LyScript 插件提供的反匯編系列函式雖然能夠實作基本的反匯編功能,但在實際使用中,可能會遇到一些更為復雜的需求,此時就需要根據自身需要進行二次開發,以實作更加高級的功能,本章將繼續深入探索反匯編功能,并將介紹如何實作反匯編代碼的檢索、獲取上下一條代碼等功能,這些功能對于分析和除錯代碼都非常有用,因此是書中重要的內容之一,在本章的學習程序中,讀者不僅可以掌握反匯編的基礎知識和技巧,還能夠了解如何進行插件的開發和除錯,這對于提高讀者的技能和能力也非常有幫助,
4.10.1 搜索記憶體機器碼特征
首先我們來實作第一種需求,通過LyScript插件實作搜索記憶體中的特定機器碼,此功能當然可通過scan_memory_all()系列函式實作,但讀者希望你能通過自己的理解呼叫原生API介面實作這個需求,要實作該功能第一步則是需要封裝一個GetCode()函式,該函式的作用是讀取行程資料到記憶體中,
其中dbg.get_local_base()用于獲取當前行程內的首地址,而通過start_address + dbg.get_local_size()的方式則可獲取到該程式的結束地址,當確定了讀取范圍后再通過dbg.read_memory_byte(index)回圈即可將程式的記憶體資料讀入,而ReadHexCode()僅僅只是一個格式化函式,這段程式的核心代碼可以總結為如下樣子;
# 將可執行檔案中的單數轉換為 0x00 格式
def ReadHexCode(code):
hex_code = []
for index in code:
if index >= 0 and index <= 15:
#print("0" + str(hex(index).replace("0x","")))
hex_code.append("0" + str(hex(index).replace("0x","")))
else:
hex_code.append(hex(index).replace("0x",""))
#print(hex(index).replace("0x",""))
return hex_code
# 獲取到記憶體中的機器碼
def GetCode():
try:
ref_code = []
dbg = MyDebug()
connect_flag = dbg.connect()
if connect_flag != 1:
return None
start_address = dbg.get_local_base()
end_address = start_address + dbg.get_local_size()
# 回圈得到機器碼
for index in range(start_address,end_address):
read_bytes = dbg.read_memory_byte(index)
ref_code.append(read_bytes)
dbg.close()
return ref_code
except Exception:
return False
接著則需要讀者封裝實作一個SearchHexCode()搜索函式,如下這段代碼實作了在給定的位元組陣列中搜索特定的十六進制特征碼的功能,
具體而言,函式接受三個引數:Code表示要搜索的位元組陣列,SearchCode表示要匹配的特征碼,ReadByte表示要搜索的位元組數,
函式首先獲取特征碼的長度,并通過一個for回圈遍歷給定位元組陣列中的所有可能匹配的位置,對于每個位置,函式獲取該位置及其后面SearchCount個位元組的十六進制表示形式,并將其與給定的特征碼進行比較,如果有一位不匹配,則計數器重置為0,否則計數器加1,如果計數器最終等于特征碼長度,則說明已找到完全匹配的特征碼,函式回傳True,如果遍歷完整個陣列都沒有找到匹配的特征碼,則函式回傳False,
# 在位元組陣列中匹配是否與特征碼一致
def SearchHexCode(Code,SearchCode,ReadByte):
SearchCount = len(SearchCode)
#print("特征碼總長度: {}".format(SearchCount))
for item in range(0,ReadByte):
count = 0
# 對十六進制數切片,每次向后遍歷SearchCount
OpCode = Code[ 0+item :SearchCount+item ]
#print("切割陣列: {} --> 對比: {}".format(OpCode,SearchCode))
try:
for x in range(0,SearchCount):
if OpCode[x] == SearchCode[x]:
count = count + 1
#print("尋找特征碼計數: {} {} {}".format(count,OpCode[x],SearchCode[x]))
if count == SearchCount:
# 如果找到了,就回傳True,否則回傳False
return True
exit(0)
except Exception:
pass
return False
有了這兩段程式的實作流程,那么完成特征碼搜索功能將變得很容易實作,如下主函式中運行后則可搜索行程內search中所涉及到的機器碼,當搜索到后則回傳一個狀態,
if __name__ == "__main__":
# 讀取到記憶體機器碼
ref_code = GetCode()
if ref_code != False:
# 轉為十六進制
hex_code = ReadHexCode(ref_code)
code_size = len(hex_code)
# 指定要搜索的特征碼序列
search = ['c0', '74', '0d', '66', '3b', 'c6', '77', '08']
# 搜索特征: hex_code = exe的位元組碼,search=搜索特征碼,code_size = 搜索大小
ret = SearchHexCode(hex_code, search, code_size)
if ret == True:
print("特征碼 {} 存在".format(search))
else:
print("特征碼 {} 不存在".format(search))
else:
print("讀入失敗")
由于此類搜索屬于列舉類,所以搜索效率會明顯變低,搜索結束后則會回傳該特征值是否存在的一個標志;

4.10.2 搜索記憶體反匯編特征
而與之對應的,當讀者搜索反匯編代碼時則無需自行實作記憶體讀入功能,LyScript插件內提供了dbg.get_disasm_code(eip,1000)函式,可以讓我們很容易的實作讀取記憶體的功能,如下案例中,搜索特定反匯編指令集,當找到后回傳其記憶體地址;
from LyScript32 import MyDebug
# 檢索指定序列中是否存在一段特定的指令集
def SearchOpCode(OpCodeList,SearchCode,ReadByte):
SearchCount = len(SearchCode)
for item in range(0,ReadByte):
count = 0
OpCode_Dic = OpCodeList[ 0 + item : SearchCount + item ]
# print("切割字典: {}".format(OpCode_Dic))
try:
for x in range(0,SearchCount):
if OpCode_Dic[x].get("opcode") == SearchCode[x]:
#print(OpCode_Dic[x].get("addr"),OpCode_Dic[x].get("opcode"))
count = count + 1
if count == SearchCount:
#print(OpCode_Dic[0].get("addr"))
return OpCode_Dic[0].get("addr")
exit(0)
except Exception:
pass
if __name__ == "__main__":
dbg = MyDebug()
connect_flag = dbg.connect()
print("連接狀態: {}".format(connect_flag))
# 得到EIP位置
eip = dbg.get_register("eip")
# 反匯編前1000行
disasm_dict = dbg.get_disasm_code(eip,1000)
# 搜索一個指令序列,用于快速查找構建漏洞利用代碼
SearchCode = [
["ret", "push ebp", "mov ebp,esp"],
["push ecx", "push ebx"]
]
# 檢索記憶體指令集
for item in range(0,len(SearchCode)):
Search = SearchCode[item]
# disasm_dict = 回傳匯編指令 Search = 尋找指令集 1000 = 向下檢索長度
ret = SearchOpCode(disasm_dict,Search,1000)
if ret != None:
print("指令集: {} --> 首次出現地址: {}".format(SearchCode[item],hex(ret)))
dbg.close()
如上代碼當搜尋到SearchCode內的指令序列時則自動輸出記憶體地址,輸出效果圖如下所示;

4.10.3 獲取上下一潭訓編指令
LyScript 插件默認并沒有提供上一條與下一潭訓編指令的獲取功能,筆者認為通過親自動手封裝實作功能能夠讓讀者更好的理解記憶體斷點的作業原理,則本次我們將親自動手實作這兩個功能,
在x64dbg中,軟體斷點的實作原理與通用的軟體斷點實作原理類似,具體來說,x64dbg會在程式的指令地址處插入一個中斷指令,一般是int3指令,這個指令會觸發一個軟體中斷,從而讓程式停止執行,等待除錯器處理,在插入中斷指令之前,x64dbg會先將這個地址處的原始指令保存下來,這樣,當程式被除錯器停止時,除錯器就可以將中斷指令替換成原始指令,讓程式恢復執行,
為了實作軟體斷點,x64dbg需要修改程式的可執行代碼,具體來說,它會將指令的第一個位元組替換成中斷指令的操作碼,這樣當程式執行到這個指令時就會觸發中斷,如果指令長度不足一個位元組,x64dbg會將這個指令轉換成跳轉指令,跳轉到另一個地址,然后在這個地址處插入中斷指令,
此外在除錯器中設定軟體斷點時,x64dbg會根據指令地址的特性來判斷是否可以設定斷點,如果指令地址不可執行,x64dbg就無法在這個地址處設定斷點,另外,由于軟體斷點會修改程式的可執行代碼,因此在某些情況下,設定過多的軟體斷點可能會影響程式的性能,
讀者注意:實作獲取下一潭訓編指令的獲取,需要注意如果是被命中的指令,則此處應該是
CC斷點占用一個位元組,如果不是則正常獲取到當前指令即可,
- 1.我們需要檢查當前記憶體斷點是否被命中,如果沒有命中則說明,此處需要獲取到原始的匯編指令長度,然后與當前eip地址相加獲得,
- 2.如果命中了斷點,則此處又會兩種情況,如果是用戶下的斷點,則此處除錯器會在指令位置替換為
CC斷點,也就是匯編中的init停機指令,該指令占用1個位元組,需要eip+1得到,而如果是系統斷點,EIP所停留的位置,則我們需要正常獲取當前指令地址,此處除錯器沒有改動匯編指令,僅僅只下了例外斷點,
from LyScript32 import MyDebug
# 獲取當前EIP指令的下一條指令
def get_disasm_next(dbg,eip):
next = 0
# 檢查當前記憶體地址是否被下了絆子
check_breakpoint = dbg.check_breakpoint(eip)
# 說明存在斷點,如果存在則這里就是一個位元組了
if check_breakpoint == True:
# 接著判斷當前是否是EIP,如果是EIP則需要使用原來的位元組
local_eip = dbg.get_register("eip")
# 說明是EIP并且命中了斷點
if local_eip == eip:
dis_size = dbg.get_disasm_operand_size(eip)
next = eip + dis_size
next_asm = dbg.get_disasm_one_code(next)
return next_asm
else:
next = eip + 1
next_asm = dbg.get_disasm_one_code(next)
return next_asm
return None
# 不是則需要獲取到原始匯編代碼的長度
elif check_breakpoint == False:
# 得到當前指令長度
dis_size = dbg.get_disasm_operand_size(eip)
next = eip + dis_size
next_asm = dbg.get_disasm_one_code(next)
return next_asm
else:
return None
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
eip = dbg.get_register("eip")
next = get_disasm_next(dbg,eip)
print("下一條指令: {}".format(next))
prev = get_disasm_next(dbg,4584103)
print("下一條指令: {}".format(prev))
dbg.close()
如上代碼則是顯現設定斷點的核心指令集,讀者可自行測驗是否可讀取到當前指令的下一條指令,其輸出效果如下圖所示;
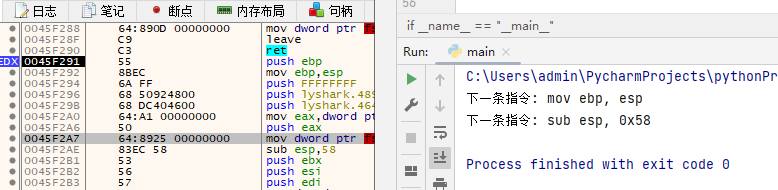
讀者注意:獲取上一潭訓編指令時,由于上一條指令的獲取難點就在于,我們無法確定當前指令的上一條指令到底有多長,所以只能用笨辦法,逐行掃描對比匯編指令,如果找到則取出其上一條指令即可,
from LyScript32 import MyDebug
# 獲取當前EIP指令的上一條指令
def get_disasm_prev(dbg,eip):
prev_dasm = None
# 得到當前匯編指令
local_disasm = dbg.get_disasm_one_code(eip)
# 只能向上掃描10行
eip = eip - 10
disasm = dbg.get_disasm_code(eip,10)
# 回圈掃描匯編代碼
for index in range(0,len(disasm)):
# 如果找到了,就取出他的上一個匯編代碼
if disasm[index].get("opcode") == local_disasm:
prev_dasm = disasm[index-1].get("opcode")
break
return prev_dasm
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
eip = dbg.get_register("eip")
next = get_disasm_prev(dbg,eip)
print("上一條指令: {}".format(next))
dbg.close()
運行后即可讀入當前EIP的上一條指令位置處的反匯編指令,輸出效果如下圖所示;

原文地址
https://www.lyshark.com/post/b62cec0e.html
文章作者:lyshark (王瑞)文章出處:https://www.cnblogs.com/LyShark/p/17542824.html
本博客所有文章除特別宣告外,均采用 BY-NC-SA 許可協議,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/557046.html
標籤:其他
下一篇:返回列表