?大資料概述
在大資料這個概念興起之前,資訊系統存盤資料的方法主要是我們熟知的關系型資料庫,關系型資料庫,關系型模型之父 Edgar F. Codd,在 1970 年 Communications of ACM 上發表了《大型共享資料庫資料的關系模型》的經典論文,從此之后關系模型的語意設計達到了 40 年來普世、易于理解,語法的嵌套,倍訓,完整,關系型資料庫管理系統(RDBMS)就是基于關系模型在資料庫領域所構建的傳統資料庫管理工具,例如大名鼎鼎m的Oracle、DB2、MySQL、PostgreSQL、SQLServer等,
作為早期的互聯網、電子政務、商業管理、工業制造等行業領域,首先每天產生的資料量并不大,而且以高價值的結構化資料為主,例如:早期互聯網Web1.0時代,一臺SQLServer資料庫就能支撐絕大多數的門戶網站,一臺小機搭配Oracle就能輕松應對在線金融業務系統;其次資料訪問需求比較簡單,主要是業務資料模型之間的關聯設計,業務資料的插入、更新和洗掉,對于更復雜的資料需求主要還是對欄位的分組查詢形成多維統計和明細下鉆,
但是這一切都被互聯網的發展所打破,尤其是到了2010年移動互聯網的爆發,大資料的名詞和概念隨著Google的定義席卷了全球,那么大資料最基本的一個特征就是資訊服務所接收到的資料請求量非常龐大,這對于傳統的RDBMS來講是沖擊性的,
舉個例子:微博一個頂流明星關注的粉絲都是千萬級以上,若按照關系型資料庫的存盤與查詢方法來做一次明星內容推送,那么就需要按照明星ID查詢到所有粉絲ID,給每個粉絲的關注者動態表增加一條明星新發布內容的ID,這對于關系型資料庫來講是極為恐怖的一次二級索引遍歷事件和索引構建事件,而這種事件在微博業務里面每天都是高頻次產生,另外B樹索引會被千萬級的索引量撐大得特別寬,這種遍歷基本上就是瘋狂的IO掃描,那么我們可以想象到,上億次的發布,在成千上百億的資料量中不斷遍歷,再強悍的關系型資料庫都會瞬間崩潰,
上面主要提到的是互聯網大平臺的常見請求服務,資料庫對于海量資料進行索引請求操作的恐怖性能需求,那么這些資料量在大資料概念興起之后的驟然劇增是什么原因導致的呢?
主要因素就是互聯網越來越普及,被連接的資訊點越來越密,資訊的傳輸和交流變得越來越通暢,例如:早期的金融、保險、電信等資訊系統若要將資料匯集到管理中心,都是各個地區負責人對自身所轄資料庫進行檔案輸出,然后再將檔案定期上傳到中心,最后由中心管理員統一匯總,這種方式最大的問題就是資料延遲很大,提交的資料質量總會因為不統一的規范而導致參差不齊的質量,尤其是匯聚到中心的資料,盡管體量龐大,但是不具有從起點到終點的全程序設計,因此資料的應用程度很低,這就導致了資料倉庫變成了資料墳墓,
但是通過互聯網、移動化,現在大量的業務從源頭就開始了向一個中心平臺服務的業務提交,資料匯聚,那么資料就實時地流動起來了,每天形成了大量的資料業務存盤,這在金融、電信、保險、政府公共事業方面特別明顯,例如:我們曾經做過的稅務健康監測系統,每天都需要監測上百G的資料量,而這都是整個城市的公眾在一個稅務系統上進行稅務業務辦理所產生的龐大資料量,這就是大資料產生的一個重要因素,
大資料產生的另外一個因素就是城市基礎設施、人、水源河流、天氣環境、公路交通、工業設備、機房等活動狀態可監測的物件,通過(生物)傳感器、物聯網的技術手段,采集了大量基于時間線的感應資料,這些資料最大的特征在于資料長期是穩定的走勢,但是恰恰不穩定的資料是需要被重點監測,以達到及時預防,防止故障與災難,因此我們可以理解這些資料大多數是低價值的,只有少量變異資料和具有挖掘出潛在關聯關系的資料卻又具有極高的價值,這個特色還特別體現在股票方面,例如:通過多支股票的走勢進行資料挖掘,從它們的歷史峰值和谷底中找到相似性的走勢,再從相似性走勢中預測可能發生的概率,
大資料技術描述
我們在上面的概述中其實心里就應該很清楚傳統RDBMS資料庫是難以支撐大資料場景,那么到底有哪些技術屬于大資料技術,這些技術又起到什么作用呢?
回答這個問題之前,我們需要先搞清楚解決大資料業務需要的流程和步驟,在這個問題上的復雜度已經遠遠超過了傳統資料庫處理的場景,我們上面提到過傳統資料庫主要就是支撐在線業務資料的查詢、寫入和更新,但是大資料業務需要考慮的主要流程就是:采集、資料流處理、資料管道、存盤、搜索、挖掘分析、查詢服務和分析展示等
下圖是個比較典型的大資料采集、傳輸、存盤和分析的示意圖:
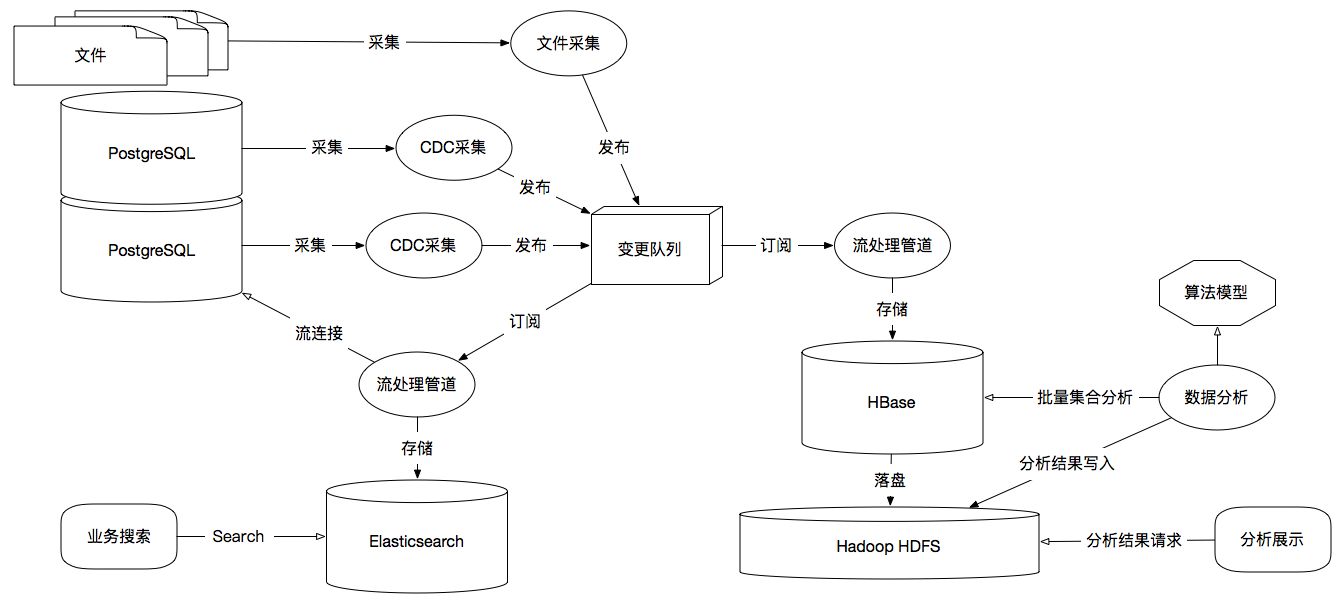
?大資料計算流程示意圖
在大資料中非常重要起點就是對于資料的采集,一般大資料主流程不會直接從用戶端的請求服務中進行計算,我們將這個領域定位為OLTP,也就是由傳統資料庫或支撐海量資料寫入的NoSQL來完成,然后我們通過采集工具從RDBMS、檔案或NoSQL中進行采集同步,例如上圖中:利用CDC(資料變更捕獲),我們可以從PostgreSQL的邏輯復制中捕獲WAL(預寫日志檔案)的資料變更,然后將變更資料發送到大資料平臺,也可以從檔案中采集獲取,常見的采集工具有ELK的Filebeat、Logstash采集檔案,Flume作為多源采集管道并集成HDFS,Canal采集MySQL Binlog,Flink CDC采集PostgresSQL WAL等,
資料流處理主要應用在資料傳輸實時性比較高的場景,我們常見的Flink、Storm、Spark Streaming都是為此場景而產生,在上圖中我們可以看到流處理管道,起到了資料傳輸程序中非常重要的資料轉換和資料寫入作用,它們還能在流傳輸的程序中進行流庫連接、流流連接進行二次加工,生成新的資料流,并在流轉的程序中進行實時資料采樣、過濾、轉換、封裝、清洗等多種實時處理操作,
資料流在中轉程序中往往需要緩沖進佇列,這在大資料的實時流處理中非常重要,例如:Kafka、RocketMQ,它們不僅形成了資料在上下游計算流轉程序中的資料持久化所帶來的資料可靠性,而且還能形成一對多的發布與訂閱的扇形資料流轉結構,這樣就可以一個資料為多個計算服務所用,如上圖中變更佇列一方面可以由搜索管道來訂閱,資料就流向了資料搜索引擎,另一方面可以由分析管道來訂閱,資料流就流向了OLAP平臺,另外佇列保持了發生情況的前后一致性,那么我們存盤的程序中就能輕松解決資料的時間線或事務問題,
大資料存盤需要根據資料所適用的場景進行多種情況的構建,如上圖中我們可以看到,若應用于搜索場景,那么最好的存盤就是搜索引擎,例如:Elasticsearch、Solr,這些資料庫都是典型的檔案型資料庫,基于檔案樹的結構存盤,并對檔案進行全文索引;若應用于OLAP場景,我們可以從圖中看到使用到了HBase分布式KV資料庫,它是完全遵循Google BigTable論文「PDF」的開源實作,基于列簇格式存盤,行鍵排序,形成一個非常寬大的稀疏表,非常適合做在線統計處理和離線資料挖掘,
例如:我們前面提到的微博問題,對于HBase來說,一個行鍵、兩個列簇、千萬級稀疏列,明星(行鍵)、粉絲集合(列簇)、粉絲(列)或者明星(行鍵)、發布集合(列簇)、發布微博(列),我們總能快速的通過明星ID,掃描他的粉絲集合,獲取千萬粉絲進行推送,粉絲也能通過明星ID,定位到他的微博發布集合,快速找到最新發布的微博,這僅僅是面向高并發的實時聚合查詢的一個案例,
上圖中我們可以通過HBase完全承載PostgreSQL的結構化資料,還能通過資料管道結構化檔案資料,在HBase列簇中形成統一的資料結構,上圖的目的是從PostgreSQL中采集到車輛資料,檔案中采集到車輛運行中的坐標資料,那么HBase中就能以車輛資料為行鍵,坐標資料為列簇與列,可以進一步分析不同時間點不同路段的擁堵情況,
同時我們從上圖中可以看到HBase只是分布式的資料庫引擎,真正資料落盤在了Hadoop HDFS,它是分布式檔案系統,基于Google GFS 論文「PDF」的開源實作,提供了資料塊的高可靠存盤,
資料分析程序主要是分布式資料庫海量資料的批量資料挖掘,我們往往需要一些支持MPP(大規模并行處理)的分布式計算框架來解決,例如:Spark、MapReduce、Tez、Hive、Presto等,這些處理引擎主要是以集群化的分布式并行計算將資料切分成多任務來解決,這樣再超大規模的資料集合都可以被更多的計算節點切分而快速完成,
那么基于Spark的這樣的大資料技術堆疊進行預測分析,就有了Spark MLlib這樣的機器學習模型庫,例如:我們要通過對一組海量進行一項顧客風險評測訓練,預測某一位顧客購買某項保險項未來出現賠付的概率,那么就能通過MLlib的DecisionTree(決策樹)演算法,不斷調整訓練引數,去熵提純集合,找到最佳的預測模型,
總結
作為大資料的應用與價值非常廣泛,我們上面只是大資料整個生態體系的冰山一角,比如說:通過對廣告投放資料的采集并寫入時序資料庫(TSDB),我們可以非常快速地在每秒百億次的點擊中,分析出每分鐘每個投放網站的收益,投放平臺為每個廣告顧客創造的投放次數、展示次數、廣告瀏覽時長等;
再比如說:我們通過日志資料跟蹤,能將上千臺服務器的日志進行分布式Track,那么我就能實時分析出一筆業務需要經歷多少臺服務器,經歷了多少服務轉發,在哪些服務上出現了延時,從而達到快速運維感知,尤其是面向公共事業、互聯網電商、互聯網金融無法容忍分鐘級的故障導致的系統不可用,實時運維感知的作用就是剛性需求,
談到信用卡機構、銀行、保險行業,最重要的一項分析就是對顧客群體的預測分析,這在防欺詐、信用評級、貸款方面可以說大資料應用起到了無可替代的作用,我們需要通過資料挖掘、機器學習,將碎片化的不同資料集合,進行搜集、清洗、完善,建立資料分析演算法模型,不斷通過對海量資料的分析,引數優化,從資料中發現隱藏的關系,預測個體行為概率,
?本文來自博客園,作者:守護石,轉載請注明原文鏈接:https://www.cnblogs.com/readbyte/p/16246786.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/470680.html
標籤:其他