ShardingSphere5入門到實戰
第01章 高性能架構模式
互聯網業務興起之后,海量用戶加上海量資料的特點,單個資料庫服務器已經難以滿足業務需要,必須考慮資料庫集群的方式來提升性能,高性能資料庫集群的第一種方式是“讀寫分離”,第二種方式是“資料庫分片”,
1、讀寫分離架構
讀寫分離原理:讀寫分離的基本原理是將資料庫讀寫操作分散到不同的節點上,下面是其基本架構圖:

讀寫分離的基本實作:
主庫負責處理事務性的增刪改操作,從庫負責處理查詢操作,能夠有效的避免由資料更新導致的行鎖,使得整個系統的查詢性能得到極大的改善,- 讀寫分離是
根據 SQL 語意的分析,將讀操作和寫操作分別路由至主庫與從庫, - 通過
一主多從的配置方式,可以將查詢請求均勻的分散到多個資料副本,能夠進一步的提升系統的處理能力, - 使用
多主多從的方式,不但能夠提升系統的吞吐量,還能夠提升系統的可用性,可以達到在任何一個資料庫宕機,甚至磁盤物理損壞的情況下仍然不影響系統的正常運行,
下圖展示了根據業務需要,將用戶表的寫操作和讀操路由到不同的資料庫的方案:

CAP 理論:
CAP 定理(CAP theorem)又被稱作布魯爾定理(Brewer's theorem),是加州大學伯克利分校的計算機科學家埃里克·布魯爾(Eric Brewer)在 2000 年的 ACM PODC 上提出的一個猜想,對于設計分布式系統的架構師來說,CAP 是必須掌握的理論,
在一個分布式系統中,當涉及讀寫操作時,只能保證一致性(Consistence)、可用性(Availability)、磁區容錯性(Partition Tolerance)三者中的兩個,另外一個必須被犧牲,
- C 一致性(Consistency):對某個指定的客戶端來說,讀操作保證能夠回傳最新的寫操作結果
- A 可用性(Availability):非故障的節點在合理的時間內回傳合理的回應
(不是錯誤和超時的回應) - P 磁區容忍性(Partition Tolerance):當出現網路磁區后
(可能是丟包,也可能是連接中斷,還可能是擁塞),系統能夠繼續“履行職責”
CAP特點:
-
在實際設計程序中,每個系統不可能只處理一種資料,而是包含多種型別的資料,
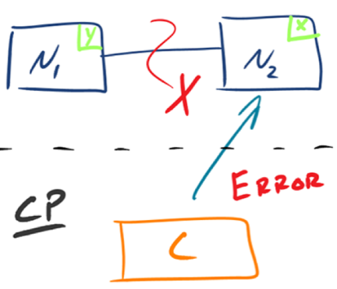
有的資料必須選擇 CP,有的資料必須選擇 AP,分布式系統理論上不可能選擇 CA 架構,- CP:如下圖所示,
為了保證一致性,當發生磁區現象后,N1 節點上的資料已經更新到 y,但由于 N1 和 N2 之間的復制通道中斷,資料 y 無法同步到 N2,N2 節點上的資料還是 x,這時客戶端 C 訪問 N2 時,N2 需要回傳 Error,提示客戶端 C“系統現在發生了錯誤”,這種處理方式違背了可用性(Availability)的要求,因此 CAP 三者只能滿足 CP,
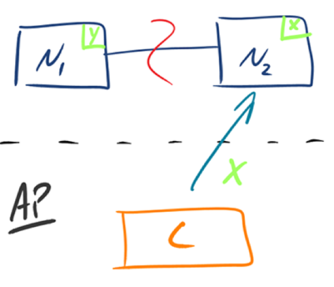
- AP:如下圖所示,
為了保證可用性,當發生磁區現象后,N1 節點上的資料已經更新到 y,但由于 N1 和 N2 之間的復制通道中斷,資料 y 無法同步到 N2,N2 節點上的資料還是 x,這時客戶端 C 訪問 N2 時,N2 將當前自己擁有的資料 x 回傳給客戶端 C 了,而實際上當前最新的資料已經是 y 了,這就不滿足一致性(Consistency)的要求了,因此 CAP 三者只能滿足 AP,注意:這里 N2 節點回傳 x,雖然不是一個“正確”的結果,但是一個“合理”的結果,因為 x 是舊的資料,并不是一個錯亂的值,只是不是最新的資料而已,
- CP:如下圖所示,
-
CAP 理論中的
C 在實踐中是不可能完美實作的,在資料復制的程序中,節點N1 和節點 N2 的資料并不一致(強一致性),即使無法做到強一致性,但應用可以采用適合的方式達到最終一致性,具有如下特點:- 基本可用(Basically Available):分布式系統在出現故障時,允許損失部分可用性,即保證核心可用,
- 軟狀態(Soft State):允許系統存在中間狀態,而該中間狀態不會影響系統整體可用性,這里的中間狀態就是 CAP 理論中的資料不一致,
最終一致性(Eventual Consistency):系統中的所有資料副本經過一定時間后,最終能夠達到一致的狀態,
2、資料庫分片架構
讀寫分離的問題:
讀寫分離分散了資料庫讀寫操作的壓力,但沒有分散存盤壓力,為了滿足業務資料存盤的需求,就需要將存盤分散到多臺資料庫服務器上,
資料分片:
將存放在單一資料庫中的資料分散地存放至多個資料庫或表中,以達到提升性能瓶頸以及可用性的效果, 資料分片的有效手段是對關系型資料庫進行分庫和分表,資料分片的拆分方式又分為垂直分片和水平分片,
2.1、垂直分片
垂直分庫:
按照業務拆分的方式稱為垂直分片,又稱為縱向拆分,它的核心理念是專庫專用, 在拆分之前,一個資料庫由多個資料表構成,每個表對應著不同的業務,而拆分之后,則是按照業務將表進行歸類,分布到不同的資料庫中,從而將壓力分散至不同的資料庫,

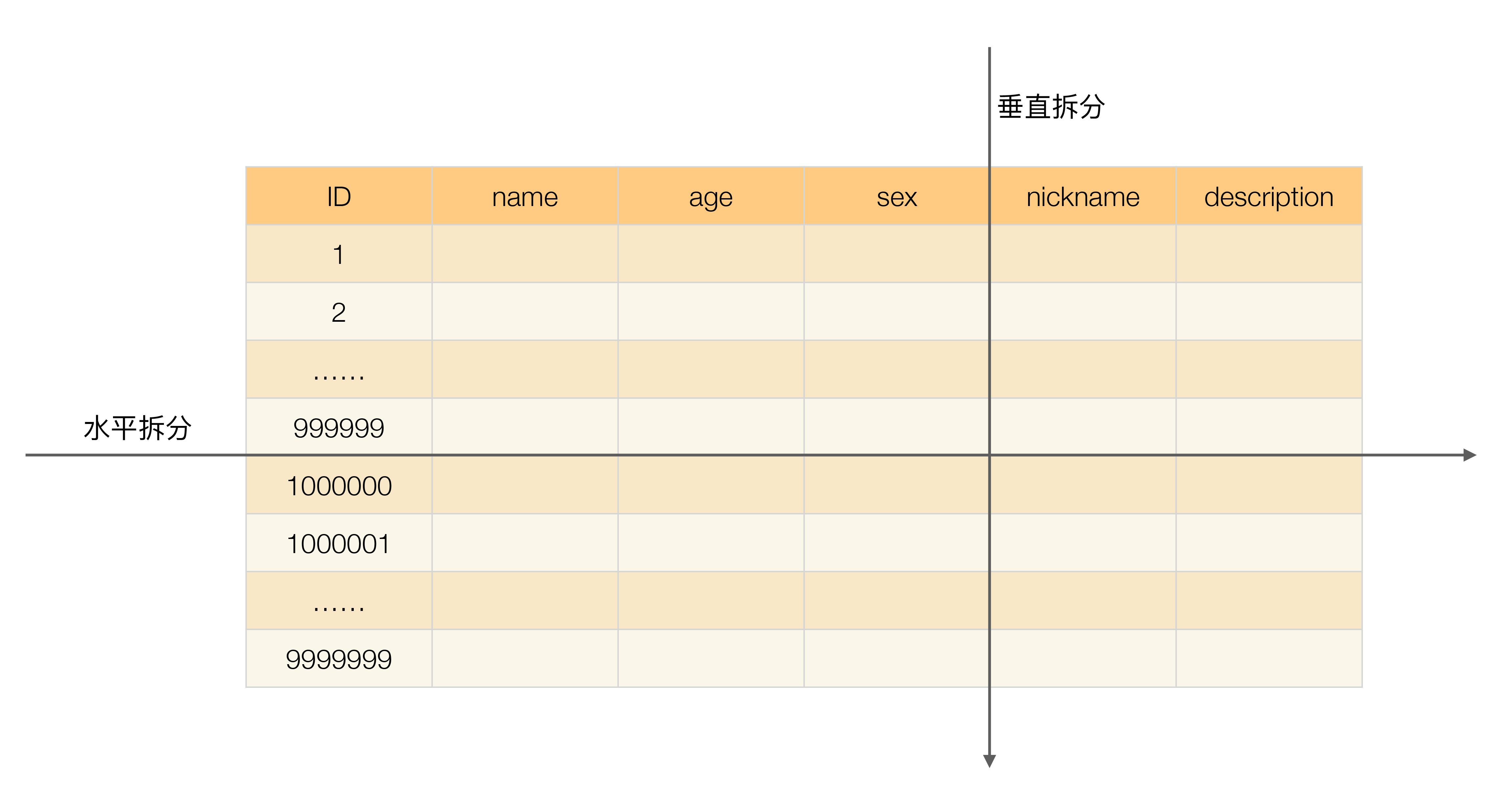
下圖展示了根據業務需要,將用戶表和訂單表垂直分片到不同的資料庫的方案:

垂直拆分可以緩解資料量和訪問量帶來的問題,但無法根治,如果垂直拆分之后,表中的資料量依然超過單節點所能承載的閾值,則需要水平分片來進一步處理,
垂直分表:
垂直分表適合將表中某些不常用的列,或者是占了大量空間的列拆分出去,
假設我們是一個婚戀網站,用戶在篩選其他用戶的時候,主要是用 age 和 sex 兩個欄位進行查詢,而 nickname 和 description 兩個欄位主要用于展示,一般不會在業務查詢中用到,description 本身又比較長,因此我們可以將這兩個欄位獨立到另外一張表中,這樣在查詢 age 和 sex 時,就能帶來一定的性能提升,
垂直分表引入的復雜性主要體現在表操作的數量要增加,例如,原來只要一次查詢就可以獲取 name、age、sex、nickname、description,現在需要兩次查詢,一次查詢獲取 name、age、sex,另外一次查詢獲取 nickname、description,
水平分表適合表行數特別大的表,水平分表屬于水平分片,
2.2、水平分片
水平分片又稱為橫向拆分, 相對于垂直分片,它不再將資料根據業務邏輯分類,而是通過某個欄位(或某幾個欄位),根據某種規則將資料分散至多個庫或表中,每個分片僅包含資料的一部分, 例如:根據主鍵分片,偶數主鍵的記錄放入 0 庫(或表),奇數主鍵的記錄放入 1 庫(或表),如下圖所示,
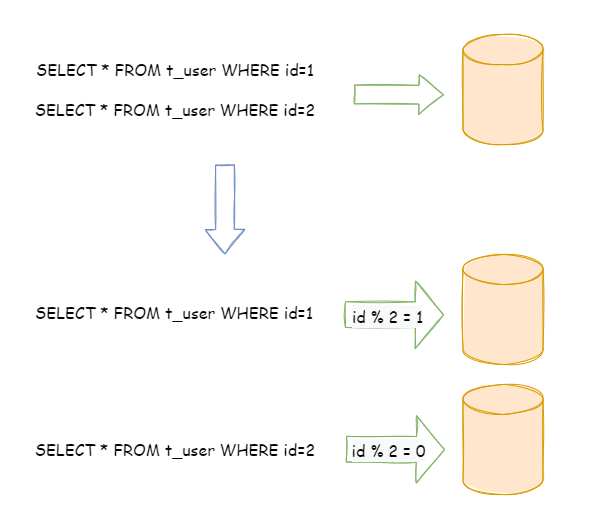
單表進行切分后,是否將多個表分散在不同的資料庫服務器中,可以根據實際的切分效果來確定,
-
水平分表:單表切分為多表后,新的表即使在同一個資料庫服務器中,也可能帶來可觀的性能提升,如果性能能夠滿足業務要求,可以不拆分到多臺資料庫服務器,畢竟業務分庫也會引入很多復雜性;
-
水平分庫:如果單表拆分為多表后,單臺服務器依然無法滿足性能要求,那就需要將多個表分散在不同的資料庫服務器中,
阿里巴巴Java開發手冊:
【推薦】單表行數超過 500 萬行或者單表容量超過 2GB,才推薦進行分庫分表,
說明:如果預計三年后的資料量根本達不到這個級別,
請不要在創建表時就分庫分表,
3、讀寫分離和資料分片架構
下圖展現了將資料分片與讀寫分離一同使用時,應用程式與資料庫集群之間的復雜拓撲關系,

4、實作方式
讀寫分離和資料分片具體的實作方式一般有兩種: 程式代碼封裝和中間件封裝,
4.1、程式代碼封裝
程式代碼封裝指在代碼中抽象一個資料訪問層(或中間層封裝),實作讀寫操作分離和資料庫服務器連接的管理,
其基本架構是:以讀寫分離為例
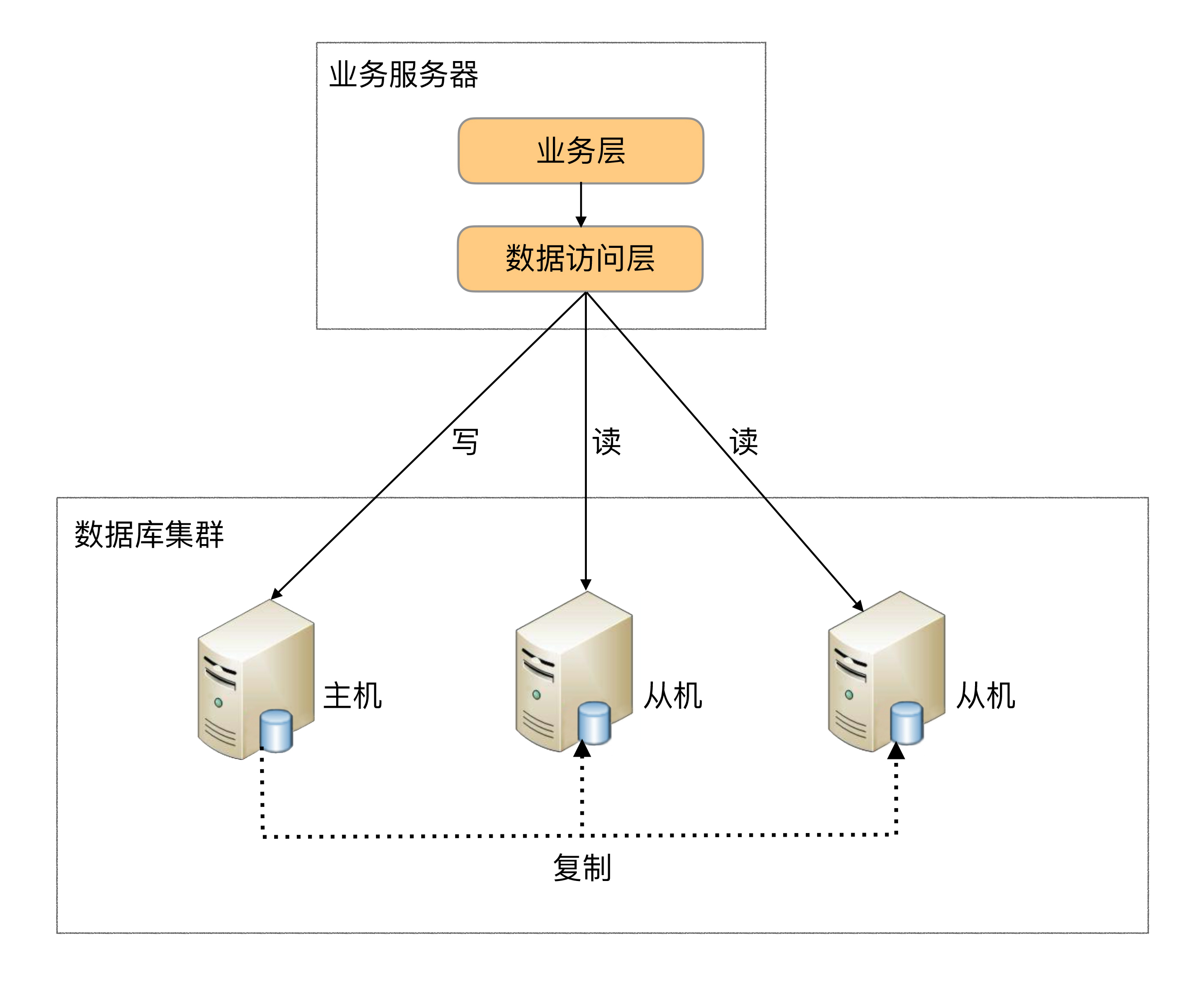
4.2、中間件封裝
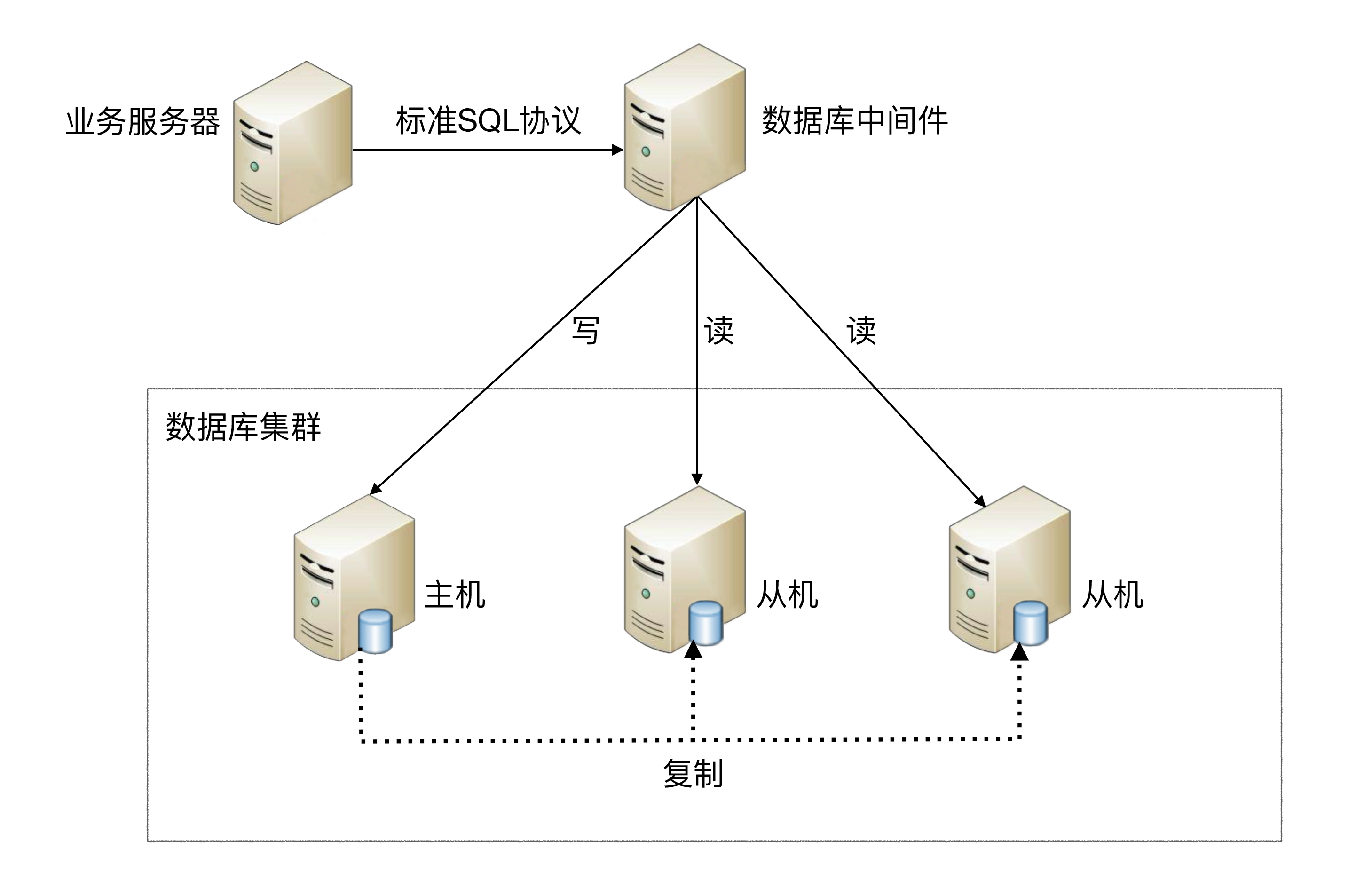
中間件封裝指的是獨立一套系統出來,實作讀寫操作分離和資料庫服務器連接的管理,對于業務服務器來說,訪問中間件和訪問資料庫沒有區別,在業務服務器看來,中間件就是一個資料庫服務器,
基本架構是:以讀寫分離為例
4.3、常用解決方案
Apache ShardingSphere(程式級別和中間件級別)
MyCat(資料庫中間件)
第02章 ShardingSphere
1、簡介
官網:https://shardingsphere.apache.org/index_zh.html
檔案:https://shardingsphere.apache.org/document/5.1.1/cn/overview/
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(規劃中)這 3 款既能夠獨立部署,又支持混合部署配合使用的產品組成,
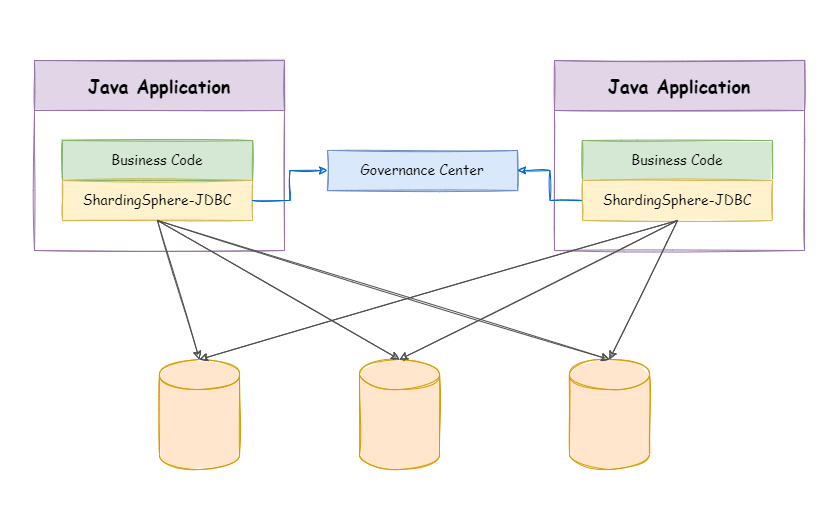
2、ShardingSphere-JDBC
程式代碼封裝
定位為輕量級 Java 框架,在 Java 的 JDBC 層提供的額外服務, 它使用客戶端直連資料庫,以 jar 包形式提供服務,無需額外部署和依賴,可理解為增強版的 JDBC 驅動,完全兼容 JDBC 和各種 ORM 框架,
3、ShardingSphere-Proxy
中間件封裝
定位為透明化的資料庫代理端,提供封裝了資料庫二進制協議的服務端版本,用于完成對異構語言的支持, 目前提供 MySQL 和 PostgreSQL版本,它可以使用任何兼容 MySQL/PostgreSQL 協議的訪問客戶端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作資料,對 DBA 更加友好,

第03章 MySQL主從同步
1、MySQL主從同步原理
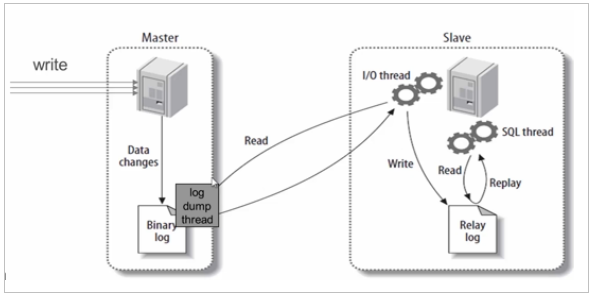
基本原理:
slave會從master讀取binlog來進行資料同步
具體步驟:
step1:master將資料改變記錄到二進制日志(binary log)中,step2:當slave上執行start slave命令之后,slave會創建一個IO 執行緒用來連接master,請求master中的binlog,step3:當slave連接master時,master會創建一個log dump 執行緒,用于發送 binlog 的內容,在讀取 binlog 的內容的操作中,會對主節點上的 binlog 加鎖,當讀取完成并發送給從服務器后解鎖,step4:IO 執行緒接收主節點 binlog dump 行程發來的更新之后,保存到中繼日志(relay log)中,step5:slave的SQL執行緒,讀取relay log日志,并決議成具體操作,從而實作主從操作一致,最終資料一致,
2、一主多從配置
服務器規劃:使用docker方式創建,主從服務器IP一致,埠號不一致
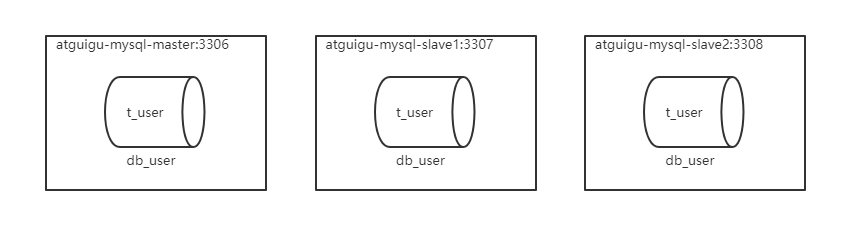
- 主服務器:容器名
atguigu-mysql-master,埠3306 - 從服務器:容器名
atguigu-mysql-slave1,埠3307 - 從服務器:容器名
atguigu-mysql-slave2,埠3308
注意:如果此時防火墻是開啟的,則先關閉防火墻,并重啟docker,否則后續安裝的MySQL無法啟動
#關閉docker
systemctl stop docker
#關閉防火墻
systemctl stop firewalld
#啟動docker
systemctl start docker
2.1、準備主服務器
- step1:在docker中創建并啟動MySQL主服務器:
埠3306
docker run -d \
-p 3306:3306 \
-v /atguigu/mysql/master/conf:/etc/mysql/conf.d \
-v /atguigu/mysql/master/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name atguigu-mysql-master \
mysql:8.0.29
- step2:創建MySQL主服務器組態檔:
默認情況下MySQL的binlog日志是自動開啟的,可以通過如下配置定義一些可選配置
vim /atguigu/mysql/master/conf/my.cnf
配置如下內容
[mysqld]
# 服務器唯一id,默認值1
server-id=1
# 設定日志格式,默認值ROW
binlog_format=STATEMENT
# 二進制日志名,默認binlog
# log-bin=binlog
# 設定需要復制的資料庫,默認復制全部資料庫
#binlog-do-db=mytestdb1
#binlog-do-db=mytestdb2
# 設定不需要復制的資料庫
#binlog-ignore-db=mysql
#binlog-ignore-db=infomation_schema
重啟MySQL容器
docker restart atguigu-mysql-master
binlog格式說明:
- binlog_format=STATEMENT:日志記錄的是主機資料庫的
寫指令,性能高,但是now()之類的函式以及獲取系統引數的操作會出現主從資料不同步的問題, - binlog_format=ROW(默認):日志記錄的是主機資料庫的
寫后的資料,批量操作時性能較差,解決now()或者 user()或者 @@hostname 等操作在主從機器上不一致的問題, - binlog_format=MIXED:是以上兩種level的混合使用,有函式用ROW,沒函式用STATEMENT,但是無法識別系統變數
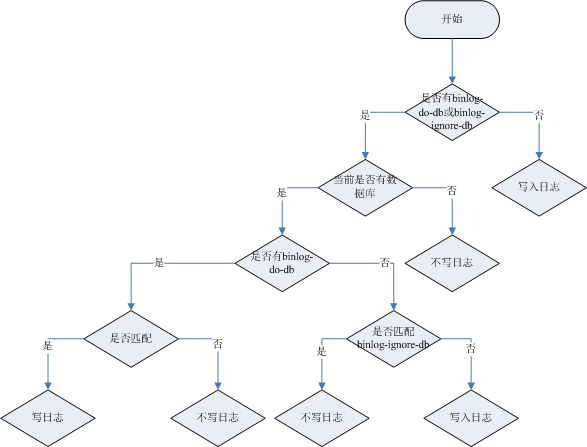
binlog-ignore-db和binlog-do-db的優先級問題:
- step3:使用命令列登錄MySQL主服務器:
#進入容器:env LANG=C.UTF-8 避免容器中顯示中文亂碼
docker exec -it atguigu-mysql-master env LANG=C.UTF-8 /bin/bash
#進入容器內的mysql命令列
mysql -uroot -p
#修改默認密碼校驗方式
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
- step4:主機中創建slave用戶:
-- 創建slave用戶
CREATE USER 'atguigu_slave'@'%';
-- 設定密碼
ALTER USER 'atguigu_slave'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 授予復制權限
GRANT REPLICATION SLAVE ON *.* TO 'atguigu_slave'@'%';
-- 重繪權限
FLUSH PRIVILEGES;
- step5:主機中查詢master狀態:
執行完此步驟后不要再操作主服務器MYSQL,防止主服務器狀態值變化
SHOW MASTER STATUS;
記下File和Position的值,執行完此步驟后不要再操作主服務器MYSQL,防止主服務器狀態值變化,

2.2、準備從服務器
可以配置多臺從機slave1、slave2...,這里以配置slave1為例,請參考slave1獨立完成slave2的配置
- step1:在docker中創建并啟動MySQL從服務器:
埠3307
docker run -d \
-p 3307:3306 \
-v /atguigu/mysql/slave1/conf:/etc/mysql/conf.d \
-v /atguigu/mysql/slave1/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name atguigu-mysql-slave1 \
mysql:8.0.29
- step2:創建MySQL從服務器組態檔:
vim /atguigu/mysql/slave1/conf/my.cnf
配置如下內容:
[mysqld]
# 服務器唯一id,每臺服務器的id必須不同,如果配置其他從機,注意修改id
server-id=2
# 中繼日志名,默認xxxxxxxxxxxx-relay-bin
#relay-log=relay-bin
重啟MySQL容器
docker restart atguigu-mysql-slave1
- step3:使用命令列登錄MySQL從服務器:
#進入容器:
docker exec -it atguigu-mysql-slave1 env LANG=C.UTF-8 /bin/bash
#進入容器內的mysql命令列
mysql -uroot -p
#修改默認密碼校驗方式
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
- step4:在從機上配置主從關系:
在從機上執行以下SQL操作
CHANGE MASTER TO MASTER_HOST='192.168.100.201',
MASTER_USER='atguigu_slave',MASTER_PASSWORD='123456', MASTER_PORT=3306,
MASTER_LOG_FILE='binlog.000003',MASTER_LOG_POS=1357;
2.3、啟動主從同步
啟動從機的復制功能,執行SQL:
START SLAVE;
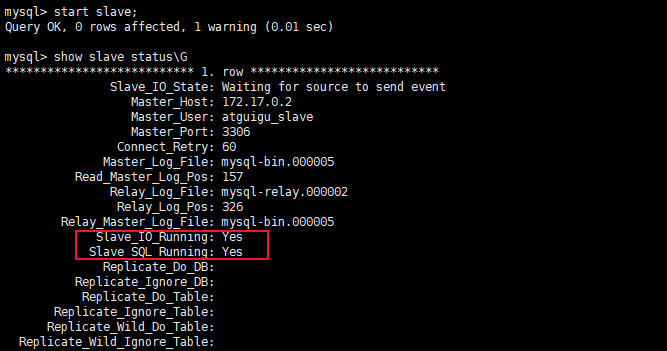
-- 查看狀態(不需要分號)
SHOW SLAVE STATUS\G
兩個關鍵行程:下面兩個引數都是Yes,則說明主從配置成功!
2.4、實作主從同步
在主機中執行以下SQL,在從機中查看資料庫、表和資料是否已經被同步
CREATE DATABASE db_user;
USE db_user;
CREATE TABLE t_user (
id BIGINT AUTO_INCREMENT,
uname VARCHAR(30),
PRIMARY KEY (id)
);
INSERT INTO t_user(uname) VALUES('zhang3');
INSERT INTO t_user(uname) VALUES(@@hostname);
2.5、停止和重置
需要的時候,可以使用如下SQL陳述句
-- 在從機上執行,功能說明:停止I/O 執行緒和SQL執行緒的操作,
stop slave;
-- 在從機上執行,功能說明:用于洗掉SLAVE資料庫的relaylog日志檔案,并重新啟用新的relaylog檔案,
reset slave;
-- 在主機上執行,功能說明:洗掉所有的binglog日志檔案,并將日志索引檔案清空,重新開始所有新的日志檔案,
-- 用于第一次進行搭建主從庫時,進行主庫binlog初始化作業;
reset master;
2.6、常見問題
問題1
啟動主從同步后,常見錯誤是Slave_IO_Running: No 或者 Connecting 的情況,此時查看下方的 Last_IO_ERROR錯誤日志,根據日志中顯示的錯誤資訊在網上搜索解決方案即可

典型的錯誤例如:Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Client requested master to start replication from position > file size'
解決方案:
-- 在從機停止slave
SLAVE STOP;
-- 在主機查看mater狀態
SHOW MASTER STATUS;
-- 在主機重繪日志
FLUSH LOGS;
-- 再次在主機查看mater狀態(會發現File和Position發生了變化)
SHOW MASTER STATUS;
-- 修改從機連接主機的SQL,并重新連接即可
問題2
啟動docker容器后提示 WARNING: IPv4 forwarding is disabled. Networking will not work.
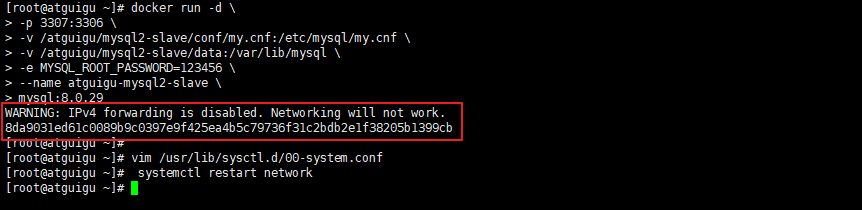
此錯誤,雖然不影響主從同步的搭建,但是如果想從遠程客戶端通過以下方式連接docker中的MySQL則沒法連接
C:\Users\administrator>mysql -h 192.168.100.201 -P 3306 -u root -p
解決方案:
#修改組態檔:
vim /usr/lib/sysctl.d/00-system.conf
#追加
net.ipv4.ip_forward=1
#接著重啟網路
systemctl restart network
第04章 ShardingSphere-JDBC讀寫分離
1、創建SpringBoot程式
1.1、創建專案
專案型別:Spring Initializr
SpringBoot腳手架:http://start.aliyun.com
專案名:sharding-jdbc-demo
SpringBoot版本:2.3.7.RELEASE
1.2、添加依賴
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
1.3、創建物體類
package com.atguigu.shardingjdbcdemo.entity;
@TableName("t_user")
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String uname;
}
1.4、創建Mapper
package com.atguigu.shardingjdbcdemo.mapper;
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
1.5、配置讀寫分離
application.properties:
# 應用名稱
spring.application.name=sharging-jdbc-demo
# 開發環境設定
spring.profiles.active=dev
# 記憶體模式
spring.shardingsphere.mode.type=Memory
# 配置真實資料源
spring.shardingsphere.datasource.names=master,slave1,slave2
# 配置第 1 個資料源
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://192.168.100.201:3306/db_user
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
# 配置第 2 個資料源
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://192.168.100.201:3307/db_user
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=123456
# 配置第 3 個資料源
spring.shardingsphere.datasource.slave2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave2.jdbc-url=jdbc:mysql://192.168.100.201:3308/db_user
spring.shardingsphere.datasource.slave2.username=root
spring.shardingsphere.datasource.slave2.password=123456
# 讀寫分離型別,如: Static,Dynamic
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static
# 寫資料源名稱
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=master
# 讀資料源名稱,多個從資料源用逗號分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,slave2
# 負載均衡演算法名稱
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=alg_round
# 負載均衡演算法配置
# 負載均衡演算法型別
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_round.type=ROUND_ROBIN
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_random.type=RANDOM
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave1=1
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave2=2
# 列印SQl
spring.shardingsphere.props.sql-show=true
2、測驗
2.1、讀寫分離測驗
package com.atguigu.shardingjdbcdemo;
@SpringBootTest
class ReadwriteTest {
@Autowired
private UserMapper userMapper;
/**
* 寫入資料的測驗
*/
@Test
public void testInsert(){
User user = new User();
user.setUname("張三豐");
userMapper.insert(user);
}
}
2.2、事務測驗
為了保證主從庫間的事務一致性,避免跨服務的分布式事務,ShardingSphere-JDBC的主從模型中,事務中的資料讀寫均用主庫,
- 不添加@Transactional:insert對主庫操作,select對從庫操作
- 添加@Transactional:則insert和select均對主庫操作
- 注意:在JUnit環境下的@Transactional注解,默認情況下就會對事務進行回滾(即使在沒加注解@Rollback,也會對事務回滾)
/**
* 事務測驗
*/
@Transactional//開啟事務
@Test
public void testTrans(){
User user = new User();
user.setUname("鐵錘");
userMapper.insert(user);
List<User> users = userMapper.selectList(null);
}
2.3、負載均衡測驗
/**
* 讀資料測驗
*/
@Test
public void testSelectAll(){
List<User> users1 = userMapper.selectList(null);
List<User> users2 = userMapper.selectList(null);//執行第二次測驗負載均衡
}
也可以在web請求中測驗負載均衡
package com.atguigu.shardingjdbcdemo.controller;
@RestController
@RequestMapping("/userController")
public class UserController {
@Autowired
private UserMapper userMapper;
/**
* 測驗負載均衡策略
*/
@GetMapping("selectAll")
public void selectAll(){
List<User> users = userMapper.selectList(null);
users.forEach(System.out::println);
}
}
常見錯誤

ShardingSphere-JDBC遠程連接的方式默認的密碼加密規則是:mysql_native_password
因此需要在服務器端修改服務器的密碼加密規則,如下:
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
第05章 ShardingSphere-JDBC垂直分片
1、準備服務器
服務器規劃:使用docker方式創建如下容器
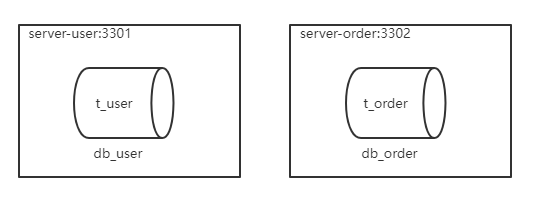
-
服務器:容器名
server-user,埠3301 -
服務器:容器名
server-order,埠3302
1.1、創建server-user容器
- step1:創建容器:
docker run -d \
-p 3301:3306 \
-v /atguigu/server/user/conf:/etc/mysql/conf.d \
-v /atguigu/server/user/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name server-user \
mysql:8.0.29
- step2:登錄MySQL服務器:
#進入容器:
docker exec -it server-user env LANG=C.UTF-8 /bin/bash
#進入容器內的mysql命令列
mysql -uroot -p
#修改默認密碼插件
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
- step3:創建資料庫:
CREATE DATABASE db_user;
USE db_user;
CREATE TABLE t_user (
id BIGINT AUTO_INCREMENT,
uname VARCHAR(30),
PRIMARY KEY (id)
);
1.2、創建server-order容器
- step1:創建容器:
docker run -d \
-p 3302:3306 \
-v /atguigu/server/order/conf:/etc/mysql/conf.d \
-v /atguigu/server/order/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name server-order \
mysql:8.0.29
- step2:登錄MySQL服務器:
#進入容器:
docker exec -it server-order env LANG=C.UTF-8 /bin/bash
#進入容器內的mysql命令列
mysql -uroot -p
#修改默認密碼插件
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
- step3:創建資料庫:
CREATE DATABASE db_order;
USE db_order;
CREATE TABLE t_order (
id BIGINT AUTO_INCREMENT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
2、程式實作
2.1、創建物體類
package com.atguigu.shardingjdbcdemo.entity;
@TableName("t_order")
@Data
public class Order {
@TableId(type = IdType.AUTO)
private Long id;
private String orderNo;
private Long userId;
private BigDecimal amount;
}
2.2、創建Mapper
package com.atguigu.shardingjdbcdemo.mapper;
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}
2.3、配置垂直分片
# 應用名稱
spring.application.name=sharding-jdbc-demo
# 環境設定
spring.profiles.active=dev
# 記憶體模式
spring.shardingsphere.mode.type=Memory
# 配置真實資料源
spring.shardingsphere.datasource.names=server-user,server-order
# 配置第 1 個資料源
spring.shardingsphere.datasource.server-user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-user.jdbc-url=jdbc:mysql://192.168.100.201:3301/db_user
spring.shardingsphere.datasource.server-user.username=root
spring.shardingsphere.datasource.server-user.password=123456
# 配置第 2 個資料源
spring.shardingsphere.datasource.server-order.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order.jdbc-url=jdbc:mysql://192.168.100.201:3302/db_order
spring.shardingsphere.datasource.server-order.username=root
spring.shardingsphere.datasource.server-order.password=123456
# 標準分片表配置(資料節點)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由資料源名 + 表名組成,以小數點分隔,
# <table-name>:邏輯表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=server-user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order.t_order
# 列印SQL
spring.shardingsphere.props.sql-show=true
3、測驗垂直分片
package com.atguigu.shardingjdbcdemo;
@SpringBootTest
public class ShardingTest {
@Autowired
private UserMapper userMapper;
@Autowired
private OrderMapper orderMapper;
/**
* 垂直分片:插入資料測驗
*/
@Test
public void testInsertOrderAndUser(){
User user = new User();
user.setUname("強哥");
userMapper.insert(user);
Order order = new Order();
order.setOrderNo("ATGUIGU001");
order.setUserId(user.getId());
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
/**
* 垂直分片:查詢資料測驗
*/
@Test
public void testSelectFromOrderAndUser(){
User user = userMapper.selectById(1L);
Order order = orderMapper.selectById(1L);
}
}
第06章 ShardingSphere-JDBC水平分片
1、準備服務器
服務器規劃:使用docker方式創建如下容器
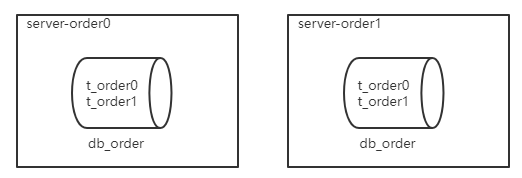
-
服務器:容器名
server-order0,埠3310 -
服務器:容器名
server-order1,埠3311
1.1、創建server-order0容器
- step1:創建容器:
docker run -d \
-p 3310:3306 \
-v /atguigu/server/order0/conf:/etc/mysql/conf.d \
-v /atguigu/server/order0/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name server-order0 \
mysql:8.0.29
- step2:登錄MySQL服務器:
#進入容器:
docker exec -it server-order0 env LANG=C.UTF-8 /bin/bash
#進入容器內的mysql命令列
mysql -uroot -p
#修改默認密碼插件
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
- step3:創建資料庫:
注意:水平分片的id需要在業務層實作,不能依賴資料庫的主鍵自增
CREATE DATABASE db_order;
USE db_order;
CREATE TABLE t_order0 (
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
CREATE TABLE t_order1 (
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
1.2、創建server-order1容器
- step1:創建容器:
docker run -d \
-p 3311:3306 \
-v /atguigu/server/order1/conf:/etc/mysql/conf.d \
-v /atguigu/server/order1/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name server-order1 \
mysql:8.0.29
- step2:登錄MySQL服務器:
#進入容器:
docker exec -it server-order1 env LANG=C.UTF-8 /bin/bash
#進入容器內的mysql命令列
mysql -uroot -p
#修改默認密碼插件
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
- step3:創建資料庫:和server-order0相同
注意:水平分片的id需要在業務層實作,不能依賴資料庫的主鍵自增
CREATE DATABASE db_order;
USE db_order;
CREATE TABLE t_order0 (
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
CREATE TABLE t_order1 (
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
2、基本水平分片
2.1、基本配置
#========================基本配置
# 應用名稱
spring.application.name=sharging-jdbc-demo
# 開發環境設定
spring.profiles.active=dev
# 記憶體模式
spring.shardingsphere.mode.type=Memory
# 列印SQl
spring.shardingsphere.props.sql-show=true
2.2、資料源配置
#========================資料源配置
# 配置真實資料源
spring.shardingsphere.datasource.names=server-user,server-order0,server-order1
# 配置第 1 個資料源
spring.shardingsphere.datasource.server-user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-user.jdbc-url=jdbc:mysql://192.168.100.201:3301/db_user
spring.shardingsphere.datasource.server-user.username=root
spring.shardingsphere.datasource.server-user.password=123456
# 配置第 2 個資料源
spring.shardingsphere.datasource.server-order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order0.jdbc-url=jdbc:mysql://192.168.100.201:3310/db_order
spring.shardingsphere.datasource.server-order0.username=root
spring.shardingsphere.datasource.server-order0.password=123456
# 配置第 3 個資料源
spring.shardingsphere.datasource.server-order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order1.jdbc-url=jdbc:mysql://192.168.100.201:3311/db_order
spring.shardingsphere.datasource.server-order1.username=root
spring.shardingsphere.datasource.server-order1.password=123456
2.3、標椎分片表配置
#========================標準分片表配置(資料節點配置)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由資料源名 + 表名組成,以小數點分隔,多個表以逗號分隔,支持 inline 運算式,
# <table-name>:邏輯表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=server-user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order0.t_order0,server-order0.t_order1,server-order1.t_order0,server-order1.t_order1
修改Order物體類的主鍵策略:
//@TableId(type = IdType.AUTO)//依賴資料庫的主鍵自增策略
@TableId(type = IdType.ASSIGN_ID)//分布式id
測驗:保留上面配置中的一個分片表節點分別進行測驗,檢查每個分片節點是否可用
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order0.t_order0
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order0.t_order1
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order1.t_order0
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order1.t_order1
測驗代碼:
/**
* 水平分片:插入資料測驗
*/
@Test
public void testInsertOrder(){
Order order = new Order();
order.setOrderNo("ATGUIGU001");
order.setUserId(1L);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
2.4、行運算式
優化上一步的分片表配置
https://shardingsphere.apache.org/document/5.1.1/cn/features/sharding/concept/inline-expression/
#========================標準分片表配置(資料節點配置)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由資料源名 + 表名組成,以小數點分隔,多個表以逗號分隔,支持 inline 運算式,
# <table-name>:邏輯表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=server-user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order$->{0..1}.t_order$->{0..1}
2.5、分片演算法配置
水平分庫:
分片規則:order表中user_id為偶數時,資料插入server-order0服務器,user_id為奇數時,資料插入server-order1服務器,這樣分片的好處是,同一個用戶的訂單資料,一定會被插入到同一臺服務器上,查詢一個用戶的訂單時效率較高,
#------------------------分庫策略
# 分片列名稱
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
# 分片演算法名稱
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_inline_userid
#------------------------分片演算法配置
# 行運算式分片演算法
# 分片演算法型別
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.type=INLINE
# 分片演算法屬性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.props.algorithm-expression=server-order$->{user_id % 2}
為了方便測驗,先設定只在 t_order0表上進行測驗
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order$->{0..1}.t_order0
測驗:可以分別測驗行運算式分片演算法和取模分片演算法
/**
* 水平分片:分庫插入資料測驗
*/
@Test
public void testInsertOrderDatabaseStrategy(){
for (long i = 0; i < 4; i++) {
Order order = new Order();
order.setOrderNo("ATGUIGU001");
order.setUserId(i + 1);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
}
水平分表:
分片規則:order表中order_no的哈希值為偶數時,資料插入對應服務器的t_order0表,order_no的哈希值為奇數時,資料插入對應服務器的t_order1表,因為order_no是字串形式,因此不能直接取模,
#------------------------分表策略
# 分片列名稱
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_no
# 分片演算法名稱
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
#------------------------分片演算法配置
# 哈希取模分片演算法
# 分片演算法型別
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.type=HASH_MOD
# 分片演算法屬性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.props.sharding-count=2
測驗前不要忘記將如下節點改回原來的狀態
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order$->{0..1}.t_order$->{0..1}
測驗:
/**
* 水平分片:分表插入資料測驗
*/
@Test
public void testInsertOrderTableStrategy(){
for (long i = 1; i < 5; i++) {
Order order = new Order();
order.setOrderNo("ATGUIGU" + i);
order.setUserId(1L);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
for (long i = 5; i < 9; i++) {
Order order = new Order();
order.setOrderNo("ATGUIGU" + i);
order.setUserId(2L);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
}
/**
* 測驗哈希取模
*/
@Test
public void testHash(){
//注意hash取模的結果是整個字串hash后再取模,和數值后綴是奇數還是偶數無關
System.out.println("ATGUIGU001".hashCode() % 2);
System.out.println("ATGUIGU0011".hashCode() % 2);
}
查詢測驗:
/**
* 水平分片:查詢所有記錄
* 查詢了兩個資料源,每個資料源中使用UNION ALL連接兩個表
*/
@Test
public void testShardingSelectAll(){
List<Order> orders = orderMapper.selectList(null);
orders.forEach(System.out::println);
}
/**
* 水平分片:根據user_id查詢記錄
* 查詢了一個資料源,每個資料源中使用UNION ALL連接兩個表
*/
@Test
public void testShardingSelectByUserId(){
QueryWrapper<Order> orderQueryWrapper = new QueryWrapper<>();
orderQueryWrapper.eq("user_id", 1L);
List<Order> orders = orderMapper.selectList(orderQueryWrapper);
orders.forEach(System.out::println);
}
2.6、分布式序列演算法
雪花演算法:
https://shardingsphere.apache.org/document/5.1.1/cn/features/sharding/concept/key-generator/
水平分片需要關注全域序列,因為不能簡單的使用基于資料庫的主鍵自增,
這里有兩種方案:一種是基于MyBatisPlus的id策略;一種是ShardingSphere-JDBC的全域序列配置,
基于MyBatisPlus的id策略:將Order類的id設定成如下形式
@TableId(type = IdType.ASSIGN_ID)
private Long id;
基于ShardingSphere-JDBC的全域序列配置:和前面的MyBatisPlus的策略二選一
#------------------------分布式序列策略配置
# 分布式序列列名稱
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id
# 分布式序列演算法名稱
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列演算法配置
# 分布式序列演算法型別
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
# 分布式序列演算法屬性配置
#spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.xxx=
此時,需要將物體類中的id策略修改成以下形式:
//當配置了shardingsphere-jdbc的分布式序列時,自動使用shardingsphere-jdbc的分布式序列
//當沒有配置shardingsphere-jdbc的分布式序列時,自動依賴資料庫的主鍵自增策略
@TableId(type = IdType.AUTO)
3、多表關聯
3.1、創建關聯表
在server-order0、server-order1服務器中分別創建兩張訂單詳情表t_order_item0、t_order_item1
我們希望同一個用戶的訂單表和訂單詳情表中的資料都在同一個資料源中,避免跨庫關聯,因此這兩張表我們使用相同的分片策略,
那么在t_order_item中我們也需要創建order_no和user_id這兩個分片鍵
CREATE TABLE t_order_item0(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
PRIMARY KEY(id)
);
CREATE TABLE t_order_item1(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
PRIMARY KEY(id)
);
3.2、創建物體類
package com.atguigu.shardingjdbcdemo.entity;
@TableName("t_order_item")
@Data
public class OrderItem {
//當配置了shardingsphere-jdbc的分布式序列時,自動使用shardingsphere-jdbc的分布式序列
@TableId(type = IdType.AUTO)
private Long id;
private String orderNo;
private Long userId;
private BigDecimal price;
private Integer count;
}
3.3、創建Mapper
package com.atguigu.shargingjdbcdemo.mapper;
@Mapper
public interface OrderItemMapper extends BaseMapper<OrderItem> {
}
3.4、配置關聯表
t_order_item的分片表、分片策略、分布式序列策略和t_order一致
#------------------------標準分片表配置(資料節點配置)
spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=server-order$->{0..1}.t_order_item$->{0..1}
#------------------------分庫策略
# 分片列名稱
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-column=user_id
# 分片演算法名稱
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-name=alg_inline_userid
#------------------------分表策略
# 分片列名稱
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=order_no
# 分片演算法名稱
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
#------------------------分布式序列策略配置
# 分布式序列列名稱
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.column=id
# 分布式序列演算法名稱
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.key-generator-name=alg_snowflake
3.5、測驗插入資料
同一個用戶的訂單表和訂單詳情表中的資料都在同一個資料源中,避免跨庫關聯
/**
* 測驗關聯表插入
*/
@Test
public void testInsertOrderAndOrderItem(){
for (long i = 1; i < 3; i++) {
Order order = new Order();
order.setOrderNo("ATGUIGU" + i);
order.setUserId(1L);
orderMapper.insert(order);
for (long j = 1; j < 3; j++) {
OrderItem orderItem = new OrderItem();
orderItem.setOrderNo("ATGUIGU" + i);
orderItem.setUserId(1L);
orderItem.setPrice(new BigDecimal(10));
orderItem.setCount(2);
orderItemMapper.insert(orderItem);
}
}
for (long i = 5; i < 7; i++) {
Order order = new Order();
order.setOrderNo("ATGUIGU" + i);
order.setUserId(2L);
orderMapper.insert(order);
for (long j = 1; j < 3; j++) {
OrderItem orderItem = new OrderItem();
orderItem.setOrderNo("ATGUIGU" + i);
orderItem.setUserId(2L);
orderItem.setPrice(new BigDecimal(1));
orderItem.setCount(3);
orderItemMapper.insert(orderItem);
}
}
}
4、系結表
需求:查詢每個訂單的訂單號和總訂單金額
4.1、創建VO物件
package com.atguigu.shardingjdbcdemo.entity;
@Data
public class OrderVo {
private String orderNo;
private BigDecimal amount;
}
4.2、添加Mapper方法
package com.atguigu.shardingjdbcdemo.mapper;
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
@Select({"SELECT o.order_no, SUM(i.price * i.count) AS amount",
"FROM t_order o JOIN t_order_item i ON o.order_no = i.order_no",
"GROUP BY o.order_no"})
List<OrderVo> getOrderAmount();
}
4.3、測驗關聯查詢
/**
* 測驗關聯表查詢
*/
@Test
public void testGetOrderAmount(){
List<OrderVo> orderAmountList = orderMapper.getOrderAmount();
orderAmountList.forEach(System.out::println);
}
4.4、配置系結表
在原來水平分片配置的基礎上添加如下配置:
#------------------------系結表
spring.shardingsphere.rules.sharding.binding-tables[0]=t_order,t_order_item
配置完系結表后再次進行關聯查詢的測驗:
-
如果不配置系結表:測驗的結果為8個SQL,多表關聯查詢會出現笛卡爾積關聯,
-
如果配置系結表:測驗的結果為4個SQL, 多表關聯查詢不會出現笛卡爾積關聯,關聯查詢效率將大大提升,
系結表:指分片規則一致的一組分片表, 使用系結表進行多表關聯查詢時,必須使用分片鍵進行關聯,否則會出現笛卡爾積關聯或跨庫關聯,從而影響查詢效率,
5、廣播表
5.1、什么是廣播表
指所有的分片資料源中都存在的表,表結構及其資料在每個資料庫中均完全一致, 適用于資料量不大且需要與海量資料的表進行關聯查詢的場景,例如:字典表,
廣播具有以下特性:
(1)插入、更新操作會實時在所有節點上執行,保持各個分片的資料一致性
(2)查詢操作,只從一個節點獲取
(3)可以跟任何一個表進行 JOIN 操作
5.2、創建廣播表
在server-order0、server-order1和server-user服務器中分別創建t_dict表
CREATE TABLE t_dict(
id BIGINT,
dict_type VARCHAR(200),
PRIMARY KEY(id)
);
5.3、程式實作
5.3.1、創建物體類
package com.atguigu.shardingjdbcdemo.entity;
@TableName("t_dict")
@Data
public class Dict {
//可以使用MyBatisPlus的雪花演算法
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String dictType;
}
5.3.2、創建Mapper
package com.atguigu.shardingjdbcdemo.mapper;
@Mapper
public interface DictMapper extends BaseMapper<Dict> {
}
5.3.3、配置廣播表
#資料節點可不配置,默認情況下,向所有資料源廣播
spring.shardingsphere.rules.sharding.tables.t_dict.actual-data-nodes=server-user.t_dict,server-order$->{0..1}.t_dict
# 廣播表
spring.shardingsphere.rules.sharding.broadcast-tables[0]=t_dict
5.4、測驗廣播表
@Autowired
private DictMapper dictMapper;
/**
* 廣播表:每個服務器中的t_dict同時添加了新資料
*/
@Test
public void testBroadcast(){
Dict dict = new Dict();
dict.setDictType("type1");
dictMapper.insert(dict);
}
/**
* 查詢操作,只從一個節點獲取資料
* 隨機負載均衡規則
*/
@Test
public void testSelectBroadcast(){
List<Dict> dicts = dictMapper.selectList(null);
dicts.forEach(System.out::println);
}
本文來自博客園,作者:自律即自由-,轉載請注明原文鏈接:https://www.cnblogs.com/deyo/p/17515677.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/556381.html
標籤:Java
下一篇:返回列表