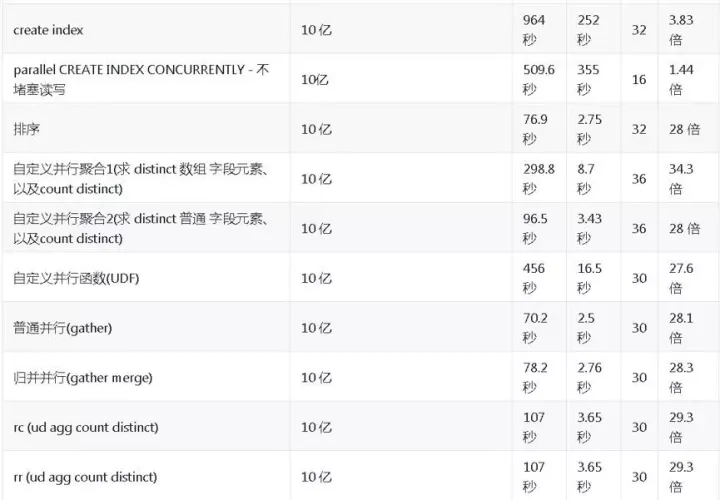


以上這個CASE資料量10億的表,大家覺得10億做排序要多久?不到3秒,不開并行需要70多秒,
什么時候要用并行計算?通常是實時分析,復雜查詢,馬上就要看到結果,原來需要T+1,現在就想做實時,
我們來看一下這些CASE,第一個是最簡單的全表掃描,要將近1分鐘,開并行只需要1.8秒,
哈希聚合,因為我們做分析一定會涉及到聚合,處理大量的資料,有哈希聚合、分組聚合,10億記錄的聚合需要花多少時間?5秒!不開并行需要140多秒,
做資料分析處理一般流程比較長,會有中間結果,
這些中間結果可能是通過create table as這種方式出來的,這種操作能不能支持運行?也可以,
同樣也是10億的資料量,差不多1.9秒,
創建索引,想不想很快完成?比如說這個索引膨脹,你想快速重建索引發現性能不行,10億記錄不帶并行將近1000秒,開啟并行后只需要252秒,
關于聚合的話,資料庫會提供一些聚合函式,比如說平均值、標準方差,有些時候發現資料庫提供聚合的方式不夠用,不能滿足你的業務要求,
所以的話需要自定義聚合,自定義聚合操作也支持并行,這邊也做了兩個測驗,一個求(count distinct)個數,另一個求count distinct陣列元素個數,分別從300,100秒降到了8秒,3秒,
另外還進行了其他復雜查詢(join、cte、subquery、排序、磁區查詢等),不再一一贅述,性能平均提速20倍左右,
3)btree index include索引葉子附加屬性

這個特性比較有意思,創建索引的時候一般怎么做?制定欄位放進去,這些欄位是我要查的,我這里舉一個例子說,用非索引組的表,資料怎么存放?寫進來沒有任何順序,
比如說有這樣的業務做移動物件跟蹤,共享單車,我們在手機里可以看歷史軌跡,由上報的點組成,一般來說行程會涉及到上千個點,上報的資料是一條一條插進來的,這個世界有很多人同時騎車,也就是說很多人都在上報資料,你去查某一筆訂單的軌跡,我們怎么通常怎么優化?在訂單號加索引,感覺挺快的,但是有沒有想過這個問題在那里?你的資料是無序存盤,1000條記錄可能是分布在1000個資料塊,如果同時有大量并發查詢可以把IO打滿,即使這個資料在記憶體,也很容易觸達記憶體帶寬上限,
最后怎么解決這個問題?通常建個合索引,可以查出來,當然可以了,但是這里出現另外一個問題,這個Key在索引page的每個層面都是多個Key,他的這種split概率就會增加,但是實際上查詢條件就是驅動列,就是你的訂單號的哪一列,所以實際上可以創建索引的時候還是用訂單號,但是我把你的時間放到leaf page,同一個訂單的附加欄位的資料被放到了同一個訂單所在的葉子里面,這個時候來查詢,因為這個資料一千個點只落在三五資料塊,Include index相比較索引組織表的好處:我可以創建很多個按你的要求來的索引組織,好像同一份資料有很多資料組織結構一樣,然而索引組織表只有一種結構,
4)添加欄位(含默認值)更快
以前添加欄位不加否認值就是改一個原資料,以前加默認值做table rewrite所以慢,現在我們會變成甭管加什么欄位,甭管是否包括默認值,總之瞬間完成,對用戶特別友好,


5)支持存盤程序
在存盤程序中,支持子事務提交,
CREATE [ OR REPLACE ] PROCEDURE name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] ) { LANGUAGE lang_name | TRANSFORM { FOR TYPE type_name } [, ... ] | [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER | SET configuration_parameter { TO value | = value | FROM CURRENT } | AS 'definition' | AS 'obj_file', 'link_symbol' } ...
PG 12新特性
1)AM介面

如上圖所示,左邊是12以前的版本,右邊是12版本,12中間加了一層訪問方法,這里面有索引方法或表訪問方法,剝出來的好處就是我們可以在這個地方加新的資料存盤結構,例如加記憶體表、列存表,壓縮表等,都可以在這一層去做,
所以就有了列存的引擎,這里舉兩個例子,zedstore(列存)和zheap(支持回滾段),列存壓縮率高,支持向量計算,非常適合做批量計算,分析領域的性能提升很明顯,
第二就是zheap,把回滾段從資料存盤剝離出來,舊的版本拷貝到回滾段去,查到過去的版本去回滾段查,減少膨脹問題,
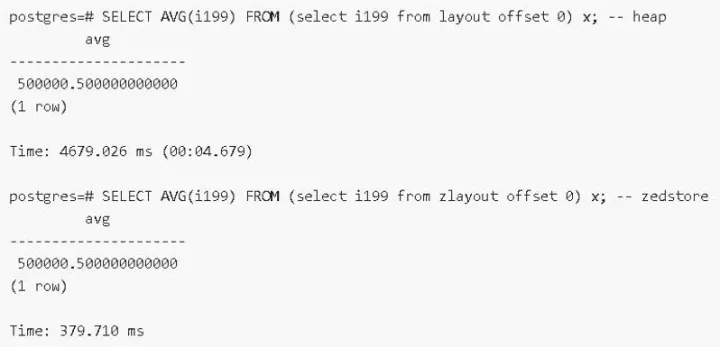

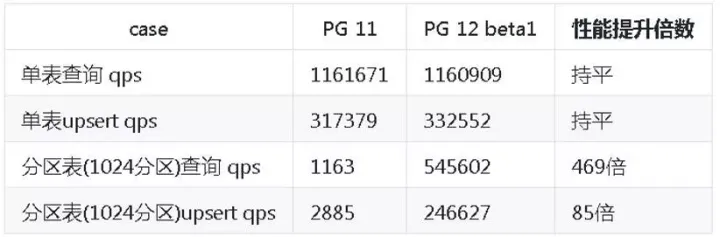
2)磁區表-大量磁區性能提升
原生磁區(包括11的版本)磁區很多有性能問題,12這一塊已經優化掉,在1000個磁區時,查詢有提升400多倍,磁區越多,性能提升越明顯,
3)GiST index include索引葉子附加屬性
- 正軌跡,時空搜索;
- 按結果集(索引)聚集存盤,消除回表IO放大,
4)CTE 物化、非物化
物化的下推,在12版本里面可以指定要不要物化,如果是物化的話,物化的子句跟外面完全隔離,相當于這一層單獨計算,如果指定不要物化,那么優化器會考慮子句外面的條件,可以將條件傳遞給非物化子句,提前過濾,提高性能,

5)日志采樣
日志采樣,相當于之前做審計日志,你要么全開,要么全關,實際上有的用戶要的是不要所有的采下來,比如說做排錯,同類錯誤不需要都被記錄下來,采樣就可以了,又比如說查詢訪問量特別大,如果所有的sql全審計下來會影響性能,使用這個采樣的功能,不會影響性能,
6)COPY WHERE


Copy時支持過濾條件,可以在匯入資料時過濾不需要的記錄,
四、PG on 云
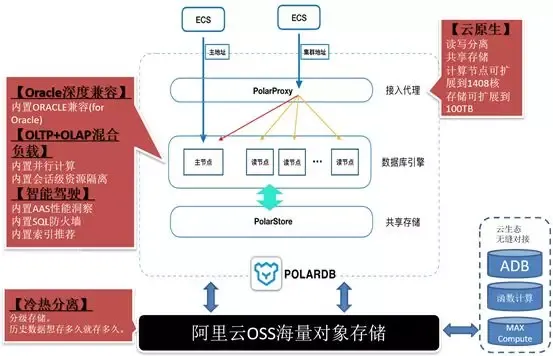
作為阿里巴巴自主研發的下一代關系型分布式云原生資料庫,PolarDB目前兼容三種資料庫引擎:MySQL、PostgreSQL、高度兼容Oracle語法,計算能力最高可擴展至1000核以上,存盤容量最高可達100T,
- 兼容Oracle語法的引擎:高度兼容Oracle語法,降低Oracle遷移風險、縮短遷移周期,助力企業快速替換Oracle,進入云智能時代,
- 兼容PostgreSQL的引擎:完全兼容PostgreSQL,支持計算與存盤分離、獨立伸縮,存盤按量付費,業務透明讀寫分離(該項功能開發中),適合中大型企業核心業務場景,
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/Why-is-PostgreSQL-the-only-way-to-shift-O.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/540764.html
標籤:PostgreSQL
上一篇:MongoDB - 模式設計