我有一個像這樣的熊貓資料框:
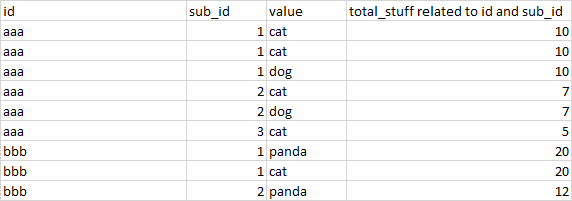
作為純文本:
{'id;sub_id;value;與id和sub_id相關的total_stuff': ['aaa;1;cat;10', 'aaa;1;cat;10', 'aaa;1;dog;10', 'aaa; 2;cat;7', 'aaa;2;dog;7', 'aaa;3;cat;5', 'bbb;1;panda;20', 'bbb;1;cat;20', 'bbb; 2;熊貓;12']}
我想要的輸出是這個。
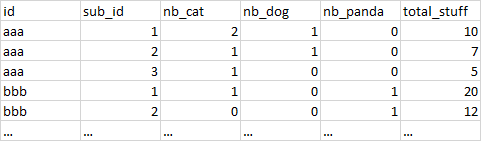
請注意,可能有許多不同的“值”,因此我需要自動創建虛擬變數(nb_animals)。但是這些虛擬變數必須包含 id 和 sub_id 的出現次數。對于給定的 id/sub_id 組合,total_stuff 始終是相同的值。
我試過使用get_dummies(df, columns = ['value']),它給了我這張桌子。
使用 get_dummies
作為純文本:
{'id;sub_id;value_cat;value_dog;value_panda;total_stuff 與 id 和 sub_id 相關': ['aaa;1;2;1;0;10', 'aaa;1;2;1;0;10', ' aaa;1;2;1;0;10', 'aaa;2;1;1;0;7', 'aaa;2;1;1;0;7', 'aaa;3;1;0; 0;5','bbb;1;1;0;1;20','bbb;1;1;0;1;20','bbb;2;0;0;1;12']}
我很想使用某種df.groupby(['id','sub_id']).agg({'value_cat':'sum', 'value_dog':'sum', ... , 'total_stuff':'mean'}),但是寫出所有可能的動物值太乏味了。
那么如何獲得正確的聚合計數/總和,以及 total_stuff 的平均值(因為每個 id/sub_id 組合的 total_stuff 是唯一的)
謝謝
編輯:感謝 chikich 的簡潔答案。agg_dict 是我需要的
uj5u.com熱心網友回復:
用于pd.get_dummies轉換分類資料
df = pd.get_dummies(df, prefix='nb', columns='value')
然后按 id 和 subid 分組
agg_dict = {key: 'sum' for key in df.columns if key[:3] == 'nb_'}
agg_dict['total_stuff'] = 'mean'
df = df.groupby(['id', 'subid']).agg(agg_dict).reset_index()
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/486548.html