我想給我的示例資料列名稱。我希望這些列以目標函式及其決策變數命名,如下所示:f_1、f_2、h、b、l、t
樣本資料:
sampler = qmc.LatinHypercube(d=4)
u_bounds = np.array([5.0, 5.0, 10.0, 10.0])
l_bounds = np.array([0.125, 0.125, 0.1, 0.1])
data = sampler.lhs_method(100)*(u_bounds-(l_bounds)) (l_bounds)
列名來自哪里的優化問題:
def objectives (h,b,l,t):
f1 = 1.10471*(h**2)*l 0.04811*t*b*(14.0 l)
f2 = 2.1952 / (t**3)*b
return f1,f2
為目標函式塑造資料:
y=np.zeros((100,2))
for i in range(np.shape(data)[0]):
y[i,0], y[i,1] = objectives(data[i,0], data[i,1], data[i,2], data[i,3])
我嘗試了什么:
df = pd.DataFrame(data=data)
df.columns = ["h", "b", "l", "t"]
df.head()
frames = [df, y,]
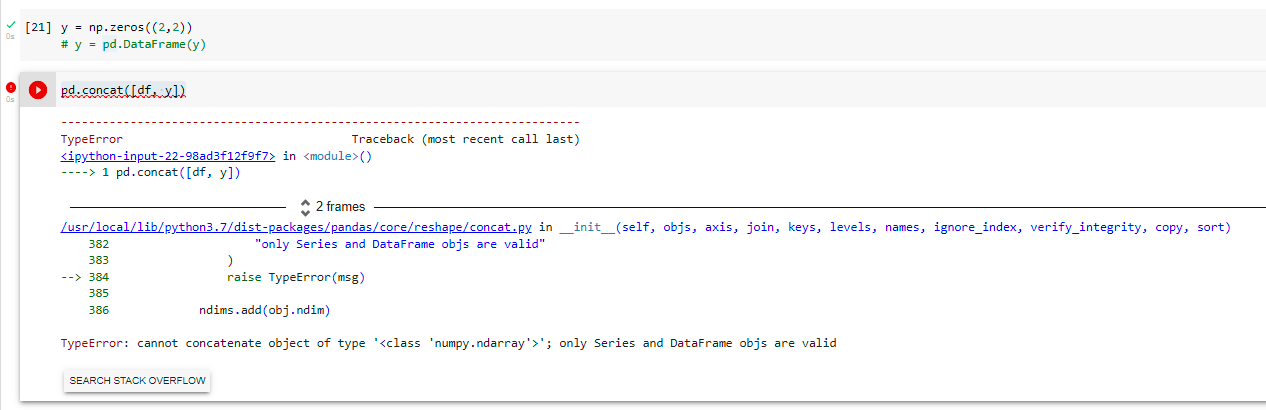
result = pd.concat(frames)
這個錯誤是這樣的:TypeError: cannot concatenate object of type '<class 'numpy.ndarray'>'; only Series and DataFrame objs are valid
那么對于這個問題,你會推薦什么樣的修改呢?現在看來,這兩個資料幀的當前形式不兼容。
uj5u.com熱心網友回復:
如果您希望它們“并排”,您可以執行以下操作:
df = pd.DataFrame(data=data)
df.columns = ["h", "b", "l", "t"]
# Adding new colummns from variable y
df['f1'] = y[:,0]
df['f2'] = y[:,1]
# Quick check
df.head()
DataFrames 表示表格資料。您可以將它們視為列串列,其中每列都有一個名稱(f1、f2、h、b...),并且可以通過my_dataframe['column_name'].
uj5u.com熱心網友回復:
就像錯誤所說的那樣,您不能concat使用帶有 numpy 陣列的資料框。
因此,您應該將 y(numpy 陣列)轉換為 df 以與另一個 df 連接:
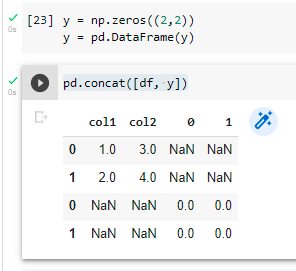
y = np.zeros((2,2))
y = pd.DataFrame(y) #this
pd.concat([df, y])
重現錯誤:
解決:
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/486571.html
下一篇:如何從資料框中洗掉一組特定行?