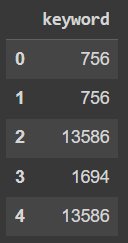
原始 df 包含數百萬行。這是一個例子:
df_sample = pd.DataFrame(
{'keyword': {0: 756, 1: 756, 2: 13586, 3: 1694, 4: 13586}}
)
df_sample
現在我們有兩個串列:
list_a = [756, 13586, 1694]
list_b = [1.44, 4.55, 10]
我需要以下輸出:
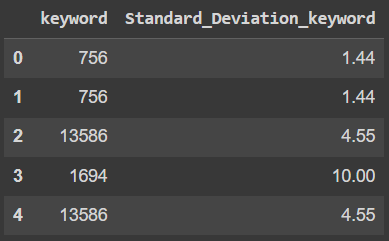
df_output = pd.DataFrame(
{'keyword': {0: 756, 1: 756, 2: 13586, 3: 1694, 4: 13586},
'Standard_Deviation_keyword': {0: 1.44, 1: 1.44, 2: 4.55, 3: 10, 4: 4.55}}
)
df_output
我想解決方案是這樣的:
def key_std(df):
add a new column = Standard_Deviation_keyword
for every x value of df.keyword:
if x == "a value" in list_a:
find the value at the same index in list_b
and add that value to the same row in
Standard_Deviation_keyword column
uj5u.com熱心網友回復:
zip串列并創建一個映射dict,然后用于Series.map替換值
df['std'] = df['keyword'].map(dict(zip(list_a, list_b)))
keyword std
0 756 1.44
1 756 1.44
2 13586 4.55
3 1694 10.00
4 13586 4.55
uj5u.com熱心網友回復:
如果串列中沒有相應的元素,您也可以使用df.replacewhich will not give NaNdistinct :map
df_sample['std'] = df_sample.keyword.replace(list_a, list_b)
uj5u.com熱心網友回復:
您可以map與系列一起使用:
s = pd.Series(list_b, index=list_a)
df_sample['std'] = df_sample['keyword'].map(s)
輸出:
keyword std
0 756 1.44
1 756 1.44
2 13586 4.55
3 1694 10.00
4 13586 4.55
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/507404.html