Python128道面試題總結大全
- Python基礎
- 檔案操作
- 1.有一個jsonline格式的檔案?le.txt大小約為10K
- 2.補充缺失的代碼、
- 模塊與包
- 3.輸入日期, 判斷這一天是這一年的第幾天?
- 4.打亂一個排好序的list物件alist?
- 資料型別
- 5.現有字典 d= {'a':24,'g':52,'i':12,'k':33}請按value值進行排序?
- 6.字典推導式
- 7.請反轉字串 "aStr"?
- 8.將字串 "k:1 |k1:2|k2:3|k3:4",處理成字典 {k:1,k1:2,...}
- 9.請按alist中元素的age由大到小排序
- 10.下面代碼的輸出結果將是什么?
- 11.寫一個串列生成式,產生一個公差為11的等引數列
- 12.給定兩個串列,怎么找出他們相同的元素和不同的元素?
- 13.請寫出一段python代碼實作洗掉list里面的重復元素?
- 14.給定兩個list A,B ,請用找出A,B中相同與不同的元素
- 企業面試題
- 15.python新式類和經典類的區別?
- 16.python中內置的資料結構有幾種?
- 17.python如何實作單例模式?請寫出兩種實作方式?
- 18.反轉一個整數,例如-123 --> -321
- 19.設計實作遍歷目錄與子目錄,抓取.pyc檔案
- 20.一行代碼實作1-100之和
- 21.Python-遍歷串列時洗掉元素的正確做法
- 22.字串的操作題目
- 23.可變型別和不可變型別
- 24.is和==有什么區別?
- 25.求出串列所有奇數并構造新串列
- 26.用一行python代碼寫出1+2+3+10248
- 27.Python中變數的作用域?(變數查找順序)
- 28.字串 轉換成 123 ,不使用內置api,例如
- 29.Given an array of integers
- 30.python代碼實作洗掉一個list里面的重復元素
- 31.統計一個文本中單詞頻次最高的10個單詞?
- 32.請寫出一個函式滿足以下條件
- 33.使用單一的串列生成式來產生一個新的串列
- 34.用一行代碼生成[1,4,9,16,25,36,49,64,81,100]
- 35.輸入某年某月某日,判斷這一天是這一年的第幾天?
- 36.兩個有序串列,l1,l2,對這兩個串列進行合并不可使用extend
- 37.給定一個任意長度陣列,實作一個函式
- 38.寫一個函式找出一個整數陣列中,第二大的數
- 方法一
- 直接排序,輸出倒數第二個數即可
- 39.閱讀一下代碼他們的輸出結果是什么?
- 40.統計一段字串中字符出現的次數
- 41.super函式的具體用法和場景
- Python高級
- 元類
- 42.Python中類方法、類實體方法、靜態方法有何區別?
- 43.遍歷一個object的所有屬性,并print每一個屬性名?
- 44.寫一個類,并讓它盡可能多的支持運算子?
- 45.介紹Cython,Pypy Cpython Numba各有什么缺點
- 46.請描述抽象類和介面類的區別和聯系
- 47.Python中如何動態獲取和設定物件的屬性?
- 記憶體管理與垃圾回識訓制
- 48.哪些操作會導致Python記憶體溢位,怎么處理?
- 49.關于Python記憶體管理,下列說法錯誤的是 B
- 50.Python的記憶體管理機制及調優手段?
- 51.記憶體泄露是什么?如何避免?
- 函式
- 52.python常見的串列推導式?
- 53.簡述read、readline、readlines的區別?
- 54.什么是Hash(散列函式)?
- 55.python函式多載機制?
- 56.寫一個函式找出一個整數陣列中,第二大的數
- 57.手寫一個判斷時間的裝飾器
- 58.使用Python內置的?lter()方法來過濾?
- 59.撰寫函式的4個原則
- 60.函式呼叫引數的傳遞方式是值傳遞還是參考傳遞?
- 61.如何在function里面設定一個全域變數
- 62.對預設引數的理解 ?
- 64.帶引數的裝飾器?
- 65.為什么函式名字可以當做引數用?
- 66.Python中pass陳述句的作用是什么?
- 67.有這樣一段代碼,print c會輸出什么,為什么?
- 68.交 換 兩 個 變 量 的 值 ?
- 69.map函式和reduce函式?
- 70.回呼函式,如何通信的?
- 71.Python主要的內置資料型別都有哪些? print dir( ‘a ’) 的輸出?
- 72.map(lambda x:xx,[y for y in range(3)]) 的 輸 出 ?
- 73.hasattr() getattr() setattr() 函式使用詳解?
- 74.一句話解決階乘函式?
- 75.什么是lambda函式? 有什么好處?
- 76.遞回函式停止的條件?
- 77.下面這段代碼的輸出結果將是什么?請解釋,
- 78.什么是lambda函式?它有什么好處?寫一個匿名函式求兩個數的和
- 設計模式
- 79.對設計模式的理解,簡述你了解的設計模式?
- 80.請手寫一個單例
- 81.單例模式的應用場景有那些?
- 82.用一行代碼生成[1,4,9,16,25,36,49,64,81,100]
- 83.對裝飾器的理解,并寫出一個計時器記錄方法執行性能的裝飾器?
- 84.解釋以下什么是閉包?
- 85.函式裝飾器有什么作用?
- 86.生成器,迭代器的區別?
- 87.X是什么型別?
- 88.請用一行代碼 實作將1-N 的整數串列以3為單位分組
- 89.Python中yield的用法?
- 面向物件
- 90.Python中的可變物件和不可變物件?
- 91.Python的魔法方法
- 92.面向物件中怎么實作只讀屬性?
- 93.談談你對面向物件的理解?
- 正則運算式
- 94.a = “abbbccc”,用正則匹配為abccc,不管有多少b,就出現一次?
- 95.Python字串查找和替換?
- 96.用Python匹配HTML g tag的時候,<.> 和 <.*?> 有什么區別
- 97.正則運算式貪婪與非貪婪模式的區別?
- 98.寫出開頭匹配字母和下劃線,末尾是數字的正則運算式?
- 99.怎么過濾評論中的表情?
- 100.簡述Python里面search和match的區別
- 系統編程
- 101.行程總結
- 102.談談你對多行程,多執行緒,以及協程的理解,專案是否用?
- 103.Python例外使用場景有那些?
- 104.多執行緒共同操作同一個資料互斥鎖同步?
- 105.什么是多執行緒競爭?
- 106.請介紹一下Python的執行緒同步?
- 107.解釋以下什么是鎖,有哪幾種鎖?
- 108.什么是死鎖?
- 109.多執行緒互動訪問資料,如果訪問到了就不訪問了?
- 110.什么是執行緒安全,什么是互斥鎖?
- 111.說說下面幾個概念:同步,異步,阻塞,非阻塞?
- 112.什么是僵尸行程和孤兒行程?怎么避免僵尸行程?
- 113.python中行程與執行緒的使用場景?
- 114.執行緒是并發還是并行,行程是并發還是并行?
- 115.并行(parallel)和并發(concurrency)?
- 116.IO密集型和CPU密集型區別?
- 117.python asyncio的原理?
- 資料結構
- 118.陣列中出現次數超過一半的數字-Python版
- 119.求100以內的質數
- 120.無重復字符的最長子串-Python實作
- 121.冒泡排序的思想?
- 122.快速排序的思想?
- 123.斐波那契數列
- 124.如何翻轉一個單鏈表?
- 125.青蛙跳臺階問題
- 126.寫一個二分查找
- 127.Python實作一個Stack的資料結構
- 128.Python實作一個Queue的資料結構
Python基礎
檔案操作
1.有一個jsonline格式的檔案?le.txt大小約為10K
def get_lines():
with open('file.txt','rb') as f: return f.readlines()
if name == ' main ': for e in get_lines():
process(e) # 處理每一行資料
現在要處理一個大小為10G的檔案,但是記憶體只有4G,如果在只修改get_lines 函式而其他代碼保持不變的情況下,應該如何實作?需要考慮的問題都有那些?
def get_lines():
with open('file.txt','rb') as f: for i in f:
yield i
個人認為:還是設定下每次回傳的行數較好,否則讀取次數太多,
def get_lines(): l = []
with open('file.txt','rb') as f: data = f.readlines(60000)
l.append(data) yield l
Pandaaaa906提供的方法
from mmap import mmap
def get_lines(fp):
with open(fp,"r+") as f:
m = mmap(f.fileno(), 0) tmp = 0
for i, char in enumerate(m): if char==b"\n":
yield m[tmp:i+1].decode() tmp = i+1
if name ==" main ":
for i in get_lines("fp_some_huge_file"): print(i)
要考慮的問題有:記憶體只有4G無法一次性讀入10G檔案,需要分批讀入分批讀入資料要記錄每次讀入資料的位置,分批每次讀取資料的大小,太小會在讀取操作花費過多時間,
2.補充缺失的代碼、
def print_directory_contents(sPath): """
這個函式接收檔案夾的名稱作為輸入引數
回傳該檔案夾中檔案的路徑
以及其包含檔案夾中檔案的路徑
"""
import os
for s_child in os.listdir(s_path):
s_child_path = os.path.join(s_path, s_child) if os.path.isdir(s_child_path):
print_directory_contents(s_child_path) else:
print(s_child_path)
模塊與包
3.輸入日期, 判斷這一天是這一年的第幾天?
import datetime def dayofyear():
year = input("請輸入年份: ")
month = input("請輸入月份: ") day = input("請輸入天: ")
date1 = datetime.date(year=int(year),month=int(month),day=int(day)) date2 = datetime.date(year=int(year),month=1,day=1)
return (date1-date2).days+1
4.打亂一個排好序的list物件alist?
import random alist = [1,2,3,4,5]
random.shuffle(alist) print(alist)
資料型別
5.現有字典 d= {‘a’:24,‘g’:52,‘i’:12,‘k’:33}請按value值進行排序?
sorted(d.items(),key=lambda x:x[1])
x[0]代表用key進行排序;x[1]代表用value進行排序,
6.字典推導式
d = {key:value for (key,value) in iterable}
7.請反轉字串 “aStr”?
print("aStr"[::-1])
8.將字串 “k:1 |k1:2|k2:3|k3:4”,處理成字典 {k:1,k1:2,…}
str1 = "k:1|k1:2|k2:3|k3:4" def str2dict(str1):
dict1 = {}
for iterms in str1.split('|'): key,value = iterms.split(':') dict1[key] = value
return dict1
#字典推導式
d = {k:int(v) for t in str1.split("|") for k, v in (t.split(":"), )}
9.請按alist中元素的age由大到小排序
alist = [{'name':'a','age':20},{'name':'b','age':30},{'name':'c','age':25}] def sort_by_age(list1):
return sorted(alist,key=lambda x:x['age'],reverse=True)
10.下面代碼的輸出結果將是什么?
list = ['a','b','c','d','e'] print(list[10:])
代碼將輸出[],不會產生IndexError錯誤,就像所期望的那樣,嘗試用超出成員的個數的index來獲取某個串列的成員,例如,嘗試獲取list[10] 和之后的成員,會導致IndexError,然而,嘗試獲取串列的切片,開始的index超過了成員個數不會產生IndexError,而是僅僅回傳一個空串列,這成為特別讓人惡心的疑難雜癥,因為運行的時候沒有錯誤產生,導致Bug很難被追蹤到,
11.寫一個串列生成式,產生一個公差為11的等引數列
print([x 11 for x in range(10)])
12.給定兩個串列,怎么找出他們相同的元素和不同的元素?
list1 = [1,2,3]
list2 = [3,4,5] set1 = set(list1) set2 = set(list2)
print(set1 & set2)
print(set1 ^ set2)
13.請寫出一段python代碼實作洗掉list里面的重復元素?
l1 = ['b','c','d','c','a','a']
l2 = list(set(l1)) print(l2)
用list類的sort方法:
l1 = ['b','c','d','c','a','a']
l2 = list(set(l1)) l2.sort(key=l1.index) print(l2)
也可以這樣寫:
l1 = ['b','c','d','c','a','a']
l2 = sorted(set(l1),key=l1.index) print(l2)
也可以用遍歷:
l1 = ['b','c','d','c','a','a'] l2 = []
for i in l1:
if not i in l2: l2.append(i)
print(l2)
14.給定兩個list A,B ,請用找出A,B中相同與不同的元素
A,B 中相同元素: print(set(A)&set(B))
A,B 中不同元素: print(set(A)^set(B))
企業面試題
15.python新式類和經典類的區別?
a.在python里凡是繼承了object的類,都是新式類
b.Python3里只有新式類
c.Python2里面繼承object的是新式類,沒有寫父類的是經典類
d.經典類目前在Python里基本沒有應用
e.保持class與type的統一對新式類的實體執行a.class與type(a)的結果是一致的,對于舊式類來說就不一樣了,
f.對于多重繼承的屬性搜索順序不一樣新式類是采用廣度優先搜索,舊式類采用深度優先搜索,
16.python中內置的資料結構有幾種?
a.整型 int、 長整型 long、浮點型 ?oat、 復數 complex
b.字串 str、 串列 list、 元祖 tuple
c.字典 dict 、 集合 set
d.Python3 中沒有 long,只有無限精度的 int
17.python如何實作單例模式?請寫出兩種實作方式?
第一種方法:使用裝飾器
def singleton(cls): instances = {}
def wrapper( args, kwargs): if cls not in instances:
instances[cls] = cls( args, kwargs) return instances[cls]
return wrapper
@singleton
class Foo(object): pass
foo1 = Foo() foo2 = Foo()
print(foo1 is foo2) # True
第二種方法:使用基類
New 是真正創建實體物件的方法,所以重寫基類的new 方法,以此保證創建物件的時候只生成一個實體
class Singleton(object):
def new (cls, args, kwargs):
if not hasattr(cls, '_instance'):
cls._instance = super(Singleton, cls). new (cls, args, kwargs) return cls._instance
class Foo(Singleton): pass
foo1 = Foo() foo2 = Foo()
print(foo1 is foo2) # True
第三種方法:元類,元類是用于創建類物件的類,類物件創建實體物件時一定要呼叫call方法,因此在呼叫call時候保證始終只創建一個實體即可,type是python的元類
class Singleton(type):
def call (cls, args, kwargs): if not hasattr(cls, '_instance'):
cls._instance = super(Singleton, cls). call ( args, kwargs) return cls._instance
Python2
class Foo(object):
metaclass = Singleton
Python3
class Foo(metaclass=Singleton): pass
foo1 = Foo() foo2 = Foo()
print(foo1 is foo2) # True
18.反轉一個整數,例如-123 --> -321
class Solution(object): def reverse(self,x):
if -10<x<10:
return x str_x = str(x)
if str_x[0] !="-": str_x = str_x[::-1] x = int(str_x)
else:
str_x = str_x[1:][::-1] x = int(str_x)
x = -x
return x if -2147483648<x<2147483647 else 0 if name == ' main ':
s = Solution()
reverse_int = s.reverse(-120) print(reverse_int)
19.設計實作遍歷目錄與子目錄,抓取.pyc檔案
第一種方法:
import os
def get_files(dir,suffix): res = []
for root,dirs,files in os.walk(dir): for filename in files:
name,suf = os.path.splitext(filename) if suf == suffix:
res.append(os.path.join(root,filename))
print(res) get_files("./",'.pyc')
第二種方法:
import os
def pick(obj):
if obj.endswith(".pyc"): print(obj)
def scan_path(ph):
file_list = os.listdir(ph) for obj in file_list:
if os.path.isfile(obj): pick(obj)
elif os.path.isdir(obj): scan_path(obj)
if name ==' main ': path = input('輸入目錄') scan_path(path)
第三種方法
from glob import iglob
def func(fp, postfix):
for i in iglob(f"{fp}/ / {postfix}", recursive=True): print(i)
if name == " main ": postfix = ".pyc"
func("K:\Python_script", postfix)

20.一行代碼實作1-100之和
count = sum(range(0,101)) print(count)
21.Python-遍歷串列時洗掉元素的正確做法
遍歷在新在串列操作,洗掉時在原來的串列操作
a = [1,2,3,4,5,6,7,8]
print(id(a)) print(id(a[:])) for i in a[:]:
if i>5:
pass else:
a.remove(i) print(a)
print(' ')
print(id(a))
#filter a=[1,2,3,4,5,6,7,8]
b = filter(lambda x: x>5,a) print(list(b))
串列決議
a=[1,2,3,4,5,6,7,8]
b = [i for i in a if i>5] print(b)
倒序洗掉
因為串列總是‘向前移’,所以可以倒序遍歷,即使后面的元素被修改了,還沒有被遍歷的元素和其坐標還是保持不變的
a=[1,2,3,4,5,6,7,8]
print(id(a))
for i in range(len(a)-1,-1,-1): if a[i]>5:
pass else:
a.remove(a[i])
print(id(a)) print(' ---------- ')
print(a)
22.字串的操作題目
全字母短句 PANGRAM 是包含所有英文字母的句子,比如:A QUICK BROWN FOX JUMPS OVER THE LAZY DOG. 定義并實作一個方法 get_missing_letter, 傳入一個字串采納數,回傳引數字串變成一個 PANGRAM 中所缺失的字符,應該忽略傳入字串引數中的大小寫,回傳應該都是小寫字符并按字母順序排序(請忽略所有非 ACSII 字符)
下面示例是用來解釋,雙引號不需要考慮:
(0)輸入: “A quick brown for jumps over the lazy dog”
回傳: “”
(1)輸入: “A slow yellow fox crawls under the proactive dog”
回傳: “bjkmqz”
(2)輸入: “Lions, and tigers, and bears, oh my!”
回傳: “cfjkpquvwxz”
(3)輸入: “”
回傳:“abcdefghijklmnopqrstuvwxyz”
def get_missing_letter(a):
s1 = set("abcdefghijklmnopqrstuvwxyz") s2 = set(a.lower())
ret = "".join(sorted(s1-s2)) return ret
print(get_missing_letter("python"))
other ways to generate letters
range("a", "z")
方法一: import string
letters = string.ascii_lowercase
方法二:
letters = "".join(map(chr, range(ord('a'), ord('z') + 1)))
23.可變型別和不可變型別
1,可變型別有list,dict.不可變型別有string,number,tuple.
2,當進行修改操作時,可變型別傳遞的是記憶體中的地址,也就是說,直接修改記憶體中的值,并沒有開辟新的記憶體,
3,不可變型別被改變時,并沒有改變原記憶體地址中的值,而是開辟一塊新的記憶體,將原地址中的值復制過去,對這塊新開辟的記憶體中的值進行操作,
24.is和==有什么區別?
is:比較的是兩個物件的id值是否相等,也就是比較倆物件是否為同一個實體物件,是否指向同一個記憶體地址
== : 比較的兩個物件的內容/值是否相等,默認會呼叫物件的eq()方法
25.求出串列所有奇數并構造新串列
a = [1,2,3,4,5,6,7,8,9,10]
res = [ i for i in a if i%2==1] print(res)
26.用一行python代碼寫出1+2+3+10248
from functools import reduce
#1.使用sum內置求和函式
num = sum([1,2,3,10248])
print(num)
#2.reduce 函式
num1 = reduce(lambda x,y :x+y,[1,2,3,10248]) print(num1)

27.Python中變數的作用域?(變數查找順序)
函式作用域的LEGB順序
1.什么是LEGB?
L: local 函式內部作用域
E: enclosing 函式內部與內嵌函式之間
G: global 全域作用域
B: build-in 內置作用
python在函式里面的查找分為4種,稱之為LEGB,也正是按照這是順序來查找的
28.字串 轉換成 123 ,不使用內置api,例如
方法一: 利用 str 函式
def atoi(s):
num = 0 for v in s:
for j in range(10): if v == str(j):
num = num 10 + j
return num
方法二: 利用 ord 函式
def atoi(s):
num = 0 for v in s:
num = num 10 + ord(v) - ord('0') return num
方法三: 利用 函式
def atoi(s):
num = 0 for v in s:
t = "%s 1" % v n = eval(t)
num = num 10 + n return num
方法四: 結合方法二,使用 reduce ,一行解決
from functools import reduce def atoi(s):
return reduce(lambda num, v: num 10 + ord(v) - ord('0'), s, 0)
29.Given an array of integers
給定一個整數陣列和一個目標值,找出陣列中和為目標值的兩個數,你可以假設每個輸入只對應一種答案,且同樣的元素不能被重復利用,示例:給定nums = [2,7,11,15],target=9 因為 nums[0]+nums[1] = 2+7 =9,所以回傳[0,1]
class Solution:
def twoSum(self,nums,target): """
:type nums: List[int]
:type target: int
:rtype: List[int] """
d = {}
size = 0
while size < len(nums):
if target-nums[size] in d:
if d[target-nums[size]] <size:
return [d[target-nums[size]],size] else:
d[nums[size]] = size size = size +1
solution = Solution() list = [2,7,11,15]
target = 9
nums = solution.twoSum(list,target) print(nums)
class Solution(object):
def twoSum(self, nums, target): for i in range(len(nums)):
num = target - nums[i] if num in nums[i+1:]:
return [i, nums.index(num,i+1)]
給串列中的字典排序:假設有如下list物件,alist=[{“name”:“a”,“age”:20},{“name”:“b”,“age”:30},
{“name”:“c”,“age”:25}],將alist中的元素按照age從大到小排序 alist=[{“name”:“a”,“age”:20},
{“name”:“b”,“age”:30},{“name”:“c”,“age”:25}]
alist_sort = sorted(alist,key=lambda e: e. getitem ('age'),reverse=True)
30.python代碼實作洗掉一個list里面的重復元素
def distFunc1(a):
"""使用集合去重""" a = list(set(a)) print(a)
def distFunc2(a):
"""將一個串列的資料取出放到另一個串列中,中間作判斷""" list = []
for i in a:
if i not in list: list.append(i)
#如果需要排序的話用sort
list.sort() print(list)
def distFunc3(a):
"""使用字典""" b = {}
b = b.fromkeys(a) c = list(b.keys()) print(c)
if name == " main ":
a = [1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]
distFunc1(a) distFunc2(a) distFunc3(a)
31.統計一個文本中單詞頻次最高的10個單詞?
import re
方法一
def test(filepath): distone = {}
with open(filepath) as f:
for line in f:
line = re.sub("\W+", " ", line) lineone = line.split()
for keyone in lineone:
if not distone.get(keyone): distone[keyone] = 1
else:
distone[keyone] += 1
num_ten = sorted(distone.items(), key=lambda x:x[1], reverse=True)[:10] num_ten =[x[0] for x in num_ten]
return num_ten
方法二
使用 built-in 的 Counter 里面的 most_common import re
from collections import Counter
def test2(filepath):
with open(filepath) as f:
return list(map(lambda c: c[0], Counter(re.sub("\W+", " ", f.read()).split()).most_common(10)))
32.請寫出一個函式滿足以下條件
該函式的輸入是一個僅包含數字的list,輸出一個新的list,其中每一個元素要滿足以下條件:
1、該元素是偶數
2、該元素在原list中是在偶數的位置(index是偶數)
def num_list(num):
return [i for i in num if i %2 ==0 and num.index(i)%2==0]
num = [0,1,2,3,4,5,6,7,8,9,10]
result = num_list(num) print(result)
33.使用單一的串列生成式來產生一個新的串列
該串列只包含滿足以下條件的值,元素為原始串列中偶數切片
list_data = [1,2,5,8,10,3,18,6,20]
res = [x for x in list_data[::2] if x %2 ==0] print(res)
34.用一行代碼生成[1,4,9,16,25,36,49,64,81,100]
[x x for x in range(1,11)]
35.輸入某年某月某日,判斷這一天是這一年的第幾天?
import datetime
y = int(input("請輸入4位數字的年份:")) m = int(input("請輸入月份:"))
d = int(input("請輸入是哪一天"))
targetDay = datetime.date(y,m,d)
dayCount = targetDay - datetime.date(targetDay.year -1,12,31)
print("%s是 %s年的第%s天,"%(targetDay,y,dayCount.days))
36.兩個有序串列,l1,l2,對這兩個串列進行合并不可使用extend
def loop_merge_sort(l1,l2): tmp = []
while len(l1)>0 and len(l2)>0: if l1[0] <l2[0]:
tmp.append(l1[0]) del l1[0]
else:
tmp.append(l2[0]) del l2[0]
while len(l1)>0: tmp.append(l1[0]) del l1[0]
while len(l2)>0: tmp.append(l2[0]) del l2[0]
return tmp
37.給定一個任意長度陣列,實作一個函式
讓所有奇數都在偶數前面,而且奇數升序排列,偶數降序排序,如字串’1982376455’,變成’1355798642’
方法一
def func1(l):
if isinstance(l, str):
l = [int(i) for i in l] l.sort(reverse=True)
for i in range(len(l)): if l[i] % 2 > 0:
l.insert(0, l.pop(i))
print(''.join(str(e) for e in l))
方法二
def func2(l):
print("".join(sorted(l, key=lambda x: int(x) % 2 == 0 and 20 - int(x) or int(x))))
38.寫一個函式找出一個整數陣列中,第二大的數
def find_second_large_num(num_list): “”"
找出陣列第2大的數字
“”"
方法一
直接排序,輸出倒數第二個數即可
tmp_list = sorted(num_list)
print("方法一\nSecond_large_num is :", tmp_list[-2])
方法二
設定兩個標志位一個存盤最大數一個存盤次大數
two 存盤次大值,one 存盤最大值,遍歷一次陣列即可,先判斷是否大于 one,若大于將 one 的值給 two,將 num_list[i] 的值給 one,否則比較是否大于two,若大于直接將 num_list[i] 的值給 two,否則pass
one = num_list[0] two = num_list[0]
for i in range(1, len(num_list)): if num_list[i] > one:
two = one
one = num_list[i] elif num_list[i] > two:
two = num_list[i]
print("方法二\nSecond_large_num is :", two)
方法三
用 reduce 與邏輯符號 (and, or)
基本思路與方法二一樣,但是不需要用 if 進行判斷,
from functools import reduce
num = reduce(lambda ot, x: ot[1] < x and (ot[1], x) or ot[0] < x and (x, ot[1]) or ot, num_list, (0, 0))[0]
print("方法三\nSecond_large_num is :", num)
if name == ' main ':
num_list = [34, 11, 23, 56, 78, 0, 9, 12, 3, 7, 5]
find_second_large_num(num_list)
39.閱讀一下代碼他們的輸出結果是什么?
def multi():
return [lambda x : i x for i in range(4)] print([m(3) for m in multi()])
正確答案是[9,9,9,9],而不是[0,3,6,9]產生的原因是Python的閉包的后期系結導致的,這意味著在閉包中的變數是在內部函式被呼叫的時候被查找的,因為,最后函式被呼叫的時候,for回圈已經完成, i 的值最后是3,因此每一個回傳值的i都是3,所以最后的結果是[9,9,9,9]
40.統計一段字串中字符出現的次數
# 方法一
```python
def count_str(str_data):
"""定義一個字符出現次數的函式""" dict_str = {}
for i in str_data:
dict_str[i] = dict_str.get(i, 0) + 1 return dict_str
dict_str = count_str("AAABBCCAC") str_count_data = ""
for k, v in dict_str.items(): str_count_data += k + str(v)
print(str_count_data)
# 方法二
from collections import Counter
print("".join(map(lambda x: x[0] + str(x[1]), Counter("AAABBCCAC").most_common())))
41.super函式的具體用法和場景
https://python3-cookbook.readthedocs.io/zh_CN/latest/c08/p07_calling_method_on_parent_clas s.html
Python高級
元類
42.Python中類方法、類實體方法、靜態方法有何區別?
類方法: 是類物件的方法,在定義時需要在上方使用 @classmethod 進行裝飾,形參為cls,表示類物件,類物件和實體物件都可呼叫
類實體方法: 是類實體化物件的方法,只有實體物件可以呼叫,形參為self,指代物件本身;
靜態方法: 是一個任意函式,在其上方使用 @staticmethod 進行裝飾,可以用物件直接呼叫,靜態方法實際上跟該類沒有太大關系
43.遍歷一個object的所有屬性,并print每一個屬性名?
class Car:
def init (self,name,loss): # loss [價格,油耗,公里數] self.name = name
self.loss = loss
def getName(self):
return self.name
def getPrice(self):
# 獲取汽車價格
return self.loss[0]
def getLoss(self):
# 獲取汽車損耗值
return self.loss[1] self.loss[2]
Bmw = Car("寶馬",[60,9,500]) # 實體化一個寶馬車物件 print(getattr(Bmw,"name")) # 使用getattr()傳入物件名字,屬性值, print(dir(Bmw)) # 獲Bmw所有的屬性和方法
44.寫一個類,并讓它盡可能多的支持運算子?
class Array:
list = []
def init (self): print "constructor"
def del (self): print "destruct"
def str (self):
return "this self-defined array class"
def getitem (self,key): return self. list[key]
def len (self):
return len(self. list)
def Add(self,value):
self. list.append(value)
def Remove(self,index): del self. list[index]
def DisplayItems(self): print "show all items---" for item in self. list:
print item
45.介紹Cython,Pypy Cpython Numba各有什么缺點
Cython
46.請描述抽象類和介面類的區別和聯系
1.抽象類: 規定了一系列的方法,并規定了必須由繼承類實作的方法,由于有抽象方法的存在,所以抽象類不能實體化,可以將抽象類理解為毛坯房,門窗,墻面的樣式由你自己來定,所以抽象類與作為基 類的普通類的區別在于約束性更強
2.介面類:與抽象類很相似,表現在介面中定義的方法,必須由參考類實作,但他與抽象類的根本區別在于用途:與不同個體間溝通的規則,你要進宿舍需要有鑰匙,這個鑰匙就是你與宿舍的介面,你的舍友也有這個介面,所以他也能進入宿舍,你用手機通話,那么手機就是你與他人交流的介面
3.區別和關聯:
介面是抽象類的變體,介面中所有的方法都是抽象的,而抽象類中可以有非抽象方法,抽象類是宣告方法的存在而不去實作它的類
介面可以繼承,抽象類不行
介面定義方法,沒有實作的代碼,而抽象類可以實作部分方法
介面中基本資料型別為static而抽象類不是
47.Python中如何動態獲取和設定物件的屬性?
if hasattr(Parent, 'x'): print(getattr(Parent, 'x')) setattr(Parent, 'x',3)
print(getattr(Parent,'x'))
記憶體管理與垃圾回識訓制
48.哪些操作會導致Python記憶體溢位,怎么處理?
49.關于Python記憶體管理,下列說法錯誤的是 B
A,變數不必事先宣告 B,變數無須先創建和賦值而直接使用
C,變數無須指定型別 D,可以使用del釋放資源
50.Python的記憶體管理機制及調優手段?
記憶體管理機制: 參考計數、垃圾回收、記憶體池
參考計數:參考計數是一種非常高效的記憶體管理手段,當一個Python物件被參考時其參考計數增加1,當其不再被一個變數參考時則計數減1,當參考計數等于0時物件被洗掉,弱參考不會增加參考計數
垃圾回收:
1.參考計數
參考計數也是一種垃圾收集機制,而且也是一種最直觀、最簡單的垃圾收集技術,當Python的某個物件的參考計數降為0時,說明沒有任何參考指向該物件,該物件就成為要被回收的垃圾了,比如某個新建物件,它被分配給某個參考,物件的參考計數變為1,如果參考被洗掉,物件的參考計數為0,那么該物件就可以被垃圾回收,不過如果出現回圈參考的話,參考計數機制就不再起有效的作用了,
2.標記清除
https://foo?sh.net/python-gc.html
調優手段
1.手動垃圾回收
2.調高垃圾回收閾值
3.避免回圈參考
51.記憶體泄露是什么?如何避免?
記憶體泄漏指由于疏忽或錯誤造成程式未能釋放已經不再使用的記憶體,記憶體泄漏并非指記憶體在物理上的消失,而是應用程式分配某段記憶體后,由于設計錯誤,導致在釋放該段記憶體之前就失去了對該段記憶體的控制,從而造成了記憶體的浪費,
有 del () 函式的物件間的回圈參考是導致記憶體泄露的主兇,不使用一個物件時使用: del object 來洗掉一個物件的參考計數就可以有效防止記憶體泄露問題,
通過Python擴展模塊gc 來查看不能回收的物件的詳細資訊,
可以通過 sys.getrefcount(obj) 來獲取物件的參考計數,并根據回傳值是否為0來判斷是否記憶體泄露
函式
52.python常見的串列推導式?
[運算式 for 變數 in 串列] 或者 [運算式 for 變數 in 串列 if 條件]
53.簡述read、readline、readlines的區別?
read 讀取整個檔案
readline 讀取下一行
readlines 讀取整個檔案到一個迭代器以供我們遍歷
54.什么是Hash(散列函式)?
散列函式(英語:Hash function)又稱散列演算法、哈希函式,是一種從任何一種資料中創建小的數字
“指紋”的方法,散列函式把訊息或資料壓縮成摘要,使得資料量變小,將資料的格式固定下來,
該函式將資料打亂混合,重新創建一個叫做散列值(hash values,hash codes,hash sums,或hashes)的指紋,散列值通常用一個短的隨機字母和數字組成的字串來代表
55.python函式多載機制?
函式多載主要是為了解決兩個問題,
1,可變引數型別,
2,可變引數個數,
另外,一個基本的設計原則是,僅僅當兩個函式除了引數型別和引數個數不同以外,其功能是完全相同的,此時才使用函式多載,如果兩個函式的功能其實不同,那么不應當使用多載,而應當使用一個名字不同的函式,
好吧,那么對于情況 1 ,函式功能相同,但是引數型別不同,python 如何處理?答案是根本不需要處理,因為 python 可以接受任何型別的引數,如果函式的功能相同,那么不同的引數型別在 python 中很可能是相同的代碼,沒有必要做成兩個不同函式,
那么對于情況 2 ,函式功能相同,但引數個數不同,python 如何處理?大家知道,答案就是預設引數,對那些缺少的引數設定為預設引數即可解決問題,因為你假設函式功能相同,那么那些缺少的引數終歸是需要用的,
好了,鑒于情況 1 跟 情況 2 都有了解決方案,python 自然就不需要函式多載了,
56.寫一個函式找出一個整數陣列中,第二大的數
設定兩個標志位一個存盤最大數,一個存盤次大數 two 存盤次大值,one 存盤最大值,遍歷一次陣列即可,先判斷是否大于 one,若大于將one 的值給 two,將 num_list[i] 的值給 one,否則比較是否大于
two,若大于直接將 num_list[i]的值給two,否則pass,
def find_second_large_num(num_list): one = num_list[0]
two = num_list[0]
for i in range(1, len(num_list)): if num_list[i] > one:
two = one
one = num_list[i] elif num_list[i] > two:
two = num_list[i]
print("第二個大的數是 :", two)
num_list = [34, 11, 23, 56, 78, 0, 9, 12, 3, 7, 5]
find_second_large_num(num_list)
57.手寫一個判斷時間的裝飾器
import datetime
class TimeException(Exception):
def init (self, exception_info): super(). init ()
self.info = exception_info
def str (self): return self.info
def timecheck(func):
def wrapper( args, kwargs):
if datetime.datetime.now().year == 2019: func( args, kwargs)
else:
raise TimeException("函式已過時") return wrapper
@timecheck
def test(name):
print("Hello {}, 2019 Happy".format(name))
if name == " main ": test("backbp")
58.使用Python內置的?lter()方法來過濾?
list(filter(lambda x: x % 2 == 0, range(10)))
59.撰寫函式的4個原則
1.函式設計要盡量短小
2.函式宣告要做到合理、簡單、易于使用
3.函式引數設計應該考慮向下兼容
4.一個函式只做一件事情,盡量保證函式陳述句粒度的一致性
60.函式呼叫引數的傳遞方式是值傳遞還是參考傳遞?
Python的引數傳遞有:位置引數、默認引數、可變引數、關鍵字引數,函式的傳值到底是值傳遞還是參考傳遞、要分情況:
不可變引數用值傳遞:像整數和字串這樣的不可變物件,是通過拷貝進行傳遞的,因為你無論如何都不可能在原處改變不可變物件,
可變引數是參考傳遞:比如像串列,字典這樣的物件是通過參考傳遞、和C語言里面的用指標傳遞陣列很相似,可變物件能在函式內部改變,
61.如何在function里面設定一個全域變數
globals() # 回傳包含當前作用余全域變數的字典,
global 變數 設定使用全域變數
62.對預設引數的理解 ?
預設引數指在呼叫函式的時候沒有傳入引數的情況下,呼叫默認的引數,在呼叫函式的同時賦值時,所傳入的引數會替代默認引數,
*args是不定長引數,它可以表示輸入引數是不確定的,可以是任意多個,
**kwargs是關鍵字引數,賦值的時候是以鍵值對的方式,引數可以是任意多對在定義函式的時候不確定會有多少引數會傳入時,就可以使用兩個引數

64.帶引數的裝飾器?
帶定長引數的裝飾器
def new_func(func):
def wrappedfun(username, passwd):
if username == 'root' and passwd == '123456789':
print('通過認證')
print('開始執行附加功能') return func()
else:
print('用戶名或密碼錯誤') return
return wrappedfun
@new_func def origin():
print('開始執行函式')
origin('root','123456789')
帶不定長引數的裝飾器
def new_func(func): def wrappedfun( parts): if parts: counts =
len(parts) print(‘本系統包含 ‘, end=’’) for part in parts: print(part,
’ ‘,end=’’) print(‘等’, counts, ‘部分’) return func() else:
print(‘用戶名或密碼錯誤’) return func() return wrappedfun
65.為什么函式名字可以當做引數用?
Python中一切皆物件,函式名是函式在記憶體中的空間,也是一個物件
66.Python中pass陳述句的作用是什么?
在撰寫代碼時只寫框架思路,具體實作還未撰寫就可以用pass進行占位,是程式不報錯,不會進行任何操作,
67.有這樣一段代碼,print c會輸出什么,為什么?
a = 10
b = 20
c = [a]
a = 15
答:10對于字串,數字,傳遞是相應的值
68.交 換 兩 個 變 量 的 值 ?
a, b = b, a
69.map函式和reduce函式?
map(lambda x: x * x , [1, 2, 3, 4]) # 使用 lambda
# [1, 4, 9, 16]
reduce(lambda x, y: x * y, [1, 2, 3, 4]) # 相當于 ((1 * 2) * 3) * 4
# 24
70.回呼函式,如何通信的?
回呼函式是把函式的指標(地址)作為引數傳遞給另一個函式,將整個函式當作一個物件,賦值給呼叫的函式
71.Python主要的內置資料型別都有哪些? print dir( ‘a ’) 的輸出?
內建型別:布爾型別,數字,字串,串列,元組,字典,集合輸出字串’a’的內建方法
72.map(lambda x:xx,[y for y in range(3)]) 的 輸 出 ?
[0, 1, 4]
73.hasattr() getattr() setattr() 函式使用詳解?
hasattr(object,name)函式:
判斷一個物件里面是否有name屬性或者name方法,回傳bool值,有name屬性(方法)回傳True,否則回傳False,
class function_demo(object): name = 'demo'
def run(self):
return "hello function" functiondemo = function_demo()
res = hasattr(functiondemo, "name") # 判斷物件是否有name屬性,True
res = hasattr(functiondemo, "run") # 判斷物件是否有run方法,True res = hasattr(functiondemo, "age") # 判斷物件是否有age屬性,False print(res)
getattr(object, name[,default])函式:
獲取物件object的屬性或者方法,如果存在則列印出來,如果不存在,列印默認值,默認值可選,注意:如果回傳的是物件的方法,則列印結果是:方法的記憶體地址,如果需要運行這個方法,可以在后面添加括號().
functiondemo = function_demo()
getattr(functiondemo, "name")# 獲取name屬性,存在就列印出來 --- demo getattr(functiondemo, "run") # 獲取run 方法,存在列印出方法的記憶體地址 getattr(functiondemo, "age") # 獲取不存在的屬性, 報錯 getattr(functiondemo, "age", 18)# 獲取不存在的屬性,回傳一個默認值
setattr(object, name, values)函式:
給物件的屬性賦值,若屬性不存在,先創建再賦值
class function_demo(object): name = "demo"
def run(self):
return "hello function" functiondemo = function_demo()
res = hasattr(functiondemo, "age") # 判斷age屬性是否存在,False
print(res)
setattr(functiondemo, "age", 18) # 對age屬性進行賦值,無回傳值
res1 = hasattr(functiondemo, "age") # 再次判斷屬性是否存在,True
綜合使用
class function_demo(object): name = "demo"
def run(self):
return "hello function" functiondemo = function_demo()
res = hasattr(functiondemo, "addr") # 先判斷是否存在
if res:
addr = getattr(functiondemo, "addr") print(addr)
else:
addr = getattr(functiondemo, "addr", setattr(functiondemo, "addr", "北京首都"))
print(addr)

74.一句話解決階乘函式?
reduce(lambda x,y : x y,range(1,n+1))
75.什么是lambda函式? 有什么好處?
lambda 函式是一個可以接收任意多個引數(包括可選引數)并且回傳單個運算式值的函式
1.lambda函式比較輕便,即用即仍,很適合需要完成一項功能,但是此功能只在此一處使用,連名字都很隨意的情況下
2.匿名函式,一般用來給?lter,map這樣的函式式編程服務
3.作為回呼函式,傳遞給某些應用,比如訊息處理
76.遞回函式停止的條件?
遞回的終止條件一般定義在遞回函式內部,在遞回呼叫前要做一個條件判斷,根據判斷的結果選擇是繼續呼叫自身,還是return,,回傳終止遞回,
終止的條件:判斷遞回的次數是否達到某一限定值
2.判斷運算的結果是否達到某個范圍等,根據設計的目的來選擇
77.下面這段代碼的輸出結果將是什么?請解釋,
def multipliers():
return [lambda x: i x for i in range(4)] print([m(2) for m in multipliers()])
上面代碼的輸出結果是[6,6,6,6],不是我們想的[0,2,4,6]你如何修改上面的multipliers的定義產生想要的結果?
上述問題產生的原因是python閉包的延遲系結,這意味著內部函式被呼叫時,引數的值在閉包內進行查找,因此,當任何由multipliers()回傳的函式被呼叫時,i的值將在附近的范圍進行查找,那時,不管回傳的函式是否被呼叫,for回圈已經完成,i被賦予了最終的值3.
python
def multipliers(): for i in range(4):
yield lambda x: i x
def multipliers():
return [lambda x,i = i: i x for i in range(4)]
78.什么是lambda函式?它有什么好處?寫一個匿名函式求兩個數的和
lambda函式是匿名函式,使用lambda函式能創建小型匿名函式,這種函式得名于省略了用def宣告函式的標準步驟
設計模式
79.對設計模式的理解,簡述你了解的設計模式?
設計模式是經過總結,優化的,對我們經常會碰到的一些編程問題的可重用解決方案,一個設計模式并不像一個類或一個庫那樣能夠直接作用于我們的代碼,反之,設計模式更為高級,它是一種必須在特定情形下實作的一種方法模板,
常見的是工廠模式和單例模式
80.請手寫一個單例
#python2
class A(object):
instance = None
def new (cls, args, kwargs): if cls. instance is None:
cls. instance = objecet. new (cls) return cls. instance
else:
return cls. instance
81.單例模式的應用場景有那些?
單例模式應用的場景一般發現在以下條件下:
資源共享的情況下,避免由于資源操作時導致的性能或損耗等,如日志檔案,應用配置,
控制資源的情況下,方便資源之間的互相通信,如執行緒池等,1,網站的計數器 2,應用配置 3.多執行緒池 4
資料庫配置 資料庫連接池 5.應用程式的日志應用…
82.用一行代碼生成[1,4,9,16,25,36,49,64,81,100]
print([x x for x in range(1, 11)])

83.對裝飾器的理解,并寫出一個計時器記錄方法執行性能的裝飾器?
裝飾器本質上是一個callable object ,它可以讓其他函式在不需要做任何代碼變動的前提下增加額外功能,裝飾器的回傳值也是一個函式物件
import time
from functools import wraps
def timeit(func):
@wraps(func)
def wrapper( args, kwargs): start = time.clock()
ret = func( args, kwargs) end = time.clock() print('used:',end-start) return ret
return wrapper
@timeit def foo():
print('in foo()'foo())
84.解釋以下什么是閉包?
在函式內部再定義一個函式,并且這個函式用到了外邊函式的變數,那么將這個函式以及用到的一些變數稱之為閉包,
85.函式裝飾器有什么作用?
裝飾器本質上是一個callable object,它可以在讓其他函式在不需要做任何代碼的變動的前提下增加額外的功能,裝飾器的回傳值也是一個函式的物件,它經常用于有切面需求的場景,比如:插入日志,性能測驗,事務處理,快取,權限的校驗等場景,有了裝飾器就可以抽離出大量的與函式功能本身無關的雷同代碼并發并繼續使用,
86.生成器,迭代器的區別?
迭代器是遵循迭代協議的物件,用戶可以使用 iter() 以從任何序列得到迭代器(如 list, tuple, dictionary, set等),另一個方法則是創建一個另一種形式的迭代器——generator ,
要獲取下一個元素,則使用成員函式 next()(Python 2)或函式 next() function (Python 3) ,當沒有元素時,則引發 StopIteration 此例外,若要實作自己的迭代器,則只要實作next()(Python 2)或 next ()
( Python 3)
生成器(Generator),只是在需要回傳資料的時候使用yield陳述句,每次next()被呼叫時,生成器會回傳它脫離的位置(它記憶陳述句最后一次執行的位置和所有的資料值)
區別: 生成器能做到迭代器能做的所有事,而且因為自動創建iter()和next()方法,生成器顯得特別簡潔,而且生成器也是高效的,使用生成器運算式取代串列決議可以同時節省記憶體,除了創建和保存程式 狀態的自動方法,當發生器終結時,還會自動拋出StopIteration例外,
87.X是什么型別?
X= (i for i in range(10))
X是 generator型別
88.請用一行代碼 實作將1-N 的整數串列以3為單位分組
N =100
print ([[x for x in range(1,100)] [i:i+3] for i in range(0,100,3)])
89.Python中yield的用法?
yield就是保存當前程式執行狀態,你用for回圈的時候,每次取一個元素的時候就會計算一次,用yield的函式叫generator,和iterator一樣,它的好處是不用一次計算所有元素,而是用一次算一次,可以節省很多空間,generator每次計算需要上一次計算結果,所以用yield,否則一return,上次計算結果就沒了
面向物件
90.Python中的可變物件和不可變物件?
不可變物件,該物件所指向的記憶體中的值不能被改變,當改變某個變數時候,由于其所指的值不能被改變,相當于把原來的值復制一份后再改變,這會開辟一個新的地址,變數再指向這個新的地址,
可變物件,該物件所指向的記憶體中的值可以被改變,變數(準確的說是參考)改變后,實際上其所指的值直接發生改變,并沒有發生復制行為,也沒有開辟出新的地址,通俗點說就是原地改變,
Pyhton中,數值型別(int 和?oat),字串str、元祖tuple都是不可變型別,而串列list、字典dict、集合
set是可變型別
91.Python的魔法方法
魔法方法就是可以給你的類增加魔力的特殊方法,如果你的物件實作(多載)了這些方法中的某一個,那么這個方法就會在特殊的情況下被Python所呼叫,你可以定義自己想要的行為,而這一切都是自動發生的,它們經常是兩個下劃線包圍來命名的(比如 init , len ),Python的魔法方法是非常強大的所以了解其使用方法也變得尤為重要!
init 構造器,當一個實體被創建的時候初始化的方法,但是它并不是實體化呼叫的第一個方法,
new 才是實體化物件呼叫的第一個方法,它只取下cls引數,并把其他引數傳給 init .
new 很少使用,但是也有它適合的場景,尤其是當類繼承自一個像元祖或者字串這樣不經常改變的型別的時候,
call 讓一個類的實體像函式一樣被呼叫
getitem 定義獲取容器中指定元素的行為,相當于self[key]
getattr 定義當用戶試圖訪問一個不存在屬性的時候的行為,
setattr 定義當一個屬性被設定的時候的行為
getattribute 定義當一個屬性被訪問的時候的行為

92.面向物件中怎么實作只讀屬性?
將物件私有化,通過共有方法提供一個讀取資料的介面
class person:
def init (self, x): self. age = 10
def age(self): return self. age
t = person(22)
# t. age =100 print(t.age())
最好的方法
class MyCls(object):
weight = 50
@property
def weight(self): return self. weight
93.談談你對面向物件的理解?
面向物件是相當于面向程序而言的,面向程序語言是一種基于功能分析的,以演算法為中心的程式設計方法,而面向物件是一種基于結構分析的,以資料為中心的程式設計思想,在面向物件語言中有一個很重要的東西,叫做類,面向物件有三大特性:封裝、繼承、多型,
正則運算式
94.a = “abbbccc”,用正則匹配為abccc,不管有多少b,就出現一次?
思路:不管有多少個b替換成一個
re.sub(r'b+', 'b', a)
95.Python字串查找和替換?
a、str.find():正序字串查找函式函式原型:
str.find(substr [,pos_start [,pos_end ] ] )
回傳str中第一次出現的substr的第一個字母的標號,如果str中沒有substr則回傳-1,也就是說從左邊算 起的第一次出現的substr的首字母標號,
引數說明:
str: 代 表 原 字 符 串
substr:代表要查找的字串
pos_start:代表查找的開始位置,默認是從下標0開始查找 pos_end:代表查找的結束位置
例子:
'aabbcc.find('bb')' # 2
b、str.index():正序字串查找函式
index()函式類似于find()函式,在Python中也是在字串中查找子串第一次出現的位置,跟find()不同
的是,未找到則拋出例外,
函式原型:
str.index(substr [, pos_start, [ pos_end ] ] )
引數說明:
str: 代 表 原 字 符 串
substr:代表要查找的字串
pos_start:代表查找的開始位置,默認是從下標0開始查找 pos_end:代表查找的結束位置
例子:
'acdd l1 23'.index(' ') # 4
c、str.rfind():倒序字串查找函式函式原型:
str.rfind( substr [, pos_start [,pos_ end ] ])
回傳str中最后出現的substr的第一個字母的標號,如果str中沒有substr則回傳-1,也就是說從右邊算起 的第一次出現的substr的首字母標號,
引數說明:
str: 代 表 原 字 符 串
substr:代表要查找的字串
pos_start:代表查找的開始位置,默認是從下標0開始查找
pos_end:代表查找的結束位置
例子:
'adsfddf'.rfind('d') # 5
d、str.rindex():倒序字串查找函式
rindex()函式類似于rfind()函式,在Python中也是在字串中倒序查找子串最后一次出現的位置,跟
rfind()不同的是,未找到則拋出例外,
函式原型:
str.rindex(substr [, pos_start, [ pos_end ] ] )
引數說明:
str: 代 表 原 字 符 串
substr:代表要查找的字串
pos_start:代表查找的開始位置,默認是從下標0開始查找
pos_end:代表查找的結束位置
例子:
'adsfddf'.rindex('d') # 5
e、使用re模塊進行查找和替換
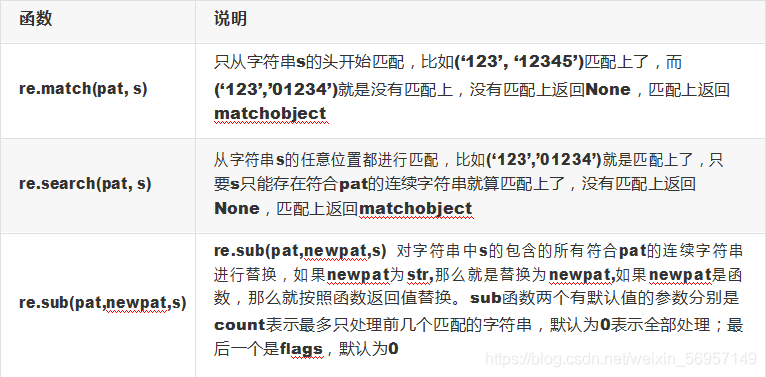
f、使用replace()進行替換:
基本用法:物件.replace(rgExp,replaceText,max)
其中,rgExp和replaceText是必須要有的,max是可選的引數,可以不加,
rgExp是指正則運算式模式或可用標志的正則運算式物件,也可以是 String 物件或文字;
replaceText是一個String 物件或字串文字;
max是一個數字,
對于一個物件,在物件的每個rgExp都替換成replaceText,從左到右最多max次,
s1='hello world' s1.replace('world','liming')
96.用Python匹配HTML g tag的時候,<.> 和 <.*?> 有什么區別
第一個代表貪心匹配,第二個代表非貪心;
?在一般正則運算式里的語法是指的"零次或一次匹配左邊的字符或運算式"相當于{0,1}
而當?后綴于 ,+,?,{n},{n,},{n,m}之后,則代表非貪心匹配模式,也就是說,盡可能少的匹配左邊的字
符或運算式,這里是盡可能少的匹配.(任意字符)
所以:第一種寫法是,盡可能多的匹配,就是匹配到的字串盡量長,第二中寫法是盡可能少的匹配,就是匹 配到的字串盡量短,
比如tag>tag>end,第一個會匹配tag>tag>,第二個會匹配,
97.正則運算式貪婪與非貪婪模式的區別?
貪婪模式:
定義:正則運算式去匹配時,會盡量多的匹配符合條件的內容識別符號:+,?, ,{n},{n,},{n,m}
匹配時,如果遇到上述識別符號,代表是貪婪匹配,會盡可能多的去匹配內容
非貪婪模式:
定義:正則運算式去匹配時,會盡量少的匹配符合條件的內容 也就是說,一旦發現匹配符合要求,立馬就匹配成功,而不會繼續匹配下去(除非有g,開啟下一組匹配)
識別符號:+?,??, ?,{n}?,{n,}?,{n,m}?
可以看到,非貪婪模式的識別符號很有規律,就是貪婪模式的識別符號后面加上一個?
參考文章:https://dailc.github.io/2017/07/06/regularExpressionGreedyAndLazy.html
98.寫出開頭匹配字母和下劃線,末尾是數字的正則運算式?
s1='_aai0efe00'
res=re.findall('^[a-zA-Z_]?[a-zA-Z0-9_]{1,}\d$',s1) print(res)

99.怎么過濾評論中的表情?
思路:主要是匹配表情包的范圍,將表情包的范圍用空替換掉
import re
pattern = re.compile(u'[\uD800-\uDBFF][\uDC00-\uDFFF]') pattern.sub('',text)
100.簡述Python里面search和match的區別
match()函式只檢測字串開頭位置是否匹配,匹配成功才會回傳結果,否則回傳None;
search()函式會在整個字串內查找模式匹配,只到找到第一個匹配然后回傳一個包含匹配資訊的物件,該對
象可以通過呼叫group()方法得到匹配的字串,如果字串沒有匹配,則回傳None,
系統編程
101.行程總結
行程:程式運行在作業系統上的一個實體,就稱之為行程,行程需要相應的系統資源:記憶體、時間片、
pid,
創建行程:
首先要匯入multiprocessing中的Process:創建一個Process物件;
創建Process物件時,可以傳遞引數;
p = Process(target=XXX,args=(tuple,),kwargs={key:value}) target = XXX 指 定 的 任 務 函 數 , 不 用 加 (),
args=(tuple,)kwargs={key:value}給任務函式傳遞的引數
使用start()啟動行程結束行程
給子行程指定函式傳遞引數Demo
import os
from mulitprocessing import Process import time
def pro_func(name,age, kwargs): for i in range(5):
print("子行程正在運行中,name=%s,age=%d,pid=%d"%(name,age,os.getpid()))
print(kwargs) time.sleep(0.2)
if name ==" main ":
#創建Process物件
p = Process(target=pro_func,args=('小明',18),kwargs={'m':20})
#啟動行程 p.start() time.sleep(1)
#1秒鐘之后,立刻結束子行程
p.terminate() p.join()
注意:行程間不共享全域變數行程之間的通信-Queue
在初始化Queue()物件時(例如q=Queue(),若在括號中沒有指定最大可接受的訊息數量,獲數量為負值時,那么就代表可接受的訊息數量沒有上限一直到記憶體盡頭)
Queue.qsize():回傳當前佇列包含的訊息數量
Queue.empty():如果佇列為空,回傳True,反之False
Queue.full():如果佇列滿了,回傳True,反之False
Queue.get([block[,timeout]]):獲取佇列中的一條訊息,然后將其從佇列中移除,
block默認值為True,
如果block使用默認值,且沒有設定timeout(單位秒),訊息佇列如果為空,此時程式將被阻塞(停在讀中狀態),直到訊息佇列讀到訊息為止,如果設定了timeout,則會等待timeout秒,若還沒讀取到任何訊息,則拋出“Queue.Empty"例外:
Queue.get_nowait()相當于Queue.get(False)
Queue.put(item,[block[,timeout]]):將item訊息寫入佇列,block默認值為True;
如果block使用默認值,且沒有設定timeout(單位秒),訊息佇列如果已經沒有空間可寫入,此時程式將被阻塞(停在寫入狀態),直到從訊息佇列騰出空間為止,如果設定了timeout,則會等待timeout秒,若還沒空間,則拋出”Queue.Full"例外
如果block值為False,訊息佇列如果沒有空間可寫入,則會立刻拋出"Queue.Full"例外;
Queue.put_nowait(item):相當Queue.put(item,False)
行程間通信Demo:
from multiprocessing import Process.Queue import os,time,random
#寫資料行程執行的代碼:
def write(q):
for value in ['A','B','C']: print("Put %s to queue...",%value) q.put(value) time.sleep(random.random())
#讀資料行程執行的代碼
def read(q):
while True:
if not q.empty(): value = q.get(True)
print("Get %s from queue.",%value) time.sleep(random.random())
else:
break
if name ==' main ':
#父行程創建Queue,并傳給各個子行程 q = Queue()
pw = Process(target=write,args=(q,)) pr = Process(target=read,args=(q,))
#啟動子行程pw ,寫入:
pw.start()
#等待pw結束 pw.join()
#啟動子行程pr,讀取: pr.start() pr.join()
#pr 行程里是死回圈,無法等待其結束,只能強行終止:
print('')
print('所有資料都寫入并且讀完')
行程池Pool
#coding:utf-8
from multiprocessing import Pool import os,time,random
def worker(msg):
t_start = time.time()
print("%s 開始執行,行程號為%d"%(msg,os.getpid()))
# random.random()隨機生成0-1之間的浮點數 time.sleep(random.random() 2)
t_stop = time.time()
print(msg,"執行完畢,耗時%0.2f”%(t_stop-t_start))
po = Pool(3)#定義一個行程池,最大行程數3 for i in range(0,10):
po.apply_async(worker,(i,)) print("---start --- ") po.close()
po.join()
print("----end --- ")
行程池中使用Queue
如果要使用Pool創建行程,就需要使用multiprocessing.Manager()中的Queue(),而不是
multiprocessing.Queue(),否則會得到如下的錯誤資訊:
RuntimeError: Queue objects should only be shared between processs through inheritance
from multiprocessing import Manager,Pool import os,time,random
def reader(q):
print("reader 啟動(%s),父行程為(%s)"%(os.getpid(),os.getpid())) for i in range(q.qsize()):
print("reader 從Queue獲取到訊息:%s"%q.get(True))
def writer(q):
print("writer 啟動(%s),父行程為(%s)"%(os.getpid(),os.getpid())) for i ini "itcast":
q.put(i)
if name == " main ": print("(%s)start"%os.getpid())
q = Manager().Queue()#使用Manager中的Queue
po = Pool() po.apply_async(wrtier,(q,)) time.sleep(1) po.apply_async(reader,(q,)) po.close()
po.join() print("(%s)End"%os.getpid())
102.談談你對多行程,多執行緒,以及協程的理解,專案是否用?
這個問題被問的概念相當之大,
行程:一個運行的程式(代碼)就是一個行程,沒有運行的代碼叫程式,行程是系統資源分配的最小單位,行程擁有自己獨立的記憶體空間,所有行程間資料不共享,開銷大,
執行緒: cpu調度執行的最小單位,也叫執行路徑,不能獨立存在,依賴行程存在,一個行程至少有一個執行緒,叫主執行緒,而多個執行緒共享記憶體(資料共享,共享全域變數),從而極大地提高了程式的運行效率,
協程: 是一種用戶態的輕量級執行緒,協程的調度完全由用戶控制,協程擁有自己的暫存器背景關系和堆疊,協程調度時,將暫存器背景關系和堆疊保存到其他地方,在切回來的時候,恢復先前保存的暫存器背景關系和 堆疊,直接操中堆疊則基本沒有內核切換的開銷,可以不加鎖的訪問全域變數,所以背景關系的切換非常快,

103.Python例外使用場景有那些?
異步的使用場景:
1、 不涉及共享資源,獲對共享資源只讀,即非互斥操作
2、 沒有時序上的嚴格關系
3、 不需要原子操作,或可以通過其他方式控制原子性
4、 常用于IO操作等耗時操作,因為比較影響客戶體驗和使用性能
5、 不影響主執行緒邏輯
104.多執行緒共同操作同一個資料互斥鎖同步?
import threading import time
class MyThread(threading.Thread): def run(self):
global num time.sleep(1)
if mutex.acquire(1): num +=1
msg = self.name + 'set num to ' +str(num) print msg
mutex.release()
num = 0
mutex = threading.Lock() def test():
for i in range(5): t = MyThread() t.start()
if name ==" main ": test()
105.什么是多執行緒競爭?
執行緒是非獨立的,同一個行程里執行緒是資料共享的,當各個執行緒訪問資料資源時會出現競爭狀態即:資料幾乎同步會被多個執行緒占用,造成資料混亂,即所謂的執行緒不安全
那么怎么解決多執行緒競爭問題?—鎖
鎖的好處: 確保了某段關鍵代碼(共享資料資源)只能由一個執行緒從頭到尾完整地執行能解決多執行緒資源競爭下的原子操作問題,
鎖的壞處: 阻止了多執行緒并發執行,包含鎖的某段代碼實際上只能以單執行緒模式執行,效率就大大地下降了
鎖的致命問題: 死鎖
106.請介紹一下Python的執行緒同步?
一、 setDaemon(False)
當一個行程啟動之后,會默認產生一個主執行緒,因為執行緒是程式執行的最小單位,當設定多執行緒時,主執行緒會創建多個子執行緒,在Python中,默認情況下就是setDaemon(False),主執行緒執行完自己的任務以后,就退出了,此時子執行緒會繼續執行自己的任務,直到自己的任務結束,
例子
import threading import time
def thread():
time.sleep(2)
print('---子執行緒結束---')
def main():
t1 = threading.Thread(target=thread) t1.start()
print('---主執行緒--結束')
if name ==' main ': main()
#執行結果
---主執行緒--結束
---子執行緒結束---
二、 setDaemon(True)
當我們使用setDaemon(True)時,這是子執行緒為守護執行緒,主執行緒一旦執行結束,則全部子執行緒被強制終止
例子
import threading import time
def thread():
time.sleep(2)
print(’---子執行緒結束---') def main():
t1 = threading.Thread(target=thread)
t1.setDaemon(True)# 設定子執行緒守護主執行緒 t1.start()
print('---主執行緒結束---')
if name ==' main ': main()
#執行結果
---主執行緒結束--- #只有主執行緒結束,子執行緒來不及執行就被強制結束
三、 join(執行緒同步)
join 所完成的作業就是執行緒同步,即主執行緒任務結束以后,進入堵塞狀態,一直等待所有的子執行緒結束以后,主執行緒再終止,
當設定守護執行緒時,含義是主執行緒對于子執行緒等待timeout的時間將會殺死該子執行緒,最后退出程式,所以說,如果有10個子執行緒,全部的等待時間就是每個timeout的累加和,簡單的來說,就是給每個子執行緒一個timeou的時間,讓他去執行,時間一到,不管任務有沒有完成,直接殺死,
沒有設定守護執行緒時,主執行緒將會等待timeout的累加和這樣的一段時間,時間一到,主執行緒結束,但是并沒有殺死子執行緒,子執行緒依然可以繼續執行,直到子執行緒全部結束,程式退出,
例子
import threading import time
def thread():
time.sleep(2)
print('---子執行緒結束---')
def main():
t1 = threading.Thread(target=thread)
t1.setDaemon(True) t1.start()
t1.join(timeout=1)#1 執行緒同步,主執行緒堵塞1s 然后主執行緒結束,子執行緒繼續執行
#2 如果不設定timeout引數就等子執行緒結束主執行緒再結束
#3 如果設定了setDaemon=True和timeout=1主執行緒等待1s后會強制殺死
子執行緒,然后主執行緒結束
print('---主執行緒結束---')
if name ==' main ': main()
107.解釋以下什么是鎖,有哪幾種鎖?
鎖(Lock)是python提供的對執行緒控制的物件,有互斥鎖,可重入鎖,死鎖,
108.什么是死鎖?
若干子執行緒在系統資源競爭時,都在等待對方對某部分資源解除占用狀態,結果是誰也不愿先解鎖,互相干等著,程式無法執行下去,這就是死鎖,
GIL鎖 全域解釋器鎖
作用: 限制多執行緒同時執行,保證同一時間只有一個執行緒執行,所以cython里的多執行緒其實是偽多執行緒!
所以python里常常使用協程技術來代替多執行緒,協程是一種更輕量級的執行緒,
行程和執行緒的切換時由系統決定,而協程由我們程式員自己決定,而模塊gevent下切換是遇到了耗時操作時才會切換
三者的關系:行程里有執行緒,執行緒里有協程,
109.多執行緒互動訪問資料,如果訪問到了就不訪問了?
怎么避免重讀?
創建一個已訪問資料串列,用于存盤已經訪問過的資料,并加上互斥鎖,在多執行緒訪問資料的時候先查看資料是否在已訪問的串列中,若已存在就直接跳過,
110.什么是執行緒安全,什么是互斥鎖?
每個物件都對應于一個可稱為’互斥鎖‘的標記,這個標記用來保證在任一時刻,只能有一個執行緒訪問該物件,
同一行程中的多執行緒之間是共享系統資源的,多個執行緒同時對一個物件進行操作,一個執行緒操作尚未結束,另一執行緒已經對其進行操作,導致最終結果出現錯誤,此時需要對被操作物件添加互斥鎖,保證每個執行緒對該物件的操作都得到正確的結果,
111.說說下面幾個概念:同步,異步,阻塞,非阻塞?
同步: 多個任務之間有先后順序執行,一個執行完下個才能執行,
異步: 多個任務之間沒有先后順序,可以同時執行,有時候一個任務可能要在必要的時候獲取另一個同時執行的任務的結果,這個就叫回呼!
阻塞: 如果卡住了呼叫者,呼叫者不能繼續往下執行,就是說呼叫者阻塞了,非阻塞: 如果不會卡住,可以繼續執行,就是說非阻塞的,
同步異步相對于多任務而言,阻塞非阻塞相對于代碼執行而言,

112.什么是僵尸行程和孤兒行程?怎么避免僵尸行程?
孤兒行程: 父行程退出,子行程還在運行的這些子行程都是孤兒行程,孤兒行程將被init 行程(行程號為1)所收養,并由init 行程對他們完成狀態收集作業,
僵尸行程: 行程使用fork 創建子行程,如果子行程退出,而父行程并沒有呼叫wait 獲waitpid 獲取子行程的狀態資訊,那么子行程的行程描述符仍然保存在系統中的這些行程是僵尸行程,
避免僵尸行程的方法:
1.fork 兩次用孫子行程去完成子行程的任務
2.用wait()函式使父行程阻塞
3.使用信號量,在signal handler 中呼叫waitpid,這樣父行程不用阻塞
113.python中行程與執行緒的使用場景?
多行程適合在CPU密集操作(cpu操作指令比較多,如位多的的浮點運算),
多執行緒適合在IO密性型操作(讀寫資料操作比多的的,比如爬蟲)
114.執行緒是并發還是并行,行程是并發還是并行?
執行緒是并發,行程是并行;
行程之間互相獨立,是系統分配資源的最小單位,同一個執行緒中的所有執行緒共享資源,
115.并行(parallel)和并發(concurrency)?
并行: 同一時刻多個任務同時在運行
不會在同一時刻同時運行,存在交替執行的情況,實作并行的庫有: multiprocessing
實作并發的庫有: threading
程式需要執行較多的讀寫、請求和回復任務的需要大量的IO操作,IO密集型操作使用并發更好,
CPU運算量大的程式,使用并行會更好
116.IO密集型和CPU密集型區別?
IO密集型: 系統運行,大部分的狀況是CPU在等 I/O(硬碟/記憶體)的讀/寫
CPU密集型: 大部分時間用來做計算,邏輯判斷等CPU動作的程式稱之CPU密集型,
117.python asyncio的原理?
asyncio這個庫就是使用python的yield這個可以打斷保存當前函式的背景關系的機制, 封裝好了selector擺脫掉了復雜的回呼關系
資料結構
118.陣列中出現次數超過一半的數字-Python版
思路:在遍歷陣列時保存兩個值:一是陣列中一個數字,一是次數,遍歷下一個數字時,若它與之前保存的數字相同,則次數加1,否則次數減1;若次數為0,則保存下一個數字,并將次數置為1,遍歷結束后,所保存的數字即為所求,然后再判斷它是否符合條件即可,
時間復雜度:O(N)
def MoreThanHalfNum_Solution(numbers): len1 = len(numbers)
if len1==0:
return 0 elif len1>=1:
# 遍歷每個元素,并記錄次數;若與前一個元素相同,則次數加1,否則次數減1
res = numbers[0] # 初始值
count = 1 # 次數
for i in range(1,len1): if count == 0:
# 更新result的值為當前元素,并置次數為1
res = numbers[i] count = 1
elif numbers[i] == res: count += 1 # 相同則加1
elif numbers[i] != res: count -= 1 # # 不同則加1
# 判斷res是否符合條件,即出現次數大于陣列長度的一半
counts = 0
for j in range(len1):
if numbers[j] == res: counts += 1
if counts>len1//2: return res
else:
return 0
119.求100以內的質數
#求100以內的全部素數 L=[]
for x in range(100): if x<2:
continue
for i in range(2,x): if x%i==0:
break
else: #走到此處,x一定是素數 L.append(x)
print("100以內的全部素數有:",L)
120.無重復字符的最長子串-Python實作
可以利用滑動視窗、動態規劃、雙指標等方法解決該問題,詳情見LeetCode第三題,這里給出雙指標解題思路,
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int: res = 0
mark = set() # 用集合標明是否有出現重復字母
r = 0 # 右指標
for i in range(len(s)): if i != 0:
mark.remove(s[i - 1])
while r < len(s) and s[r] not in mark: # 如果不滿足條件說明r走到了s的盡頭或r指向的元素
mark.add(s[r]) # 將當前r指向的字母加入集合
r += 1
res = max(res, r - i) # 在每一個位置更新最大值
return res
121.冒泡排序的思想?
冒泡排序是一種簡單直觀的排序演算法,它重復地走訪過要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來,走訪數列的作業是重復地進行直到沒有再需要交換,也就是說該數列已經排序完成,
演算法步驟:
1、比較相鄰的元素,如果第一個比第二個大,就交換他們兩個,
2、對每一對相鄰元素作同樣的作業,從開始第一對到結尾的最后一對,這步做完后,最后的元素會是最大的數,
3、針對所有的元素重復以上的步驟,除了最后一個,
4、持續每次對越來越少的元素重復上面的步驟,直到沒有任何一對數字需要比較,
122.快速排序的思想?
def bubbleSort(arr):
for i in range(1, len(arr)):
for j in range(0, len(arr)-i): if arr[j] > arr[j+1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
快速排序是由東尼·霍爾所發展的一種排序演算法,在平均狀況下,排序 n 個專案要 Ο(nlogn) 次比較,在最壞狀況下則需要 Ο(n2) 次比較,但這種狀況并不常見,事實上,快速排序通常明顯比其他 Ο(nlogn)演算法更快,因為它的內部回圈(inner loop)可以在大部分的架構上很有效率地被實作出來,
快速排序使用分治法(Divide and conquer)策略來把一個串行(list)分為兩個子串行(sub-lists),快速排序又是一種分而治之思想在排序演算法上的典型應用,本質上來看,快速排序應該算是在冒泡排序基礎上的遞回分治法,
演算法步驟:
1、從數列中挑出一個元素,稱為 “基準”(pivot);
2、重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的后面(相同的數可以到任一邊),在這個磁區退出之后,該基準就處于數列的中間位置,這個稱為磁區(partition)操作;
3、遞回地(recursive)把小于基準值元素的子數列和大于基準值元素的子數列排序;
def quickSort(arr, left=None, right=None):
left = 0 if not isinstance(left,(int, float)) else left
right = len(arr)-1 if not isinstance(right,(int, float)) else right if left < right:
partitionIndex = partition(arr, left, right) quickSort(arr, left, partitionIndex-1) quickSort(arr, partitionIndex+1, right)
return arr
def partition(arr, left, right): pivot = left
index = pivot+1 i = index
while i <= right:
if arr[i] < arr[pivot]: swap(arr, i, index) index+=1
i+=1
swap(arr,pivot,index-1) return index-1
def swap(arr, i, j):
arr[i], arr[j] = arr[j], arr[i]
123.斐波那契數列
數列定義:
f 0 = f 1 = 1
f n = f (n-1) + f (n-2)
根據定義
速度很慢,另外(暴堆疊注意!?) O(fibonacci n)
def fibonacci(n):
if n == 0 or n == 1: return 1
return fibonacci(n - 1) + fibonacci(n - 2)
線性時間的
狀態/回圈
def fibonacci(n): a, b = 1, 1
for _ in range(n): a, b = b, a + b
return a
遞回
def fibonacci(n): def fib(n_, s):
if n_ == 0:
return s[0] a, b = s
return fib(n_ - 1, (b, a + b))
return fib(n, (1, 1))
map(zipwith)
def fibs():
yield 1
fibs_ = fibs() yield next(fibs_) fibs = fibs()
for fib in map(lambad a, b: a + b, fibs_, fibs ): yield fib
def fibonacci(n): fibs_ = fibs() for _ in range(n):
next(fibs_) return next(fibs)
做快取
def cache(fn): cached = {}
def wrapper( args):
if args not in cached: cached[args] = fn( args)
return cached[args] wrapper. name = fn. name return wrapper
@cache
def fib(n):
if n < 2:
return 1
return fib(n-1) + fib(n-2)
利用 funtools.lru_cache 做快取
from functools import lru_cache
@lru_cache(maxsize=32) def fib(n):
if n < 2:
return 1
return fib(n-1) + fib(n-2)
Logarithmic
矩陣
import numpy as np
def fibonacci(n):
return (np.matrix([[0, 1], [1, 1]]) n)[1, 1
不是矩陣
def fibonacci(n): def fib(n):
if n == 0:
return (1, 1) elif n == 1:
return (1, 2)
a, b = fib(n // 2 - 1) c = a + b
if n % 2 == 0:
return (a a + b b, c c - a a) return (c c - a a, b b + c c)
return fib(n)[0]

124.如何翻轉一個單鏈表?
class Node:
def init (self,data=None,next=None): self.data = data
self.next = next
def rev(link): pre = link
cur = link.next pre.next = None while cur:
temp = cur.next
cur.next = pre pre = cur
cur = tmp return pre
if name == ' main ':
link = Node(1,Node(2,Node(3,Node(4,Node(5,Node(6,Node7,Node(8.Node(9)))))))) root = rev(link)
while root:
print(roo.data) root = root.next
125.青蛙跳臺階問題
一只青蛙要跳上n層高的臺階,一次能跳一級,也可以跳兩級,請問這只青蛙有多少種跳上這個n層臺階的方法?
方法1:遞回
設青蛙跳上n級臺階有f(n)種方法,把這n種方法分為兩大類,第一種最后一次跳了一級臺階,這類共有
f(n-1)種,第二種最后一次跳了兩級臺階,這種方法共有f(n-2)種,則得出遞推公式f(n)=f(n-1) + f(n-2),顯然
f(1)=1,f(2)=2,這種方法雖然代碼簡單,但效率低,會超出時間上限
class Solution:
def climbStairs(self,n): if n ==1:
return 1 elif n==2:
return 2 else:
return self.climbStairs(n-1) + self.climbStairs(n-2)
方法2:用回圈來代替遞回
class Solution:
def climbStairs(self,n): if n==1 or n==2:
return n a,b,c = 1,2,3
for i in range(3,n+1): c = a+b
a = b
b = c return c
126.寫一個二分查找
程序:首先假設表中元素是按升序(降序)排列,將表中間位置記錄的關鍵字與查找關鍵字比較,如果兩者相等,則查找成功;否則利用中間位置記錄將表分成前、后兩個子表,如果中間位置記錄的關鍵字大于查找關鍵字,則進一步查找前一子表,否則進一步查找后一子表,重復以上程序,直到找到滿足條件的記錄,使查找成功,或直到子表不存在為止,此時查找不成功,
def binarySearch(alist, item): first = 0 #最小數下標
last = len(alist) - 1 #最大數下標
while first <= last:#只有當first小于High的時候證明中間有數 mid = (first + last)//2 #中間數下標
print(mid)
if alist[mid] == item: #如果中間數下標等于item, 回傳
return mid
elif alist[mid] >item: #如果item在中間數左邊, 移動last下標
last = mid - 1
else: #如果val在中間數右邊, 移動first下標
first = mid+1 return -1
127.Python實作一個Stack的資料結構
"""堆疊 先進后出,后進先出""""" class Stack(object):
"""創建一個新堆疊"""
def init (self):
"""初始化堆疊""" self.data = []
def push(self,item):
"""添加一個新的元素item到堆疊頂""" return self.data.append(item)
def pop(self):
"""彈出堆疊頂元素""" return self.data.pop()
def peek(self):
"""回傳堆疊頂元素""" return self.data[-1]
# return self.data[len(self.data)-1] def is_empty(self):
"""判斷堆疊是否為空"""
return self.data == [] def size(self):
"""回傳堆疊的元素個數"""
return len(self.data)
128.Python實作一個Queue的資料結構
"""佇列 先進先出""""" class Queue(object):
def init (self):
"""創建一個空的佇列""" self.data = []
def enqueue(self,item):
"""往佇列中添加一個item元素""" return self.data.insert(0,item)
def dequeue(self):
"""從佇列頭部洗掉一個元素""" return self.data.pop()
def is_empty(self):
"""判斷一個佇列是否為空""" return self.data == [ ]
def size(self):
"""回傳佇列的大小""" return len(self.data)

如果你也想掌握一門門技能就從現在開始學讓自己變得更好吧,通通無償分享給你們!免費自取!●:關十后臺call“學習”●:評論:面試題
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/278089.html
標籤:python