序
“我不想要一份完整的報告,只要給我一份結果摘要就好”,我經常發現自己處于這種狀況 -- 無論是在大學里還是在我的職業生涯中,我們準備一份全面的報告,但老師/主管卻只有時間閱讀摘要,
聽起來很熟悉吧?嗯,我決定做點什么,手動將報告轉換為匯總版本太耗時了,對嗎?我能依靠嗎 自然語言處理 (NLP) 幫助我的技巧?
這就是使用深度學習進行文本摘要真正幫助我的地方,它解決了一個一直困擾我的問題- 現在我們的模型可以理解整個文本的背景關系 ,對于我們所有需要快速知道檔案摘要的人來說,這是一個夢想成真!
以及我們在深度學習中使用文本摘要獲得的結果?了不起,因此,我在本文中,我們將逐步介紹構建 使用深度學習的文本摘要器 通過覆寫構建它所需的所有概念,然后,我們將在 Python 中實作我們的第一個文本摘要模型!
注意: 本文要求對一些深度學習概念有基本的了解,我建議瀏覽下面的文章,- [A Must-Read Introduction to Sequence Modelling (with use cases)](https://www.analyticsvidhya.com/blog/2018/04/sequence-modelling-an-introduction-with-practical-use-cases/?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python)
- [Must-Read Tutorial to Learn Sequence Modeling (deeplearning.ai Course #5)](https://www.analyticsvidhya.com/blog/2019/01/sequence-models-deeplearning/?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python)
- [Essentials of Deep Learning: Introduction to Long Short Term Memory](https://www.analyticsvidhya.com/blog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python)
目錄
- NLP中的文本摘要是什么?
- 序列到序列 (Seq2Seq) 建模介紹
- 了解編碼器 - 解碼器體系結構
- 編碼器局限性 - 解碼器體系結構
- 注意機制背后的直覺
- 理解問題說明書
- 使用 Keras 在 Python 中實作文本摘要
- 如何進一步提高模型的性能?
- 注意力機制是如何作業的?
1. NLP中的文本摘要是什么?
讓我們先了解什么是文本摘要,然后再看看它是如何作業的,這里有一個簡潔的定義來幫助我們開始:
“自動文本摘要是在保留關鍵資訊內容和總體意義的同時生成簡潔流暢的摘要的任務”
-文本總結技術: 簡要調查,2017
有大致兩種不同的方法用于文本總結:
- 提取概括
- 抽象概括
讓我們更詳細地看看這兩種型別,
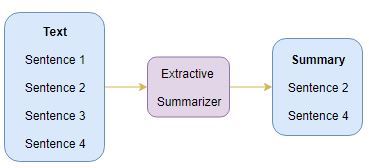
1.1 提取摘要
這個名字透露了這種方法的作用, 我們從原文中識別出重要的句子或短語,并且只從原文中提取那些, 那些提取的句子將是我們的總結,下圖說明了提取摘要:
我建議仔細閱讀下面的文章,使用TextRank演算法構建提取文本摘要器:
- 使用TextRank演算法的文本摘要介紹 (使用Python實作)
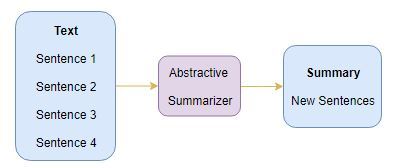
1.2 抽象摘要
這是一個非常有趣的方法,這里, 我們從原文生成新句子, 這與我們之前看到的只使用存在的句子的提取方法相反,通過抽象總結生成的句子可能不會出現在原文中:
你可能已經猜到了 -- 我們將在本文中使用深度學習來構建一個抽象的文本摘要器!在深入了解實作部分之前,讓我們首先了解構建文本摘要器模型所需的概念,
前方是激動人心的時刻!
2. 序列到序列 (Seq2Seq) 建模介紹
我們可以針對涉及順序資訊的任何問題構建Seq2Seq模型,這包括情感分類、神經機器翻譯和命名物體識別 -- 順序資訊的一些非常常見的應用,
在神經機器翻譯的情況下,輸入是一種語言的文本,輸出也是另一種語言的文本:

在命名物體識別中,輸入是單詞序列,輸出是輸入序列中每個單詞的標簽序列:
我們的目標是構建一個文本摘要器,其中輸入是一個長的單詞序列 (在文本正文中),輸出是一個短的摘要 (也是一個序列),所以, 我們可以將其建模為****多對多Seq2Seq問題, 以下是典型的Seq2Seq模型架構:
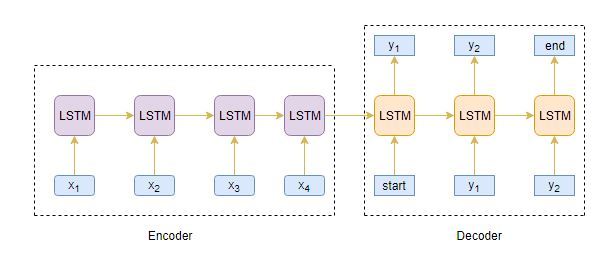
Seq2Seq 模型有兩個主要組成部分:
- 編碼器
- 解碼器
讓我們詳細了解這兩個,這些對于理解文本摘要在代碼下是如何作業是至關重要的,您也可以前往 本教程 更詳細地理解序列到序列建模,
3. 了解編碼器-解碼器體系結構
編碼器-解碼器體系結構主要用于解決輸入和輸出序列長度不同的序列到序列 (Seq2Seq) 問題,
讓我們從文本摘要的角度來理解這一點,輸入是一個長的單詞序列,輸出將是輸入序列的短版本,
通常,遞回神經網路 (RNNs) 的變體,即門控遞回神經網路 (GRU) 或長期短期記憶 (LSTM) 作為編碼器和解碼器組件是優選的,這是因為他們能夠通過克服梯度消失的問題來捕捉長期依賴性,
我們可以分兩個階段設定編碼器解碼器:
- 訓練階段
- 推理階段
讓我們通過LSTM模型的鏡頭來理解這些概念,
3.1 訓練階段
在訓練階段,我們將首先設定編碼器和解碼器,然后,我們將訓練模型以預測目標序列偏移一個時間步,讓我們詳細了解如何設定編碼器和解碼器,
編碼器
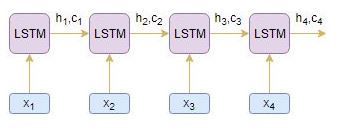
編碼器長期短期存盤模型 (LSTM) 讀取整個輸入序列,其中在每個時間步,一個字被輸入編碼器,然后,它在每個時間步處理資訊,并捕獲輸入序列中存在的背景關系資訊,
我把下面的圖表放在一起,說明了這個程序:
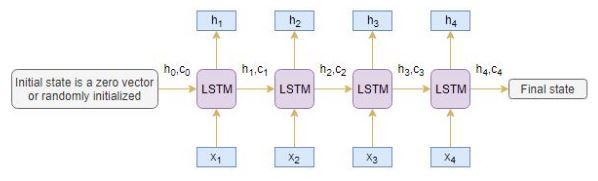
隱藏狀態 (h我) 和細胞狀態 (c我) 的最后一個時間步驟用于初始化解碼器,請記住,這是因為編碼器和解碼器是LSTM體系結構的兩組不同,
解碼器
解碼器也是一個LSTM網路,它逐字讀取整個目標序列,并通過一個時間步預測相同的序列偏移, 解碼器被訓練以預測給定前一個單詞的序列中的下一個單詞,
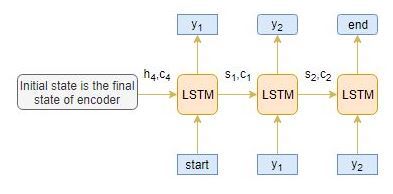
「開始」 和 「結束」是在將目標序列輸入解碼器之前添加到目標序列中的特殊標記,解碼測驗序列時目標序列未知,因此,我們開始通過將第一個單詞傳遞到解碼器來預測目標序列,該解碼器始終是 「開始」指令和 「**結束」**令牌表示句子的結尾,
到目前為止相當直觀,
3.2 預測階段
訓練后,在目標序列未知的新源序列上測驗模型,因此,我們需要設定推理架構來解碼測驗序列:
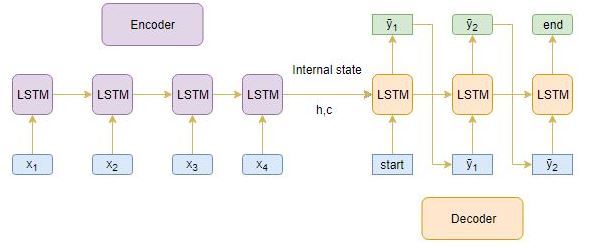
預測程序是如何作業的?
以下是解碼測驗序列的步驟:
- 對整個輸入序列進行編碼,并用編碼器的內部狀態初始化解碼器
- 通過 <**開始>**令牌作為解碼器的輸入
- 使用內部狀態運行解碼器一次
- 輸出將是下一個單詞的概率,將選擇具有最大概率的單詞
- 在下一個時間步中將采樣的字作為輸入傳遞給解碼器,并用當前時間步更新內部狀態
- 重復步驟3-5,直到我們生成 <**結束>**標記或命中目標序列的最大長度
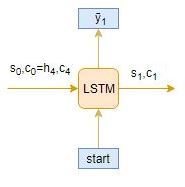
讓我們舉一個由 [x給出測驗序列的例子1,X2,X3,X4],對于這個測驗序列,推理程序是如何作業的?我想讓你在看下面我的想法之前先考慮一下,
- 將測驗序列編碼為內部狀態向量
- 觀察解碼器如何在每個時間步預測目標序列:
時間步長: t = 1
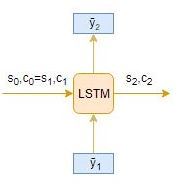
時間步長: t = 2
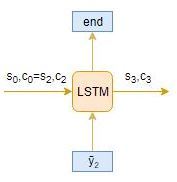
和,時間步長: t = 3
4.編碼器的局限性 - 解碼器體系結構
盡管這種編碼器-解碼器體系結構很有用,但它也有一定的局限性,
- 編碼器將整個輸入序列轉換為固定長度矢量,然后解碼器預測輸出序列,這僅適用于短序列 由于解碼器正在查看預測的整個輸入序列
- 長序列的問題來了, 編碼器很難將長序列記憶成固定長度的向量
“這種編碼器-解碼器方法的一個潛在問題是,神經網路需要能夠將源句子的所有必要資訊壓縮為固定長度的向量,這可能使神經網路難以處理長句,隨著輸入句子長度的增加,基本編碼器-解碼器的性能迅速下降,”
-通過共同學習對齊和翻譯的神經機器翻譯
那么我們如何克服長序列的問題呢?這是概念 注意機制 進入畫面,它旨在通過僅查看序列的幾個特定部分而不是整個序列來預測單詞,這真的和聽起來一樣棒!
5. 注意力機制背后的直覺
在時間步長生成一個單詞,我們需要對輸入序列中的每個單詞關注多少 T ?這是注意力機制概念背后的關鍵直覺,
讓我們考慮一個簡單的例子來了解注意力機制是如何作業的:
- 源序列: “你最喜歡哪項運動?
- 目標序列: “我喜歡板球”
第一個詞I 在目標序列中連接到第四個單詞 You 在源序列中,對嗎?同樣,第二個詞“**愛”**在目標序列中與第五個單詞相關聯 “喜歡” 在源序列中,
因此,我們可以增加導致目標序列的源序列的特定部分的重要性,而不是查看源序列中的所有單詞, 這是注意機制背后的基本思想,
根據參與的背景關系向量的匯出方式,有兩種不同類別的注意力機制:
- 全球關注
- 區域關注
讓我們簡單地談談這些課程,
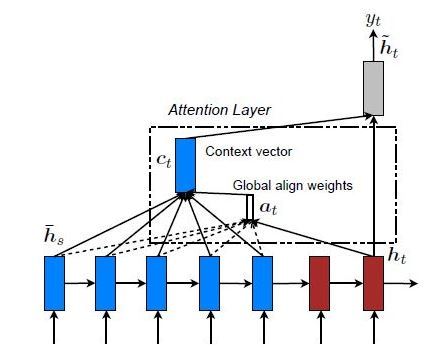
5.1 全域關注
在這里,注意力集中在所有的源位置上,換言之,編碼器的所有隱藏狀態都被考慮用于匯出被關注的背景關系向量:
5.2 區域關注
在這里,注意力只放在幾個源位置上, 僅考慮編碼器的一些隱藏狀態來匯出參與的背景關系向量:
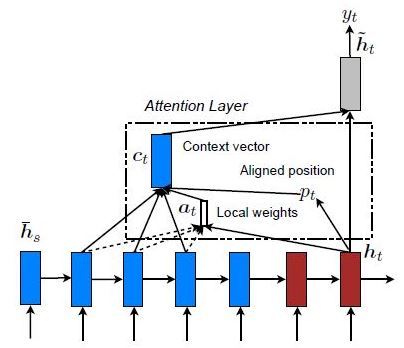
我們將在本文中使用全域注意力機制,
6. 理解問題陳述
顧客評論通常是長的和描述性的,可以想象,手動分析這些評論確實很耗時,這就是自然語言處理的輝煌之處,可以用來生成長時間評論的摘要,
我們將研究一個非常酷的資料集, 我們****這里的目標是使用我們在上面學到的基于抽象的方法為亞馬遜美食評論生成一個摘要,
您可以從以下位置下載資料集這里,
7. 使用 Keras 在 Python 中實作文本摘要
是時候啟動我們的Jupyter筆記本了!讓我們立即深入了解實作細節,
7.1 自定義注意力層
Keras不正式支持注意層,因此,我們可以實作我們自己的注意層或使用第三方實作,我們將在本文中選擇后一個選項, 您可以從以下位置下載注意力層 這里 并將其復制到另一個名為 注意py
讓我們將其匯入到我們的環境中:
7.2 匯入庫,讀取資料集
該資料集由亞馬遜美食評論組成,資料跨度超過10年,包括截至2012年10月的全部約500,000次審查,這些評論包括產品和用戶資訊、評分、純文本評論和摘要,它還包括來自所有其他亞馬遜類別的評論,
我們將對100,000篇評論進行抽樣,以減少我們模型的培訓時間,如果您的機器具有這種計算能力,請隨意使用整個資料集來訓練您的模型,
7.3 預處理,洗掉重復項和NA值
在進入模型構建部分之前,執行基本預處理步驟非常重要,使用混亂和未清理的文本資料是一個潛在的災難性舉動,所以在這一步中,我們將從文本中洗掉所有不需要的符號、字符等,這些不會影響我們問題的目標,
這是我們將用于擴展收縮的字典:
我們需要為預處理評論和生成摘要定義兩種不同的功能,因為文本和摘要中涉及的預處理步驟略有不同,
A) 文本清理
讓我們看一下資料集中的前10條評論,以了解文本預處理步驟:
資料 ['文本'][:10]
輸出 :
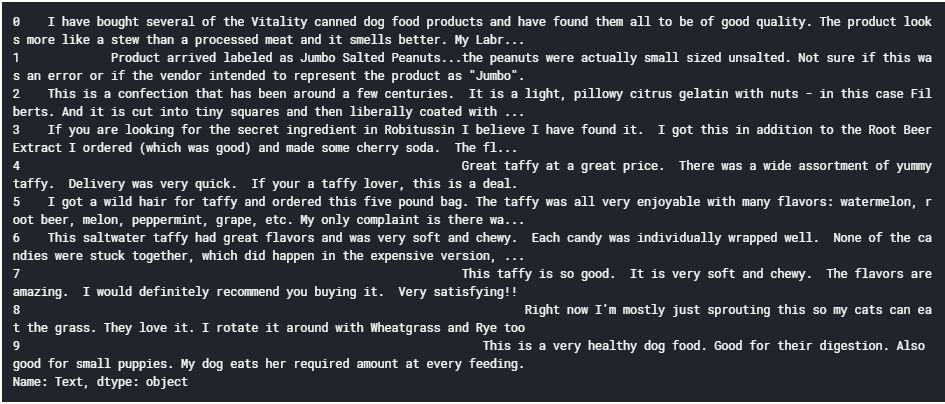
我們將為資料執行以下預處理任務:
- 將所有內容轉換為小寫
- 洗掉HTML標簽
- 收縮映射
- 洗掉 ()
- 洗掉括號內的所有文本 ()
- 消除標點符號和特殊字符
- 洗掉停止符
- 洗掉短詞
讓我們定義函式:
B) 整理清洗
現在,我們將查看評論的前10行,以了解 “摘要” 列的預處理步驟:
輸出 :
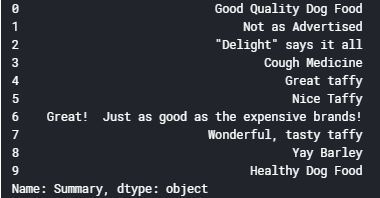
為此任務定義函式:
記得添加 啟動 和 結束 摘要開頭和結尾處的特殊令牌:
現在,讓我們看一下前5條評論及其摘要:
輸出 :
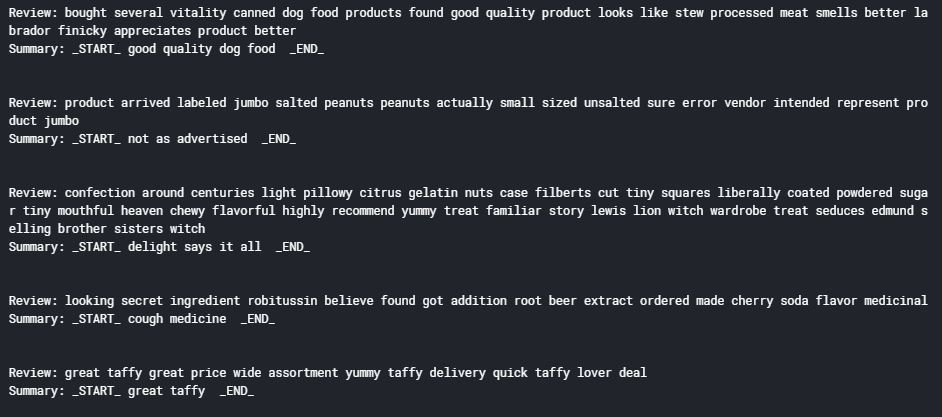
7.4 了解序列的分布
在這里,我們將分析評論的長度和摘要,以全面了解文本長度的分布, 這將幫助我們確定序列的最大長度:
輸出 :
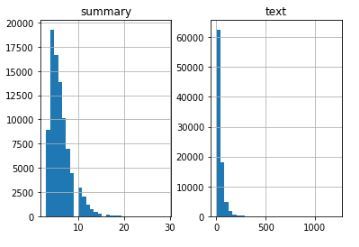
我們可以將評論的最大長度固定為80,因為這似乎是大多數評論的長度,同樣,我們可以將最大摘要長度設定為10:
我們越來越接近模型構建部分,在此之前,我們需要將資料集拆分為訓練和驗證集,我們將使用資料集的90% 作為訓練資料,并評估其余10% (保留集) 的性能:
7.5 準備標記器
標記器構建詞匯表并將單詞序列轉換為整數序列, 繼續為文本和摘要構建標記器:
A) 文本標記器
B) 摘要標記器
7.6 構建模型
我們終于進入了模型構建部分,但是在此之前,我們需要熟悉一些在構建模型之前需要的術語,
- **回傳序列 = True:**當回傳序列引數設定為 真正 ,LSTM為每個時間步產生隱藏狀態和單元格狀態
- **回傳狀態 = True:**當回傳狀態 = 真正 ,LSTM僅產生最后一個時間步的隱藏狀態和單元格狀態
- **初始狀態:**這用于初始化第一個時間步驟的LSTM的內部狀態
- **堆疊LSTM:**堆疊式LSTM有多層相互堆疊的LSTM,這導致序列的更好表示,我鼓勵您嘗試將LSTM的多層堆疊在一起 (這是學習此知識的好方法)
在這里,我們正在為編碼器構建一個3堆疊的LSTM:
輸出 :
我正在使用稀疏分類交叉熵 作為損失函式,因為它會將整數序列動態轉換為一個熱向量,這克服了任何記憶體問題,
還記得提前停車的概念嗎?它用于通過監視用戶指定的度量標準在正確的時間停止訓練神經網路,在這里,我正在監視驗證丟失 (val_loss),一旦驗證損失增加,我們的模型將停止訓練:
我們將在批處理大小為512的情況下訓練模型,并在保留集 (占我們資料集的10%) 上對其進行驗證:
7.7 了解診斷圖
現在,我們將繪制一些診斷圖,以了解模型隨時間的行為:
輸出 :
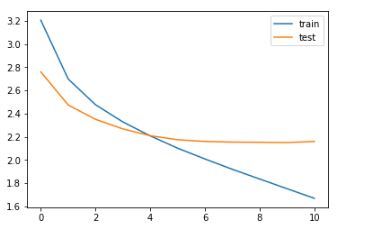
我們可以推斷,在紀元10之后,驗證損失略有增加,因此,我們將在該紀元之后停止訓練該模型,
接下來,讓我們構建字典,將索引轉換為目標詞匯和源詞匯的單詞:
推理
為編碼器和解碼器設定推理:
我們在下面定義一個函式,它是推理程序的實作 (我們在上節中討論過):
讓我們定義將整數序列轉換為單詞序列以進行摘要和評論的函式:
以下是模型生成的一些摘要:
這真的很酷,盡管實際的總結和我們模型生成的總結在文字方面不匹配,但它們都傳達了相同的含義,我們的模型能夠根據文本中的背景關系生成清晰的摘要,這就是我們如何在Python中使用深度學習概念執行文本摘要,
8. 我們如何進一步提高模型的性能?
你的學習不止于此!你可以做更多的事情來嘗試這個模型:
- 我建議你 增加訓練資料集的大小 并建立模型,深度學習模型的泛化能力隨著訓練資料集大小的增加而增強
- 嘗試 實作雙向LSTM 它能夠從兩個方向捕獲背景關系并產生更好的背景關系向量
- 使用 波束搜索策略 用于解碼測驗序列而不是使用貪婪方法 (argmax)
- 評價 您的模型的性能基于 藍色分數
- 實作指標生成器網路 和覆寫機制
9. 注意力機制是如何作業的?
現在,讓我們來談談注意機制的內部作業原理,正如我在文章開頭提到的,這是一個數學繁重的部分,所以把它看作是可選的學習,我仍然強烈建議通讀這篇文章,以真正理解注意力機制是如何作業的,
- 編碼器輸出隱藏狀態 ( H**J** ) 對于每個時間步J 在源序列中
- 同樣,解碼器輸出隱藏狀態 ( S**我** ) 對于每個時間步我 在目標序列中
- 我們計算一個被稱為對準分數****(EIj),在此基礎上,使用分數函式將源詞與目標詞對齊,校準 分數從源隱藏狀態計算得出 HJ 和目標隱藏狀態 S我 使用評分函式,這由:
** eij= score (si, hj )**
哪里 E**Ij** 表示目標時間步的對齊得分 我 和源時間步 J ,
根據所使用的評分功能的型別,有不同型別的注意機制,我在下面提到了一些流行的注意機制:

- 我們標準化校準分數使用softmax函式檢索注意權重 ( A**Ij**):
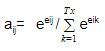
- 我們計算注意力權重的線性乘積之和 AIj 和編碼器的隱藏狀態 HJ 生產 參與的背景關系向量 ( C**我**):
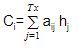
- 參與的背景關系向量以及解碼器在時間步的目標隱藏狀態 我 連接以產生一個有參與的隱藏向量 S我
S我= 串聯 ([s我; C我])
- 有人值守的隱藏矢量 S我 然后被送入致密層以產生 Y**我**
Y我= 密集 (秒我)
讓我們借助一個例子來理解上述注意機制步驟,將源序列視為 [x1,X2,X3,X4] 和目標序列是 [y1,Y2],
- 編碼器讀取整個源序列并輸出每個時間步的隱藏狀態,例如 H1,H2,H3,H4
- 解碼器讀取偏移一個時間步的整個目標序列,并輸出每個時間步的隱藏狀態,例如 S1,S2,S3
目標時間步長i = 1
- 校準分數 E1j 從源隱藏狀態計算 H我 和目標隱藏狀態 S1 使用評分功能:
E11= 分數1,H1)
E12= 分數1,H2)
E13= 分數1,H3)
E14= 分數1,H4)
- 標準化校準分數 E1j 使用softmax可產生注意力權重 A1j :
A11= Exp (e11)/((Exp (e11) + Exp (e12) + Exp (e13) + Exp (e14))
A12= Exp (e12)/(Exp (e11) + Exp (e12) + Exp (e13) + Exp (e14))
A13= Exp (e13)/(Exp (e11) + Exp (e12) + Exp (e13) + Exp (e14))
A14= Exp (e14)/(Exp (e11) + Exp (e12) + Exp (e13) + Exp (e14))
- 參與背景關系向量 C**1** 由編碼器隱藏狀態的乘積的線性和匯出 H**J** 和校準分數 A**1j**:
C1= H1* A11+ H2* A12+ H3* A13+ H4* A14
- 參與背景關系向量 C1 和目標隱藏狀態 S1 連接以產生一個有參與的隱藏向量 S1
S1= 串聯 ([s1; C1])
- 注意隱藏向量 S1 然后被送入致密層以產生 Y**1**
Y1= 密集 (秒1)
目標時間步長i = 2
- 校準分數 E2j 從源隱藏狀態計算 H我 和目標隱藏狀態 S2 使用給定的分數函式
E21= 分數2,H1)
E22= 分數2,H2)
E23= 分數2,H3)
E24= 分數2,H4)
- 標準化校準分數 E**2j** 使用softmax可產生注意力權重 A**2j**:
A21= Exp (e21)/(Exp (e21) + Exp (e22) + Exp (e23) + Exp (e24))
A22= Exp (e22)/(Exp (e21) + Exp (e22) + Exp (e23) + Exp (e24))
A23= Exp (e23)/(Exp (e21) + Exp (e22) + Exp (e23) + Exp (e24))
A24= Exp (e24)/(Exp (e21) + Exp (e22) + Exp (e23) + Exp (e24))
- 參與背景關系向量 C2 由編碼器隱藏狀態的乘積的線性和匯出 H我 對齊得分a 2j :
C2= H1* A21+ H2* A22+ H3* A23+ H4* A24
- 參與背景關系向量 C2 和目標隱藏狀態 S2 連接以產生一個有參與的隱藏向量 S2
S2= 串聯 ([s2; C2])
- 有人參與隱藏矢量 S2 然后被送入致密層以產生 Y2
Y2= 密集 (秒2)
我們可以對目標時間步驟i = 3執行類似的步驟來產生 Y**3.**
我知道這是大量的數學和理論,但是現在理解這一點將有助于你掌握注意力機制背后的基本思想,這催生了NLP的許多最新發展,現在你已經準備好留下自己的印記了!
示例代碼
找到整個筆記本 這里 ,
寫在最后
深呼吸 -- 我們在這篇文章中談到了很多地方,恭喜您使用深度學習構建了第一個文本摘要模型!我們已經了解了如何使用 Python 中的 Seq2Seq 建模來構建我們自己的文本摘要器,
如果您對本文有任何反饋或任何疑問/疑問,請在下面的評論部分分享,我會回復您,并確保您使用我們在此處構建的模型進行實驗,并與社區分享您的結果!
作者:設計稿智能生成代碼
鏈接:https://juejin.im/post/6891937843103727630
來源:掘金
著作權歸作者所有,商業轉載請聯系作者獲得授權,非商業轉載請注明出處,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/205065.html
標籤:其他
上一篇:Verilog小總結