我正在嘗試創建一個函式來發現標題中帶有“100”的列,并將這些列中大于 100 的所有值替換為 nan 值:
import pandas as pd
data = {'first_100': ['25', '1568200', '5'],
'second_column': ['first_value', 'second_value', 'third_value'],
'third_100':['89', '9', '589'],
'fourth_column':['first_value', 'second_value', 'third_value'],
}
df = pd.DataFrame(data)
print (df)

所以這是我正在尋找的輸出
uj5u.com熱心網友回復:
使用,filter標識列以確保具有數值,然后使用布爾陣列:'100'to_numericmask
cols = df.filter(like='100').columns
df[cols] = df[cols].mask(df[cols].apply(pd.to_numeric, errors='coerce').gt(100))
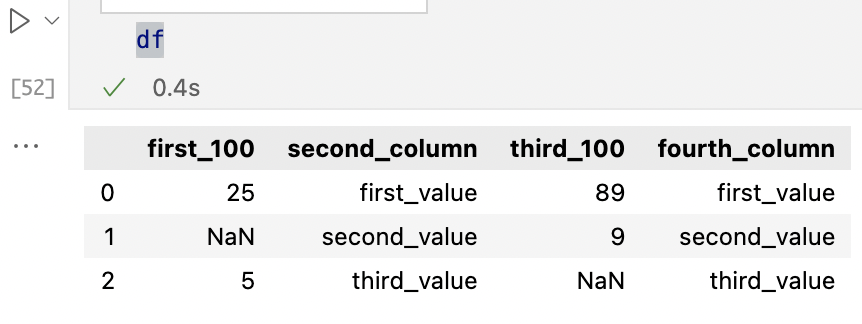
輸出:
first_100 second_column third_100 fourth_column
0 25 first_value 89 first_value
1 NaN second_value 9 second_value
2 5 third_value NaN third_value
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/506850.html