可能看過看過我上兩篇GAN和CGAN的朋友們都認為,mnist資料太簡單了,也不太適合拿出去show,所以我們來一個復雜一點的,這次難度比之前兩篇的難度又有所提升了,所以,請大家不要慌張,緊跟腳步,我們來開整,
3.PIX2PIX
3.1PIX2PIX的網路結構
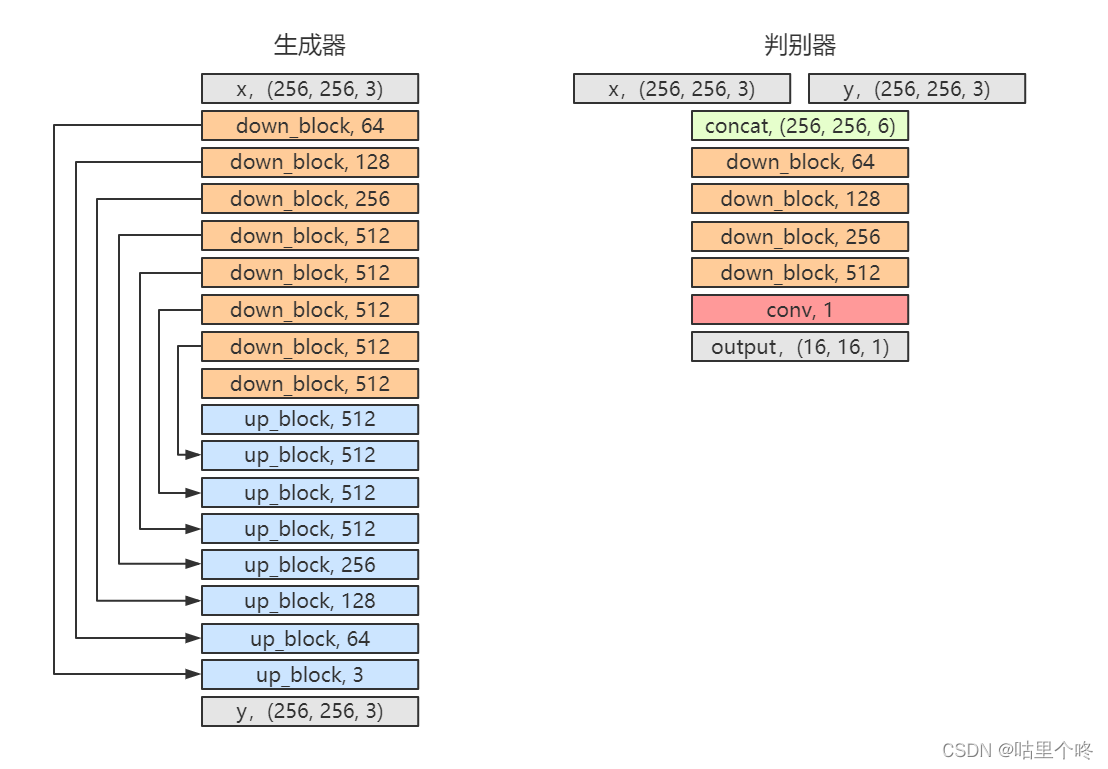
可以看到仍然是兩個網路:生成器和判別器
不同的是:
1.生成器這次變樣子了,它變成了一個全卷積網路,且類似于一個U-NET網路的結構,我們一共進行了8次下采樣和8次上采樣,
2.判別這次的輸入是兩個(256,256,3)的資料了,我們把它這個兩個資料concat到一起了,這里也沒有使用全連接層了,我們也改成了全卷積,
3.2演算法邏輯
在了解演算法邏輯之前,我們先來看看這次要用到的資料集,來方便演算法邏輯的理解,
我們用到的資料集是:Facades,長什么樣子呢

就是這個樣子,每張圖片的左邊是房子的原圖,右邊是房子的簡圖,我們的目標就是:輸入簡圖,讓生成器生成和原圖相似的房子圖片,
下面我們就來盤一盤這個邏輯
1.首先給生成器輸入一個簡圖,其資料維度是N*256*256*3,經過生成器后生成一個N*256*256*3的一個資料,我們把這個生成的資料和原來的簡圖資料concat到一起,然后送入判別器,此時我們希望判別器輸出的N*16*16*1的資料是一個全1的資料,也就是說,希望生成器生成的圖能夠騙過判別器,從而來優化生成器,同時我們再讓生成的N*256*256*3的資料和它的原圖資料求一個L1loss,從而使得生成的圖和原圖又一定的相似性,這個也就是傳說中的風格遷移,
2.現在再把原圖和原始的簡圖concat到一起去,送入判別器,此時我們希望判別器的輸出N*16*16*1的資料是仍然是全一的,同時生成的圖片和原始的簡圖concat到一起去之后,希望判別器輸出的N*16*16*1的資料是全零的,以此來優化判別器,
3.至此,生成器和判別器就開始對抗起來了,印證了那句老話,我不僅要學習你,我還要超越你,
3.3實作代碼
首先是 model.py,里面定義了我們的模型結構
import torch.nn as nn
import torch
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# U-NET
##############################
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x
class GeneratorUNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(GeneratorUNet, self).__init__()
self.down1 = UNetDown(in_channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.down7 = UNetDown(512, 512, dropout=0.5)
self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 512, dropout=0.5)
self.up4 = UNetUp(1024, 512, dropout=0.5)
self.up5 = UNetUp(1024, 256)
self.up6 = UNetUp(512, 128)
self.up7 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(128, out_channels, 4, padding=1),
nn.Tanh(),
)
def forward(self, x):
# U-Net generator with skip connections from encoder to decoder
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
d8 = self.down8(d7)
u1 = self.up1(d8, d7)
u2 = self.up2(u1, d6)
u3 = self.up3(u2, d5)
u4 = self.up4(u3, d4)
u5 = self.up5(u4, d3)
u6 = self.up6(u5, d2)
u7 = self.up7(u6, d1)
return self.final(u7)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalization=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalization:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels * 2, 64, normalization=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1, bias=False)
)
def forward(self, img_A, img_B):
# Concatenate image and condition image by channels to produce input
img_input = torch.cat((img_A, img_B), 1)
return self.model(img_input)
datasets.py,這個是用來讀取facades資料集的代碼
import glob
import os
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, mode="train"):
if transforms_ is not None:
self.transform = transforms.Compose(transforms_)
else:
self.transform = None
self.files = sorted(glob.glob(os.path.join(root, mode) + "/*.*"))
if mode == "train":
self.files.extend(sorted(glob.glob(os.path.join(root, "test") + "/*.*")))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w / 2, h))
img_B = img.crop((w / 2, 0, w, h))
if np.random.random() < 0.5:
img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], "RGB")
img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], "RGB")
if self.transform is not None:
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return len(self.files)
pix2pix.py,就是我們的訓練帶代碼了,
import argparse
import os
import numpy as np
import time
import datetime
import sys
import torch
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torch.autograd import Variable
from models import *
from datasets import *
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="facades", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=1, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=256, help="size of image height") # 256
parser.add_argument("--img_width", type=int, default=256, help="size of image width") # 256
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument(
"--sample_interval", type=int, default=500, help="interval between sampling of images from generators"
)
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
opt = parser.parse_args()
print(opt)
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
cuda = True if torch.cuda.is_available() else False
# Loss functions
criterion_GAN = torch.nn.MSELoss()
criterion_pixelwise = torch.nn.L1Loss()
# Loss weight of L1 pixel-wise loss between translated image and real image
lambda_pixel = 100
# Calculate output of image discriminator (PatchGAN)
patch = (1, opt.img_height // 2 ** 4, opt.img_width // 2 ** 4)
# Initialize generator and discriminator
generator = GeneratorUNet()
discriminator = Discriminator()
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
criterion_GAN.cuda()
criterion_pixelwise.cuda()
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load("saved_models/%s/generator_%d.pth" % (opt.dataset_name, opt.epoch)))
discriminator.load_state_dict(torch.load("saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Configure dataloaders
transforms_ = [
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
import matplotlib.pyplot as plt
dataloader = DataLoader(
ImageDataset("./data/%s" % opt.dataset_name, transforms_=transforms_),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
val_dataloader = DataLoader(
ImageDataset("./data/%s" % opt.dataset_name, transforms_=transforms_, mode="val"),
batch_size=10,
shuffle=True,
num_workers=1,
)
# Tensor type
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def sample_images(batches_done):
"""Saves a generated sample from the validation set"""
imgs = next(iter(val_dataloader))
real_A = Variable(imgs["B"].type(Tensor))
real_B = Variable(imgs["A"].type(Tensor))
fake_B = generator(real_A)
img_sample = torch.cat((real_A.data, fake_B.data, real_B.data), -2)
save_image(img_sample, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=5, normalize=True)
# ----------
# Training
# ----------
if __name__ == '__main__':
prev_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Model inputs
real_A = Variable(batch["B"].type(Tensor)) # batch["B"]是語意分割圖
real_B = Variable(batch["A"].type(Tensor)) # batch["A"]是真實影像
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# GAN loss
fake_B = generator(real_A)
pred_fake = discriminator(fake_B, real_A)
loss_GAN = criterion_GAN(pred_fake, valid)
# Pixel-wise loss
loss_pixel = criterion_pixelwise(fake_B, real_B)
# Total loss
loss_G = loss_GAN + lambda_pixel * loss_pixel
loss_G.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Real loss
pred_real = discriminator(real_B, real_A)
loss_real = criterion_GAN(pred_real, valid)
# Fake loss
pred_fake = discriminator(fake_B.detach(), real_A)
loss_fake = criterion_GAN(pred_fake, fake)
# Total loss
loss_D = 0.5 * (loss_real + loss_fake)
loss_D.backward()
optimizer_D.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, adv: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_pixel.item(),
loss_GAN.item(),
time_left,
)
)
# If at sample interval save image
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "saved_models/%s/generator_%d.pth" % (opt.dataset_name, epoch))
torch.save(discriminator.state_dict(), "saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, epoch))
3.4效果展示

第一行,第四行是簡圖,第三行和第六行是原圖,第二行和第五行是生成圖,
3.5資料集和專案代碼
鏈接:https://pan.baidu.com/s/1xrdUO5s--5qYQ8MRbSMPRQ
提取碼:gudo
至此,敬禮,salute!!!!
老規矩,上咩咩圖

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/439200.html
標籤:AI