越學習,越是覺得所謂研究生不過是站在巨人的肩膀上領略科學之海的壯麗,十分榮幸能在開源精神的引領下參與到知識的傳遞網路中?(^?^*)
ps.以下塊參考的代碼均可以.ipynb形式編譯,如果您有條件,強烈安利用jupyte notebook打開
現如今,多模態學習可謂是方興未艾,不要被多模態這個概念唬住,模態可以近似理解為視覺、聽徑訓觸覺等不同的感受,深度學習中的多模態學習之于計算機就好比是五感之于人類,從Bert與ViT開始,這把火徹底燒到了CV領域,Transformer架構漸有取代CNN之勢,像現在大火的視覺transformer模型等,以本人學習經歷做參考:學習完CNN直接去看提出Transformer的論文Attention is All you Need(https://arxiv.org/pdf/1706.03762.pdf)可以說是一頭霧水,學習不可急于求成,否則就是空中樓閣,必須循序漸進,順著知識流學習,
1.以下便是 本人遵循的Transformer學習順序
### Transformer學習順序應如下:
1.MLP
[深度理解多層感知機(MLP)](https://cleverbobo.github.io/2020/08/30/bp/)
2.RNN
[一文搞懂RNN(回圈神經網路)基礎篇](https://zhuanlan.zhihu.com/p/30844905)
3.seq2seq/編碼器解碼器架構
[Encoder-Decoder 和 Seq2Seq](https://easyai.tech/ai-definition/encoder-decoder-seq2seq/)
4.注意力機制&自注意力
[Attention注意力機制的理解](https://cloud.tencent.com/developer/article/1489033)
[什么是自注意力機制](https://www.jiqizhixin.com/articles/100902)
5.transformer
[Transformer論文逐段精讀【論文精讀】](https://www.bilibili.com/video/BV1pu411o7BE)
[A Survey of Transformers](https://arxiv.org/pdf/2106.04554.pdf)
夢開始的地方!

2.OK!有了transformer這個基礎后,接下來康康現在如日中天的文本語意和視覺特征間的橋梁——Vision Transformer模型
VLP綜述VLP:
[A Survey on Vision-Language Pre-training](https://arxiv.org/abs/2202.09061)
3.Clip:基于自然語言監督信號下的遷移視覺模型
3.1有了以上基礎后,來了解下百花齊放的多模態專案吧,21年初發表的Clip是其中別樣的一朵,在openAI的4億個文本影像對與11000tpuv3天的訓練加持下,為大眾奉獻了一本超大規模的《自然語言文本語意與影像特征雙語詞典》
詞典(權重檔案)來咯~
_MODELS = { "RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt", "RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt", "RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt", "RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt", "RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt", "ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt", "ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt", "ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt", }
此話怎講,且看原理:
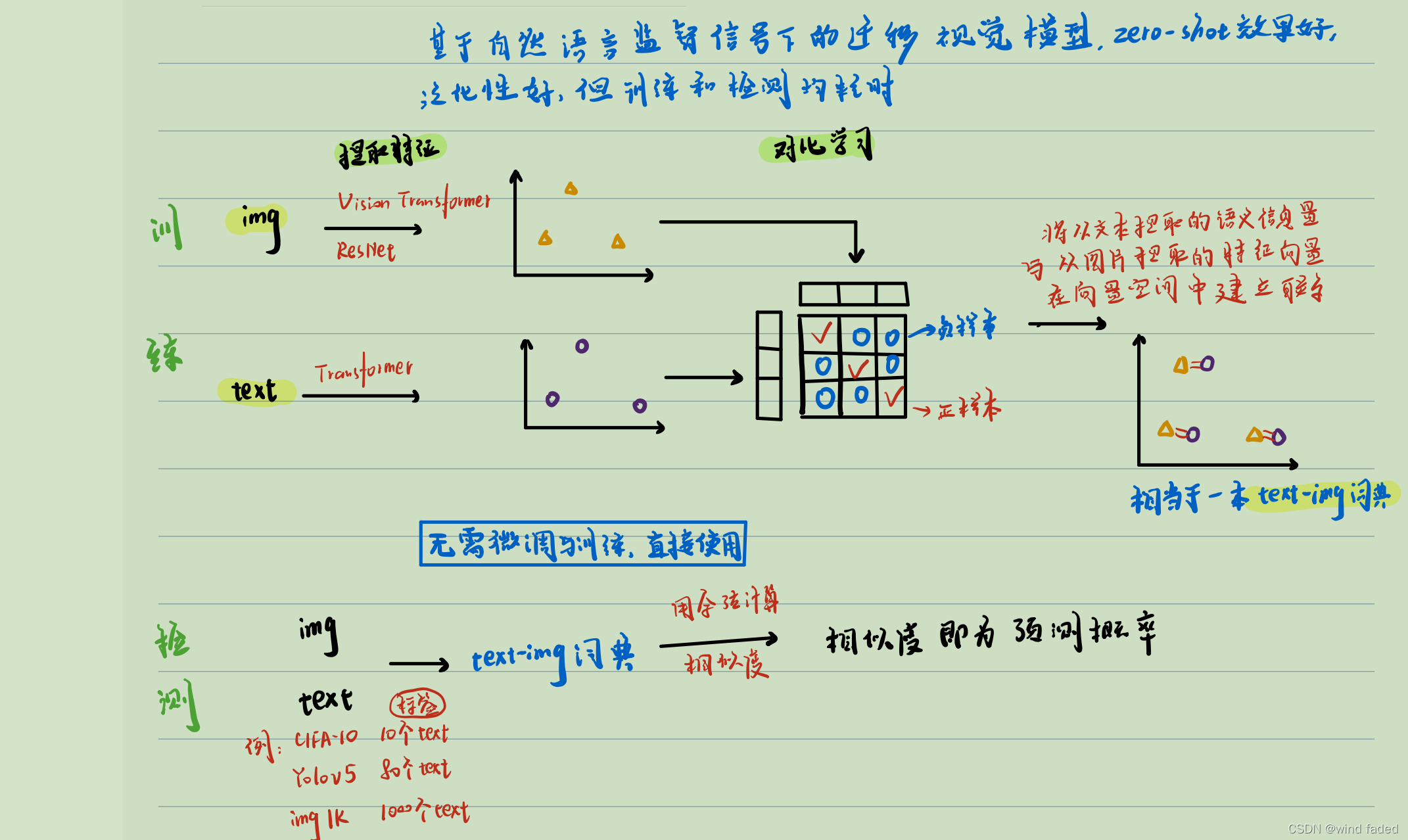
3.2 此前本人有關Clip的博客
CLIP:基于自然語言監督信號的遷移視覺模型_wind faded的博客-CSDN博客2月25月隨筆: 最近在關注自動標注領域的作業,發現了一篇有趣的文章:openai的多模態對比學習《基于自然語言監督信號的遷移視覺網路模型》,在imagenet 上zero shot 效果和有監督訓練好的ResNet 50媲美(⊙o⊙) 其實從bert 開始,自然語言處理和計算機視覺的結合就勢不可擋,之后的各種vision transform 更是如同雨后春筍,但clip 是第一次把圖片與文字的結合做到了極致, 原理簡單有效:有n個圖片文本對,使用編碼器分別提取出n個文...https://blog.csdn.net/qq_44942172/article/details/123141591?spm=1001.2014.3001.5502
3.3以下是本人對Clip模型的拓展:
### 對Clip模型的拓展
1.[本人github專案地址](https://github.com/1844520476/NTViT)
2.1[原始論文CLIP:Connecting Text and Images](https://openai.com/blog/clip/)
2.2[原始代碼openai/CLIP: Contrastive Language-Image Pretraining](https://github.com/openai/CLIP)
3.所用資料集:LAION-400M
[LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs](https://arxiv.org/abs/2111.02114)
3.4補充:對VLP與Clip的思考
?
?
還有很關鍵的一點 ,Clip模型直接把自然語言而非分類數字、檢測坐標或像素點語意作為監督信號,而是直接把自然語言作為最終的監督信號,從淺層次看:自然語言指導的學習符合人類的實際學習程序,從深層次看:首先,學習自然語言本身就是人類精心設計的語法和含義明確的特征,為什么不利用起來;其次:方便后續比對和檢索,也方便提示(prompt)處理
4.專案展示:
?
對多模態的融合又涉及對比學習與主動學習以及預訓練后的遷移學習,除此之外,包含多模態資訊的低噪資料集以及高效的訓練方法(提高樣本學習效率)都是大挑戰呀,這又衍生出兩個重要的研究方向:眾包學習與半(無)監督學習>_<
總之,多模態學習是一條有趣但充滿荊棘的路!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438647.html
標籤:AI
上一篇:【演算法崗面試】某小廠D機器學習