前言
該篇是之前遺漏的大三上的Python課程設計,剛好今天有空就補發了一篇文章,全部的代碼在最后附錄中,爬蟲類的代碼直接全部放到一起了,讀者可以自行研究,
百度網盤鏈接鏈接:https://pan.baidu.com/s/1sQPMbO-sy2_QqQHyMtTmUg 提取碼:mx10
一、課程設計專案說明
該課程設計專案“利用爬蟲獲取NBA資料資訊并進行機器學習預測NBA比賽結果”的原型是基于網上一個教程網站“實驗樓”中的專案“使用 Python 進行 NBA 比賽資料分析”,原專案是利用Python進行對NBA的資料機器學習進行預測,在原專案之上,我對專案做出了如下更新:
1、使用Python爬蟲爬取NBA官網中的每一年的季后賽常規賽等部分專案中需要的比賽統計資料并輸出成csv格式的檔案,避免像原專案一樣,全部比賽資料需要自己從NBA網站中復制黏貼到txt文本上然后更改后綴名為csv得到資料,能夠減輕獲取資料的繁瑣作業量,
(注:原專案網站鏈接:https://www.lanqiao.cn/courses/782/learning/?id=2647)
2、對原專案代碼結合了網上資料進行自主學習,并對原專案代碼進行了改進優化,
二、課程設計專案功能
首先可通過Python爬蟲獲取來自NBA官網的任意年度的球隊資料,保存在本地檔案夾后,更改名為“NBA-nwz”的代碼中的路徑folder為資料檔案路徑,即可匯入球隊各類資料而后進行特征向量、邏輯回歸、球隊的EloScore計算等機器學習,最終將預測的比賽結果輸出到特定路徑下的格式為.csv的檔案查看比賽預測結果,
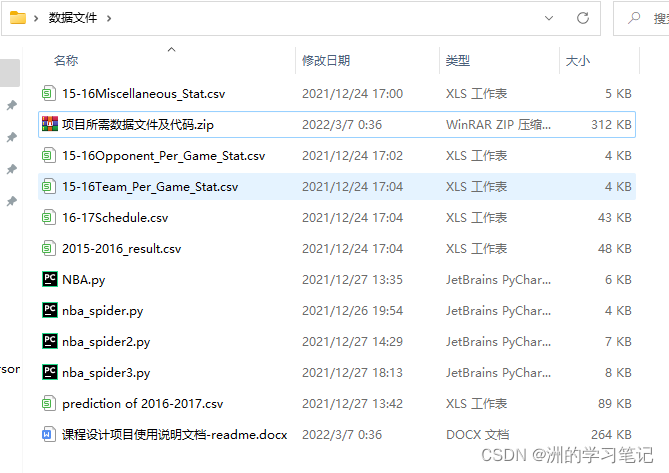
三、專案所需資料檔案
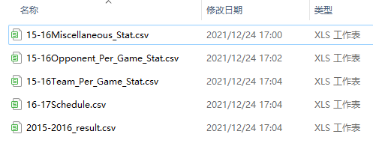
本專案中一共需要5張資料表,分別是Team Per Ganme Stats(各球隊每場比賽資料統計)、Opponent Per Game Stats(對手平均平常比賽的資料統計)、Miscellaneous Stats(各球隊綜合統計資料表)、2015-2016 NBA Schedule and Results(2015-16賽季比賽安排與結果)、2016-2017 NBA Schedule and Results(2016-2015賽季比賽安排),
四、專案原理介紹
1、比賽資料介紹
本專案中,采用來自與NBA網站的資料,在該網站中,可以獲取到任意球隊、任意球員的各類比賽統計資料,如得分、投籃次數、犯規次數等等,
(注:NBA網站鏈接https://www.basketball-reference.com/)
在本網站中,主要使用2015-16賽季中的資料,分別是:
Team Per Ganme Stats表格:每支隊伍平均每場比賽的表現統計;
Opponent Per Game Stats表格:所遇到的對手平均每場比賽的統計資訊,所包含的統計資料與 Team Per Game Stats 中的一致,只是代表的是該球隊對應的對手的統計資訊;
Miscellaneous Stats:綜合統計資料,(在網站中名為Advanced Stats,)
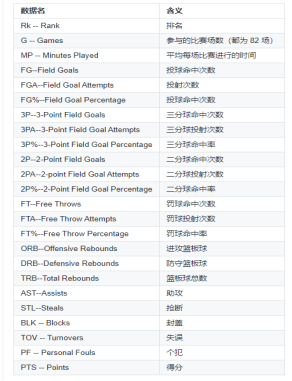
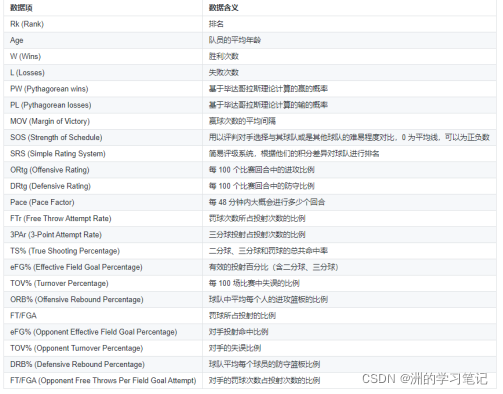
Team Per Game Stats表格、Opponent Per Game Stats表格、Miscellaneous Stats表格(在NBA網站中叫做“Advanced Stats”)中的資料欄位含義如下圖所示,
除了上述的三張表外,還需要另外兩張表資料,分別是:
2015-2016 NBA Schedule and Results:2015-2016 年的 NBA 常規賽及季后賽的每場比賽的比賽資料;2016-2017 NBA Schedule and Results 中 2016-2017 年的 NBA 的常規賽比賽安排資料,
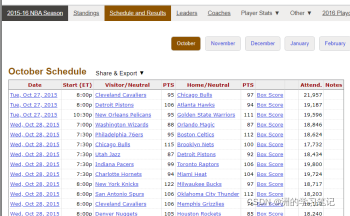
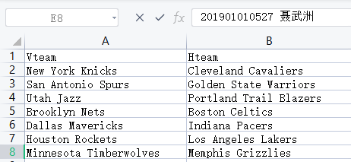
在獲取到資料之后,需要對表格的欄位做出更改如下圖所示,
表格資料欄位含義說明:Vteam: 客場作戰隊伍,Hteam: 主場作戰隊伍
故綜上所述一共需要5張NBA資料表,如下圖所示,
2、資料分析原理
在獲取到五個表格資料之后,將利用每支隊伍過去的比賽情況和 Elo 等級分來分析每支比賽隊伍的勝利概率,
分析與評價每支隊伍過去的比賽表現時,將使用到上述五張表中的三張表,分別是 Team Per Game Stats、Opponent Per Game Stats 和 Miscellaneous Stats(后文中將簡稱為 T、O 和 M 表),
這三個表格的資料,作為代表比賽中某支隊伍的比賽特征,代碼將實作針對每場比賽,預測哪支隊伍最侄訓勝,但這并不是給出絕對的勝敗情況,而是預判勝利的隊伍有多大的獲勝概率,
因此將建立一個代表比賽的特征向量,由兩支隊伍的以往比賽統計情況(T、O 和M表)和兩個隊伍各自的 Elo 等級分構成,
3、Elo Score等級分制度
Elo 機制現在廣泛運用于網路游戲或競技類運動中,根據Elo等級分制度對各個選手(玩家)進行登記劃分,如王者榮耀、籃球、足球比賽等等,Elo Score等級分制度本身是國際象棋中基于統計學的一個評估棋手水平能力的方法,
通過Elo制度來計算選手(玩家)的勝率期望值的原理程序如下:
假設A與B當前的等級制度分為與,那么A對B的勝率期望值為:
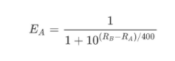
B對A的勝率期望值為:

如果A在比賽中真實得分與他的勝率期望值不同,那么A的等級分要根據以下公式進行調整:
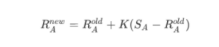
另外在國際象棋中,根據等級分的不同 K 值也會做相應的調整:大于等于2400,K=16,2100-2400 分,K=24,小于等于2100,K=32,
在專案中,將會用以表示某場比賽資料的特征向量為:
[A隊 Elo score,A隊的 T,O和M 表統計資料,B隊 Elo score, B隊的 T,O和M 表統計資料],
4、機器學習
對于全部隊伍,在最開始沒有Elo分數時,賦予初始值init_elo=1600,然后根據資料計算每支球隊Elo等級分,代碼如下圖所示:

而后根據資料表中的資料,及每支隊伍的Elo計算結果,建立對應的2015-2016年常規賽和季后賽中每場比賽的資料集,因為NBA中有主客場制度,所以在比賽時,認為主場作戰的隊伍更加有優勢,因此會在代碼中加上100的等級分,

而后在main函式呼叫上述函式方法,且使用sklearn的Logistic Regression方法建立回歸模型,
Logistic Regression(邏輯回歸)方法:
邏輯回歸:一種用于解決二分類(0 or 1)問題的機器學習方法,用于估計某種事物的可能性,比如某用戶購買某商品的可能性等,簡單的來說,就是學習我們設計好的向量資料,從中得到一個概率模型,然后輸入其他資料,就能根據訓練出來的模型得到其結果,
接著使用通過10折交叉驗證計算訓練正確率,
10折交叉驗證(10-fold cross validation):
常用的測驗方法,將資料集分成十分,輪流將其中9份作為訓練資料,1份作為測驗資料,進行試驗,每次試驗都會得出相應的正確率(或差錯率),10次的結果的正確率(或差錯率)的平均值作為對演算法精度的估計,一般還需要進行多次10折交叉驗證(例如10次10折交叉驗證),再求其均值,作為對演算法準確性的估計,
最后使用訓練好的模型在2016-2017年的常規賽資料中進行預測,匯入16-17資料,就可以利用模型對一場新的比賽進行勝負的判斷,并且回傳勝率的概率,
五、專案實施
在原網站的教程中,需要將網頁的資料復制下來到txt文本上然后更改后綴名為.csv格式,比較繁瑣,
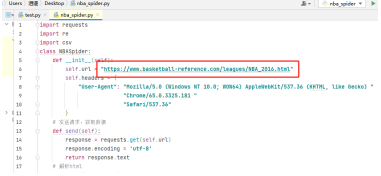
在課程設計中,我更新為以爬蟲獲取資料,這里以爬取Team Per Game表代碼為例,更改爬蟲代碼中的url代碼部分,運行即可爬取對應賽季的Team Per Ganme Stats(各球隊每場比賽資料統計)、Opponent Per Game Stats(對手平均平常比賽的資料統計)表格,而后將會自動將爬取的表格輸出為.csv檔案在爬蟲代碼的同路徑下,
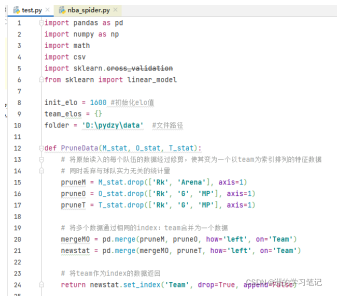
在“NBA-nwz.py”代碼中,設定好全部資料檔案的folder路徑,如下圖所示,(圖片中的py檔案名為test.py)然后運行代碼,即可獲得預測結果匯出了,
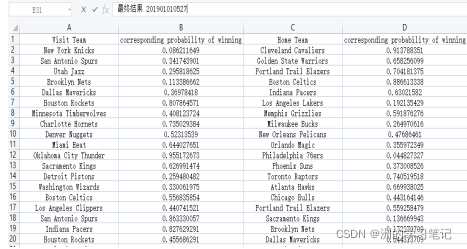
在匯出的檔案prediction of 2016-2017中可以看到如下預測資料,
六、專案總結
1、實驗程序問題總結
在寫代碼的時候,有一個包一直下載不了,各種報錯,根據網上的方法找了一個小時左右,試了很多種方法才解決掉,在這里記錄一下,起因就是這個parsel包import不了,一直會報同一個錯誤: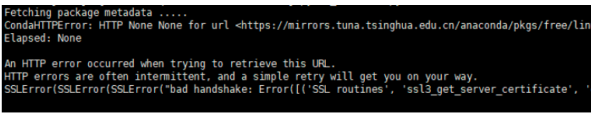
CondaHTTPError:HTTP 000 CONNECTION FAILED for url
https://mirrors.tuna.tsinghua.edu.cn/anaconda/.
應該是最開始自己安裝python環境的時候使用的anaconda沒有配置好,或者說這個源不起作用了,于是首先嘗試了第一種方法找到.condarc檔案,更改里面的channels通道地址,但是當我根據網上的指導教程換國科大、阿里等信號源后依然出現錯誤,
后面找到了一篇文章,說是需要將https://改為 http即可,剛看到的時候以為不是這個問題,后面實在是沒辦法了,被這個問題搞得頭大,一個多小時了卡著,只好死馬當活馬醫,更改了一下https為http,并配入了清華源的最新配置channels,沒想到解決了!
可以通過cmd命令 conda info查看自己的channels路徑配置,
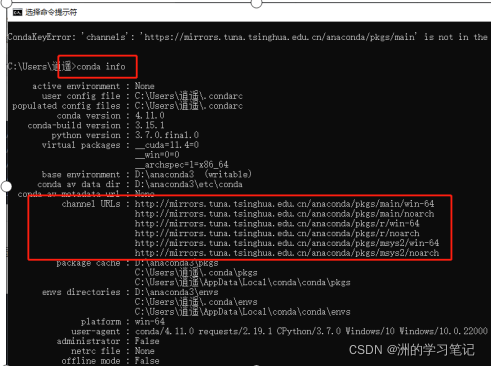
也可以通過在.condarc檔案直接更改即可,進行如下配置即可輕松擁有速度較快的安裝包速度了!

2、專案展望
總的來說,專案還是有一些小不足和繼續優化的,例如在5張表中,爬下來就可以立即使用的只有三張表,分別是 Team Per Game Stats、Opponent Per Game Stats 和 Miscellaneous Stats,另外爬下來的表格需要進行欄位處理,去掉不需要的欄位,并且更改欄位名等才能使用,而Python中是可以做到自動化處理資料欄位的,這一點沒有較好的實作,
除此之外,還可以使用Python可視化來做到更好的展示出比賽中兩個隊哪個勝率更高,
這一點我曾嘗試過,但是由于效果并不是很完美,就沒有放到設計專案中來,
以及在10折交叉驗證中,可以看出正確率接近70%左右,感徑訓可以在機器學習及資料處理(選用資料)方面再下一些功夫,達到更高的正確率,
因為機器學習是我自己課余時間學習過一點點的小教程,所以了解接觸并不是很深,做的并不是特別完善,有機會可以多更改,進一步完善優化,
附錄:全部代碼
進行預測的代碼:
import pandas as pd
import math
import numpy as np
import csv
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
init_elo = 1600 # 初始化elo值
team_elos = {}
folder = 'D:\pydzy\py-n' # 檔案路徑
def PruneData(M_stat, O_stat, T_stat):
#這個函式要完成的任務在于將原始讀入的諸多隊伍的資料經過修剪,使其變為一個以team為索引的排列的特征資料
#丟棄與球隊實力無關的統計量
pruneM = M_stat.drop(['Rk', 'Arena'],axis = 1)
pruneO = O_stat.drop(['Rk','G','MP'],axis = 1)
pruneT = T_stat.drop(['Rk','G','MP'],axis = 1)
#將多個資料通過相同的index:team合并為一個資料
mergeMO = pd.merge(pruneM, pruneO, how = 'left', on = 'Team')
newstat = pd.merge(mergeMO, pruneT, how = 'left', on = 'Team')
#將team作為index的資料回傳
return newstat.set_index('Team', drop = True, append = False)
def GetElo(team):
# 初始化每個球隊的elo等級分
try:
return team_elos[team]
except:
team_elos[team] = init_elo
return team_elos[team]
def CalcElo(winteam, loseteam):
# winteam, loseteam的輸入應為字串
# 給出當前兩個隊伍的elo分數
R1 = GetElo(winteam)
R2 = GetElo(loseteam)
# 計算比賽后的等級分,參考elo計算公式
E1 = 1/(1 + math.pow(10,(R2 - R1)/400))
E2 = 1/(1 + math.pow(10,(R1 - R2)/400))
if R1>=2400:
K=16
elif R1<=2100:
K=32
else:
K=24
R1new = round(R1 + K*(1 - E1))
R2new = round(R2 + K*(0 - E2))
return R1new, R2new
def GenerateTrainData(stat, trainresult):
#將輸入構造為[[team1特征,team2特征],...[]...]
X = []
y = []
for index, rows in trainresult.iterrows():
winteam = rows['WTeam']
loseteam = rows['LTeam']
#獲取最初的elo或是每個隊伍最初的elo值
winelo = GetElo(winteam)
loseelo = GetElo(loseteam)
# 給主場比賽的隊伍加上100的elo值
if rows['WLoc'] == 'H':
winelo = winelo+100
else:
loseelo = loseelo+100
# 把elo當為評價每個隊伍的第一個特征值
fea_win = [winelo]
fea_lose = [loseelo]
# 添加我們從basketball reference.com獲得的每個隊伍的統計資訊
for key, value in stat.loc[winteam].iteritems():
fea_win.append(value)
for key, value in stat.loc[loseteam].iteritems():
fea_lose.append(value)
# 將兩支隊伍的特征值隨機的分配在每場比賽資料的左右兩側
# 并將對應的0/1賦給y值
if np.random.random() > 0.5:
X.append(fea_win+fea_lose)
y.append(0)
else:
X.append(fea_lose+fea_win)
y.append(1)
# 更新team elo分數
win_new_score, lose_new_score = CalcElo(winteam, loseteam)
team_elos[winteam] = win_new_score
team_elos[loseteam] = lose_new_score
# nan_to_num(x)是使用0代替陣列x中的nan元素,使用有限的數字代替inf元素
return np.nan_to_num(X),y
def GeneratePredictData(stat,info):
X=[]
#遍歷所有的待預測資料,將資料變換為特征形式
for index, rows in stat.iterrows():
#首先將elo作為第一個特征
team1 = rows['Vteam']
team2 = rows['Hteam']
elo_team1 = GetElo(team1)
elo_team2 = GetElo(team2)
fea1 = [elo_team1]
fea2 = [elo_team2+100]
#球隊統計資訊作為剩余特征
for key, value in info.loc[team1].iteritems():
fea1.append(value)
for key, value in info.loc[team2].iteritems():
fea2.append(value)
#兩隊特征拼接
X.append(fea1 + fea2)
#nan_to_num的作用:1將串列變換為array,2.去除X中的非數字,保證訓練器讀入不出問題
return np.nan_to_num(X)
if __name__ == '__main__':
# 設定匯入資料表格檔案的地址并讀入資料
M_stat = pd.read_csv(folder + '/15-16Miscellaneous_Stat.csv')
O_stat = pd.read_csv(folder + '/15-16Opponent_Per_Game_Stat.csv')
T_stat = pd.read_csv(folder + '/15-16Team_Per_Game_Stat.csv')
team_result = pd.read_csv(folder + '/2015-2016_result.csv')
teamstat = PruneData(M_stat, O_stat, T_stat)
X,y = GenerateTrainData(teamstat, team_result)
# 訓練網格模型
limodel = linear_model.LogisticRegression()
limodel.fit(X,y)
# 10折交叉驗證
print(cross_val_score(model, X, y, cv=10, scoring='accuracy', n_jobs=-1).mean())
# 預測
pre_data = pd.read_csv(folder + '/16-17Schedule.csv')
pre_X = GeneratePredictData(pre_data, teamstat)
pre_y = limodel.predict_proba(pre_X)
predictlist = []
for index, rows in pre_data.iterrows():
reslt = [rows['Vteam'], pre_y[index][0], rows['Hteam'], pre_y[index][1]]
predictlist.append(reslt)
# 將預測結果輸出保存為csv檔案
with open(folder+'/prediction of 2016-2017.csv', 'w',newline='') as f:
writers = csv.writer(f)
writers.writerow(['Visit Team', 'corresponding probability of winning', 'Home Team', 'corresponding probability of winning'])
writers.writerows(predictlist)
爬蟲代碼:
import requests
import re
import csv
from parsel import Selector
class NBASpider:
def __init__(self):
self.url = "https://www.basketball-reference.com/leagues/NBA_2021.html"
self.schedule_url = "https://www.basketball-reference.com/leagues/NBA_2016_games-{}.html"
self.advanced_team_url = "https://www.basketball-reference.com/leagues/NBA_2016.html"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 "
"Safari/537.36"
}
# 發送請求,獲取資料
def send(self, url):
response = requests.get(url, headers=self.headers, timeout=30)
response.encoding = 'utf-8'
return response.text
# 決議html
def parse(self, html):
team_heads, team_datas = self.get_team_info(html)
opponent_heads, opponent_datas = self.get_opponent_info(html)
return team_heads, team_datas, opponent_heads, opponent_datas
def get_team_info(self, html):
"""
通過正則從獲取到的html頁面資料中team表的表頭和各行資料
:param html 爬取到的頁面資料
:return: team_heads表頭
team_datas 串列內容
"""
# 1. 正則匹配資料所在的table
team_table = re.search('<table.*?id="per_game-team".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正則從table中匹配出表頭
team_head = re.search('<thead>(.*?)</thead>', team_table, re.S).group(1)
team_heads = re.findall('<th.*?>(.*?)</th>', team_head, re.S)
# 3. 正則從table中匹配出表的各行資料
team_datas = self.get_datas(team_table)
return team_heads, team_datas
# 決議opponent資料
def get_opponent_info(self, html):
"""
通過正則從獲取到的html頁面資料中opponent表的表頭和各行資料
:param html 爬取到的頁面資料
:return:
"""
# 1. 正則匹配資料所在的table
opponent_table = re.search('<table.*?id="per_game-opponent".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正則從table中匹配出表頭
opponent_head = re.search('<thead>(.*?)</thead>', opponent_table, re.S).group(1)
opponent_heads = re.findall('<th.*?>(.*?)</th>', opponent_head, re.S)
# 3. 正則從table中匹配出表的各行資料
opponent_datas = self.get_datas(opponent_table)
return opponent_heads, opponent_datas
# 獲取表格body資料
def get_datas(self, table_html):
"""
從tboday資料中決議出實際資料(去掉頁面標簽)
:param table_html 決議出來的table資料
:return:
"""
tboday = re.search('<tbody>(.*?)</tbody>', table_html, re.S).group(1)
contents = re.findall('<tr.*?>(.*?)</tr>', tboday, re.S)
for oc in contents:
rk = re.findall('<th.*?>(.*?)</th>', oc)
datas = re.findall('<td.*?>(.*?)</td>', oc, re.S)
datas[0] = re.search('<a.*?>(.*?)</a>', datas[0]).group(1)
datas.insert(0, rk[0])
# yield 宣告這個方法是一個生成器, 回傳的值是datas
yield datas
def get_schedule_datas(self, table_html):
"""
從tboday資料中決議出實際資料(去掉頁面標簽)
:param table_html 決議出來的table資料
:return:
"""
tboday = re.search('<tbody>(.*?)</tbody>', table_html, re.S).group(1)
contents = re.findall('<tr.*?>(.*?)</tr>', tboday, re.S)
for oc in contents:
rk = re.findall('<th.*?><a.*?>(.*?)</a></th>', oc)
datas = re.findall('<td.*?>(.*?)</td>', oc, re.S)
if datas and len(datas) > 0:
datas[1] = re.search('<a.*?>(.*?)</a>', datas[1]).group(1)
datas[3] = re.search('<a.*?>(.*?)</a>', datas[3]).group(1)
datas[5] = re.search('<a.*?>(.*?)</a>', datas[5]).group(1)
datas.insert(0, rk[0])
# yield 宣告這個方法是一個生成器, 回傳的值是datas
yield datas
def get_advanced_team_datas(self, table):
trs = table.xpath('./tbody/tr')
for tr in trs:
rk = tr.xpath('./th/text()').get()
datas = tr.xpath('./td[@data-stat!="DUMMY"]/text()').getall()
datas[0] = tr.xpath('./td/a/text()').get()
datas.insert(0, rk)
yield datas
def parse_schedule_info(self, html):
"""
通過正則從獲取到的html頁面資料中的表頭和各行資料
:param html 爬取到的頁面資料
:return: heads表頭
datas 串列內容
"""
# 1. 正則匹配資料所在的table
table = re.search('<table.*?id="schedule" data-cols-to-freeze=",1">(.*?)</table>', html, re.S).group(1)
table = table + "</tbody>"
# 2. 正則從table中匹配出表頭
head = re.search('<thead>(.*?)</thead>', table, re.S).group(1)
heads = re.findall('<th.*?>(.*?)</th>', head, re.S)
# 3. 正則從table中匹配出表的各行資料
datas = self.get_schedule_datas(table)
return heads, datas
def parse_advanced_team(self, html):
"""
通過xpath從獲取到的html頁面資料中表頭和各行資料
:param html 爬取到的頁面資料
:return: heads表頭
datas 串列內容
"""
selector = Selector(text=html)
# 1. 獲取對應的table
table = selector.xpath('//table[@id="advanced-team"]')
# 2. 從table中匹配出表頭
res = table.xpath('./thead/tr')[1].xpath('./th/text()').getall()
heads = []
for i, head in enumerate(res):
if '\xa0' in head:
continue
heads.append(head)
# 3. 匹配出表的各行資料
table_data = self.get_advanced_team_datas(table)
return heads, table_data
# 存盤成csv檔案
def save_csv(self, title, heads, rows):
f = open(title + '.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(heads)
for row in rows:
csv_writer.writerow(row)
f.close()
def crawl_team_opponent(self):
# 1. 發送請求
res = self.send(self.url)
# 2. 決議資料
team_heads, team_datas, opponent_heads, opponent_datas = self.parse(res)
# 3. 保存資料為csv
self.save_csv("team", team_heads, team_datas)
self.save_csv("opponent", opponent_heads, opponent_datas)
def crawl_schedule(self):
months = ["october", "november", "december", "january", "february", "march", "april", "may", "june"]
for month in months:
html = self.send(self.schedule_url.format(month))
# print(html)
heads, datas = self.parse_schedule_info(html)
# 3. 保存資料為csv
self.save_csv("schedule_"+month, heads, datas)
def crawl_advanced_team(self):
# 1. 發送請求
res = self.send(self.advanced_team_url)
# 2. 決議資料
heads, datas = self.parse_advanced_team(res)
# 3. 保存資料為csv
self.save_csv("advanced_team", heads, datas)
def crawl(self):
# 1. 爬取各隊伍資訊
# self.crawl_team_opponent()
# 2. 爬取計劃表
# self.crawl_schedule()
# 3. 爬取Advanced Team表
self.crawl_advanced_team()
if __name__ == '__main__':
# 運行爬蟲
spider = NBASpider()
spider.crawl()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/439202.html
標籤:AI