好久都沒有寫點東西了,是時候有點寫東西的必要了,
去年下年底離職了,躺了幾個月,最近又兜兜轉轉換了一家公司繼續當牛馬了,前段時間八股文背了好多,難受呀,不過我也趁著前段時間自己也整理了屬于我自己的八股文,有好幾萬字吧,哈哈哈,以后就不用到處去找八股文了,
說回正題,這個group_concat的問題是最近在修復一個問題的時候發現的,是以前的人挖的坑,最近都不知道填了多少坑了,特喵的,
一. 問題背景
一個機構樹的表,就是那種有層級的,類似于下圖這樣的,然后我想查詢某一個公司下所有部門的員工,我們就要把這個機構表遞回找到一個公司下所有的部門,然后關聯一下用戶表查詢就行了

但是有人為了追求性能高一點,就把遞回查詢機構的邏輯使用使用find_in_set()函式和group_concat()函式封裝成了mysq的自定義函式,然后呼叫的時候在sql級別進行處理了,
DROP FUNCTION IF EXISTS queryChildrenAreaInfo; DELIMITER ;; CREATE FUNCTION queryChildrenAreaInfo(areaId INT) RETURNS VARCHAR(4000) BEGIN DECLARE sTemp VARCHAR(4000); DECLARE sTempChd VARCHAR(4000); SET sTemp='$'; SET sTempChd = CAST(areaId AS CHAR); WHILE sTempChd IS NOT NULL DO SET sTemp= CONCAT(sTemp,',',sTempChd); SELECT GROUP_CONCAT(id) INTO sTempChd FROM t_areainfo WHERE FIND_IN_SET(parent_id,sTempChd)>0; END WHILE; RETURN sTemp; END ;; DELIMITER ;
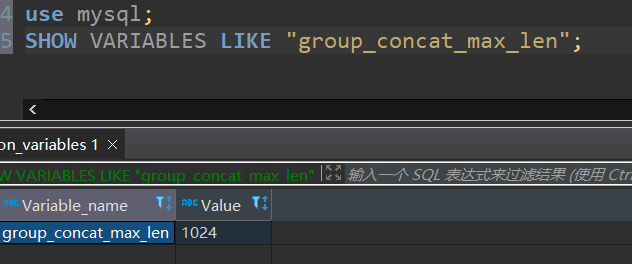
使用這種方式,在測驗環境肯定沒問題,但是到了生產環境機構表資料多了之后肯定就會踩坑,GROUP_CONCAT(id)回傳的資料有最大限制的,可以使用SHOW VARIABLES LIKE "group_concat_max_len" 進行查詢,默認是1024個位元組,下圖所示,
也就是如果查詢的資料超過1024個位元組后,只會保留前1024個位元組的資料,至于修復方法,需要修改mysql組態檔或者使用sql陳述句臨時修改:SET GLOBAL group_concat_max_len=10240000; SET SESSION group_concat_max_len=10240000;
如果沒有修改的話,就可能導致一個問題,一樣的代碼在測驗環境跑的很正常,一到生產上就拉胯,你肯定以為是代碼哪里和生產不一致,可能比對了很久,然后測驗環境自己也測驗了n次,但就是生產上資料不完整,此時你就會兩眼無神,懷疑人生....
二 解決方案
2.1. 直接修改mysql的組態檔,擴大group_concat_max_len的最大容量,至于擴大到多少,就要靠你自己去根據資料量去衡量了,不過一般的開發也不想去為了這個一點問題就改生產資料庫配置吧,麻煩....
2.2 如果是oracle資料庫,自帶了遞回查詢的關鍵字:start with connect by prior, 有興趣的可以自己研究一下,挺好用的,但是如果專案中是mysql資料庫,那就不適用了
2.3 使用sql進行遞回查詢,不過這種sql就是很雞兒難看懂,要是讓你維護這樣的sql你想打人的心都有了,所以我也不是很推薦
-- 根據?個?節點為id為1 查詢所有?節點(包含??) SELECT au.id, au.name, au.parent_id FROM (SELECT * FROM t_areainfo WHERE parent_id IS NOT NULL) au, (SELECT @pid := 1) pd WHERE FIND_IN_SET(parent_id, @pid) > 0 AND @pid := concat(@pid, ',', id) UNION SELECT id, name, parent_id FROM t_areainfo WHERE id = '1' ORDER BY id;
2.4. 其實我們陷入了誤區了,想一想有必要把這么復雜的邏輯都放到sql陳述句上處理么?其實這種越復雜的sql,會給服務器的壓力也是倍增的,而且特別難排查出問題,這點是最致命的,因為只要能排查出來的問題就都不是問題,
我的解決方案是: 首先查詢出所有的機構資訊,注意,如果機構資訊太多,我們可以再細化,比如先查詢一級機構,再查詢二級機構....分批次去查詢我們的資料,再記憶體級別進行組裝; 然后根據我們查詢的機構資訊再呼叫一次資料庫查詢用戶資訊就好了,雖然和資料庫互動可能多了兩三次,但是邏輯變得簡單了,有問題一下子就能排查出來了,
錯誤示范: 先查詢一級機構下所有的部門,然后遍歷每一個部門分別再去資料庫中查詢下一級部門.....這樣你會被打死的,千萬不要回圈中嵌套著查詢資料庫的邏輯
三 還有話說
繼續瞎逼逼幾句,最近就是搞公司的歷史遺留的專案,技術堆疊老,問題多,一個幾萬用戶的對內商城專案,扣減庫存的邏輯是查詢資料庫,記憶體中扣減了之后再將庫存更新到資料庫中......看到代碼我都驚呆了呀,
由于我剛來沒幾個月,之前聽他們討論有什么超賣問題,我想著這尼瑪不超賣就出了鬼了, 然后我就提出了這個缺陷, 并使用了資料庫樂觀鎖嘎嘎優化了,這段時間幫著壓測這個商城專案,真的就是一堆破代碼,我還要去給各種優化,性能起碼提升了好多倍都不止,尼瑪資料庫關鍵的索引都有不加的,有的sql執行都需要好幾秒的,加了索引之后30ms......
繼續茍著吧,現在這里最大的好處就是不怎么加班,干完自己的事情后五點半就可以走了,嘿嘿
--------------以上皆原創,給未來的自己留下一點學習的痕跡!--------轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/553567.html
標籤:其他
上一篇:Spring注解
下一篇:返回列表