想入門人工智能或者資料分析,要重視可以快速上手的學習技能: 掌握一些基本概念,建立一個知識框架,然后就去實戰,在實戰中學習新知識,來填充這個框架,
我根據之前整理的一些pandas知識,總結了一個pandas的快速入門的知識框架,有了這些知識,然后去通過專案實戰,然后再補充,希望能幫助大家快速上手,喜歡本文記得收藏、點贊、關注,我將這些資料整理成PDF版本,需要的可以問題找我獲取,

推薦文章
-
李宏毅《機器學習》國語課程(2022)來了
-
有人把吳恩達老師的機器學習和深度學習做成了中文版
-
上癮了,最近又給公司擼了一個可視化大屏(附原始碼)
-
如此優雅,4款 Python 自動資料分析神器真香啊
-
梳理半月有余,精心準備了17張知識思維導圖,這次要講清統計學
-
年侄訓總:20份可視化大屏模板,直接套用真香(文末附原始碼)
Pandas入門知識框架
1. 什么是Pandas?熊貓?
Pandas 可以說是基于 NumPy 構建的含有更高級資料結構和分析能力的工具包, 實作了類似Excel表的功能,可以對二維資料表進行很方便的操作,
在資料分析作業中,Pandas 的使用頻率是很高的,一方面是因為 Pandas 提供的基礎資料結構 DataFrame 與 json 的契合度很高,轉換起來就很方便,另一方面,如果我們日常的資料清理作業不是很復雜的話,你通常用幾句 Pandas 代碼就可以對資料進行規整,
Pandas的核心資料結構:Series 和 DataFrame 這兩個核心資料結構,他們分別代表著一維的序列和二維的表結構,基于這兩種資料結構,Pandas 可以對資料進行匯入、清洗、處理、統計和輸出,
快速掌握Pandas,就要快速學會這兩種核心資料結構,
2. 兩種核心資料結構
2.1 Series
Series 是個定長的字典序列,說是定長是因為在存盤的時候,相當于兩個 ndarray,這也是和字典結構最大的不同,因為在字典的結構里,元素的個數是不固定的,
Series 有兩個基本屬性:index 和 values,在 Series 結構中,index 默認是 0,1,2,……遞增的整數序列,當然我們也可以自己來指定索引,比如 index=[‘a’, ‘b’, ‘c’, ‘d’],
import pandas as pd
from pandas import Series, DataFrame
x1 = Series([1,2,3,4])
x2 = Series(data=[1,2,3,4], index=['a', 'b', 'c', 'd'])
print x1
print x2
上面這個例子中,x1 中的 index 采用的是默認值,x2 中 index 進行了指定,我們也可以采用字典的方式來創建 Series,比如:
d = {'a':1, 'b':2, 'c':3, 'd':4}
x3 = Series(d)
print x3
Series的增刪改查
-
創建一個Series
In [85]: ps = pd.Series(data=[-3,2,1],index=['a','f','b'],dtype=np.float32) In [86]: ps Out[86]: a -3.0 f 2.0 b 1.0 dtype: float32 -
增加元素append
In [112]: ps.append(pd.Series(data=[-8.0],index=['f'])) Out[112]: a 4.0 f 2.0 b 1.0 f -8.0 dtype: float64 -
洗掉元素drop
In [119]: ps Out[119]: a 4.0 f 2.0 b 1.0 dtype: float32 In [120]: psd = ps.drop('f') In [121]: psd Out[121]: a 4.0 b 1.0 dtype: float32注意不管是 append 操作,還是 drop 操作,都是發生在原資料的副本上,不是原資料上,
-
修改元素
通過標簽修改對應資料,如下所示:In [123]: psn Out[123]: a 4.0 f 2.0 b 1.0 f -8.0 dtype: float64 In [124]: psn['f'] = 10.0 In [125]: psn Out[125]: a 4.0 f 10.0 b 1.0 f 10.0 dtype: float64Series里面允許標簽相同, 且如果相同, 標簽都會被修改,
-
訪問元素
一種通過默認的整數索引,在 Series 物件未被顯示的指定 label 時,都是通過索引訪問;另一種方式是通過標簽訪問,In [126]: ps Out[126]: a 4.0 f 2.0 b 1.0 dtype: float32 In [128]: ps[2] # 索引訪問 Out[128]: 1.0 In [127]: ps['b'] # 標簽訪問 Out[127]: 1.0
2.2 DataFrame
DataFrame 型別資料結構類似資料庫表,它包括了行索引和列索引,我們可以將 DataFrame 看成是由相同索引的 Series 組成的字典型別,
import pandas as pd
from pandas import Series, DataFrame
data = {'Chinese': [66, 95, 93, 90,80],'English': [65, 85, 92, 88, 90],'Math': [30, 98, 96, 77, 90]}
df1= DataFrame(data)
df2 = DataFrame(data, index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'], columns=['English', 'Math', 'Chinese'])
print df1
print df2
在后面的案例中,我一般會用 df, df1, df2 這些作為 DataFrame 資料型別的變數名,我們以例子中的 df2 為例,列索引是[‘English’, ‘Math’, ‘Chinese’],行索引是[‘ZhangFei’, ‘GuanYu’, ‘ZhaoYun’, ‘HuangZhong’, ‘DianWei’],所以 df2 的輸出是:
English Math Chinese
ZhangFei 65 30 66
GuanYu 85 98 95
ZhaoYun 92 96 93
HuangZhong 88 77 90
DianWei 90 90 80
2.2.1基本操作
(1)資料的匯入與輸出
Pandas 允許直接從 xlsx,csv 等檔案中匯入資料,也可以輸出到 xlsx, csv 等檔案,非常方便,
需要說明的是,在運行的程序可能會存在缺少 xlrd 和 openpyxl 包的情況,到時候如果缺少了,可以在命令列模式下使用“pip install”命令來進行安裝,
import pandas as pd
from pandas import Series, DataFrame
score = DataFrame(pd.read_excel('data.xlsx'))
score.to_excel('data1.xlsx')
print score
關于資料匯入, pandas提供了強勁的讀取支持, 比如讀寫CSV檔案, read_csv()函式有38個引數之多, 這里面有一些很有用, 主要可以分為下面幾個維度來梳理:
-
基本引數
-
filepathorbuffer: 資料的輸入路徑, 可以是檔案路徑, 也可是是URL或者實作read方法的任意物件 -
sep: 資料檔案的分隔符, 默認為逗號 -
delim_whitespace: 表示分隔符為空白字符, 可以是一個空格, 兩個空格 -
header: 設定匯入DataFrame的列名稱, 如果names沒賦值, header會選取資料檔案的第一行作為列名 -
index_col: 表示哪個或者哪些列作為index -
usecols: 選取資料檔案的哪些列到DataFrame中 -
prefix: 當匯入的資料沒有header時, 設定此引數會自動加一個前綴 -
通用決議引數
-
dtype:讀取資料時修改列的型別 -
converters: 實作對列資料的變化操作 -
skip_rows: 過濾行 -
nrows: 設定一次性讀入的檔案行數,它在讀入大檔案時很有用,比如 16G 記憶體的PC無法容納幾百 G 的大檔案, -
skip_blank_lines: 過濾掉空行 -
時間處理相關引數
-
parse_dates: 如果匯入的某些列為時間型別,但是匯入時沒有為此引數賦值,匯入后就不是時間型別
-
date_parser: 定制某種時間型別
-
分開讀入相關引數:
分塊讀入記憶體,尤其單機處理大檔案時會很有用, -
iterator: iterator 取值 boolean,default False,回傳一個 TextFileReader 物件,以便逐塊處理檔案,
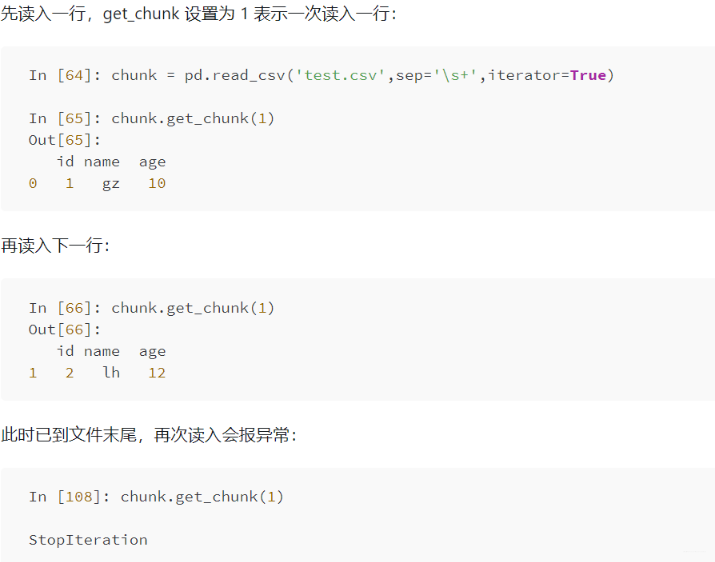
-
chunksize: 整型,默認為 None,設定檔案塊的大小,
-
格式和壓縮相關引數
id name age 0 1 gz 10 1 2 lh 12
- `thousands`: str,default None,千分位分割符,如 `,` 或者 `.`, - `encoding`: 指定字符集型別,通常指定為 ‘utf-8’ -
compression
compression 引數取值為 {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None},默認 ‘infer’,直接使用磁盤上的壓縮檔案,如果使用 infer 引數,則使用 gzip、bz2、zip 或者解壓檔案名中以 ‘.gz’、‘.bz2’、‘.zip’ 或 ‘xz’ 這些為后綴的檔案,否則不解壓,如果使用 zip,那么 ZIP 包中必須只包含一個檔案,設定為 None 則不解壓,手動壓縮本文一直使用的 test.csv 為 test.zip 檔案,然后打開In [73]: df = pd.read_csv('test.zip',sep='\s+',compression='zip') In [74]: df Out[74]:
具體這些引數怎么用, 可以看https://gitbook.cn/gitchat/column/5e37978dec8d9033cf916b5d/topic/5e3bcef3ec8d9033cf92466f
(2)資料清洗
資料清洗是資料準備程序中必不可少的環節,Pandas 也為我們提供了資料清洗的工具,在后面資料清洗的章節中會給你做詳細的介紹,這里簡單介紹下 Pandas 在資料清洗中的使用方法,
(2.1)洗掉 DataFrame 中的不必要的列或行
Pandas 提供了一個便捷的方法 drop() 函式來洗掉我們不想要的列或行
df2 = df2.drop(columns=['Chinese'])
想把“張飛”這行刪掉,
df2 = df2.drop(index=['ZhangFei'])
(2.2)重命名列名 columns,讓串列名更容易識別
如果你想對 DataFrame 中的 columns 進行重命名,可以直接使用 rename(columns=new_names, inplace=True) 函式,比如我把列名 Chinese 改成 YuWen,English 改成 YingYu,
df2.rename(columns={'Chinese': 'YuWen', 'English': 'Yingyu'}, inplace = True)
(2.3)去重復的值
資料采集可能存在重復的行,這時只要使用 drop_duplicates() 就會自動把重復的行去掉
df = df.drop_duplicates() #去除重復行
(2.4)格式問題
- 更改資料格式
這是個比較常用的操作,因為很多時候資料格式不規范,我們可以使用 astype 函式來規范資料格式,比如我們把 Chinese 欄位的值改成 str 型別,或者 int64 可以這么寫
df2['Chinese'].astype('str')
df2['Chinese'].astype(np.int64)
- 資料間的空格
有時候我們先把格式轉成了 str 型別,是為了方便對資料進行操作,這時想要洗掉資料間的空格,我們就可以使用 strip 函式:
#洗掉左右兩邊空格
df2['Chinese']=df2['Chinese'].map(str.strip)
#洗掉左邊空格
df2['Chinese']=df2['Chinese'].map(str.lstrip)
#洗掉右邊空格
df2['Chinese']=df2['Chinese'].map(str.rstrip)
如果資料里有某個特殊的符號,我們想要洗掉怎么辦?同樣可以使用 strip 函式,比如 Chinese 欄位里有美元符號,我們想把這個刪掉,可以這么寫:
df2['Chinese']=df2['Chinese'].str.strip('$')
(2.5)大小寫轉換
大小寫是個比較常見的操作,比如人名、城市名等的統一都可能用到大小寫的轉換,在 Python 里直接使用 upper(), lower(), title() 函式,方法如下:
#全部大寫
df2.columns = df2.columns.str.upper()
#全部小寫
df2.columns = df2.columns.str.lower()
#首字母大寫
df2.columns = df2.columns.str.title()
(2.6)查找空值
資料量大的情況下,有些欄位存在空值 NaN 的可能,這時就需要使用 Pandas 中的 isnull 函式進行查找,比如,我們輸入一個資料表如下:
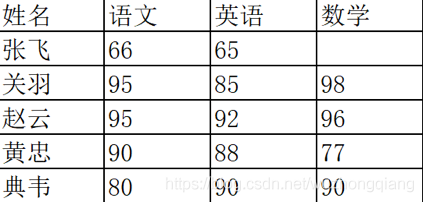
如果我們想看下哪個地方存在空值 NaN,可以針對資料表 df 進行 df.isnull(),結果如下:
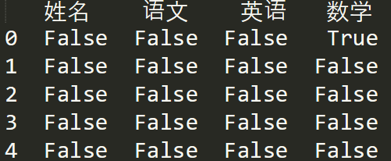
如果我想知道哪列存在空值,可以使用 df.isnull().any(),結果如下:
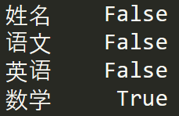
2.2.2 使用apply函式對資料進行清洗
apply 函式是 Pandas 中自由度非常高的函式,使用頻率也非常高,比如我們想對 name 列的數值都進行大寫轉化可以用:
df['name'] = df['name'].apply(str.upper)
我們也可以定義個函式,在 apply 中進行使用,比如定義 double_df 函式是將原來的數值 *2 進行回傳,然后對 df1 中的“語文”列的數值進行 *2 處理,可以寫成:
def double_df(x):
return 2*x
df1[u'語文'] = df1[u'語文'].apply(double_df)
我們也可以定義更復雜的函式,比如對于 DataFrame,我們新增兩列,其中’new1’列是“語文”和“英語”成績之和的 m 倍,'new2’列是“語文”和“英語”成績之和的 n 倍,我們可以這樣寫:
def plus(df,n,m):
df['new1'] = (df[u'語文']+df[u'英語']) * m
df['new2'] = (df[u'語文']+df[u'英語']) * n
return df
df1 = df1.apply(plus,axis=1,args=(2,3,))
2.3 資料統計
在資料清洗后,我們就要對資料進行統計了,Pandas 和 NumPy 一樣,都有常用的統計函式,如果遇到空值 NaN,會自動排除,常用的統計函式包括:

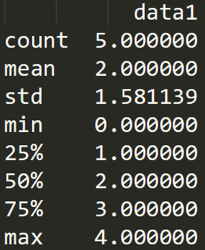
表格中有一個 describe() 函式,統計函式千千萬,describe() 函式最簡便,它是個統計大禮包,可以快速讓我們對資料有個全面的了解,下面我直接使用 df1.descirbe() 輸出結果為:
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
print df1.describe()
2.4 資料表合并
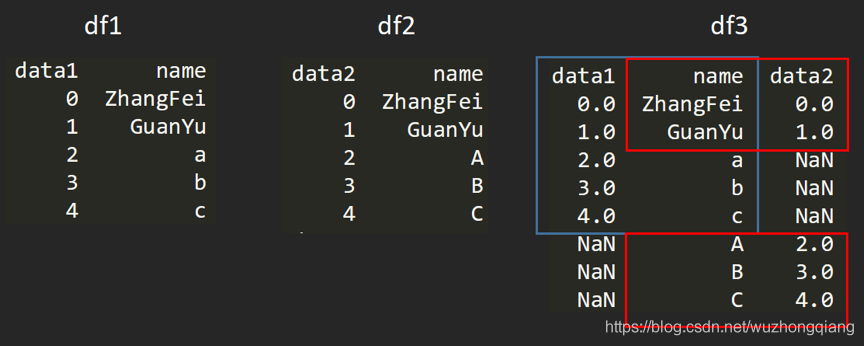
有時候我們需要將多個渠道源的多個資料表進行合并,一個 DataFrame 相當于一個資料庫的資料表,那么多個 DataFrame 資料表的合并就相當于多個資料庫的表合并,
比如我要創建兩個 DataFrame:
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
df2 = DataFrame({'name':['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2':range(5)})
兩個 DataFrame 資料表的合并使用的是 merge() 函式,有下面 5 種形式:
- python 基于指定列進行連接
比如我們可以基于 name 這列進行連接,
df3 = pd.merge(df1, df2, on='name')

2. inner內連接
inner 內鏈接是 merge 合并的默認情況,inner 內連接其實也就是鍵的交集,在這里 df1, df2 相同的鍵是 name,所以是基于 name 欄位做的連接:
df3 = pd.merge(df1, df2, how='inner')

3. left左連接
左連接是以第一個 DataFrame 為主進行的連接,第二個 DataFrame 作為補充,
df3 = pd.merge(df1, df2, how='left')
-
right右連接
右連接是以第二個 DataFrame 為主進行的連接,第一個 DataFrame 作為補充,
df3 = pd.merge(df1, df2, how='right')

5. outer外連接
外連接相當于求兩個 DataFrame 的并集,
df3 = pd.merge(df1, df2, how='outer')
2.5 DataFram的行級遍歷
盡管 Pandas 已經盡可能向量化,讓使用者盡可能避免 for 回圈,但是有時不得已,還得要遍歷 DataFrame,Pandas 提供 iterrows、itertuples 兩種行級遍歷,
-
使用
iterrows遍歷列印所有行,在 IPython 里輸入以下行:def iterrows_time(df): for i,row in df.iterrows(): print(row)訪問每一行某個元素的時候, 可以通過列名直接訪問:

-
使用
itertuples遍歷列印每行:def itertuples_time(df): for nt in df.itertuples(): print(nt)這個效率更高, 比上面那個節省6倍多的時間, 所在資料量非常大的時候, 推薦后者,訪問每一行某個元素的時候, 需要
getattr函式

-
使用
iteritems遍歷每一行這個訪問每一行元素的時候, 用的是每一列的數字索引

3. 如何用SQL方式打開Pandas
Pandas 的 DataFrame 資料型別可以讓我們像處理資料表一樣進行操作,比如資料表的增刪改查,都可以用 Pandas 工具來完成,不過也會有很多人記不住這些 Pandas 的命令,相比之下還是用 SQL 陳述句更熟練,用 SQL 對資料表進行操作是最方便的,它的陳述句描述形式更接近我們的自然語言,
事實上,在 Python 里可以直接使用 SQL 陳述句來操作 Pandas,
這里給你介紹個工具:pandasql,
pandasql 中的主要函式是 sqldf,它接收兩個引數:一個 SQL 查詢陳述句,還有一組環境變數 globals() 或 locals(),這樣我們就可以在 Python 里,直接用 SQL 陳述句中對 DataFrame 進行操作,舉個例子:
import pandas as pd
from pandas import DataFrame
from pandasql import sqldf, load_meat, load_births
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
pysqldf = lambda sql: sqldf(sql, globals())
sql = "select * from df1 where name ='ZhangFei'"
print pysqldf(sql)
運行結果
data1 name
0 0 ZhangFei
上面代碼中,定義了:
pysqldf = lambda sql: sqldf(sql, globals())
在這個例子里,輸入的引數是 sql,回傳的結果是 sqldf 對 sql 的運行結果,當然 sqldf 中也輸入了 globals 全域引數,因為在 sql 中有對全域引數 df1 的使用,
技術交流
歡迎轉載、收藏、有所識訓點贊支持一下!

目前開通了技術交流群,群友已超過2000人,添加時最好的備注方式為:來源+興趣方向,方便找到志同道合的朋友
- 方式①、發送如下圖片至微信,長按識別,后臺回復:加群;
- 方式②、添加微信號:dkl88191,備注:來自CSDN
- 方式③、微信搜索公眾號:Python學習與資料挖掘,后臺回復:加群

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438645.html
標籤:AI
下一篇:【演算法崗面試】某小廠D機器學習