前言
本文是對Java程式員面試中常見的微服務、網路編程、分布式存盤和分布式計算等必備知識點的總結,包括Spring 原理及應用、Spring Cloud原理及應用、Netty網路編程原理及應用、ZooKeeper原理及應用、Kafka原理及應用、Hadoop原理及應用、HBase原理及應用、Cassandra原理及應用、ElasticSearch原理及應用、Spark原理及應用、Flink原理及應用,希望讀者能通過閱讀本書對微服務、網路編程和分布式系統有更深入、系統和全面的理解,
面試官通常會在短短兩小時內對面試者的知識結構進行全面了解,面試者在回答問題時如果拖泥帶水且不能直擊問題的本質,則很難充分表現自己,最終影響面試結果,
針對這種情況,本文對Java分布式架構中常用的技術做了梳理和總結,在介紹知識點時重點介紹原理,同時輔以示例,
本文在講解知識點時不拖泥帶水,力求精簡,用115張原理圖和流程圖以非常直觀的方式對Java程式員面試時常被問及的分布式架構核心知識點進行介紹,

本文將從目錄、主要內容和專家熱評三部分內容組成,希望大家能夠仔細閱讀,掌握其中所有的技術知識點和思維方式,希望本文能夠得到大家的喜歡!!!
目錄

主要內容
為了方便大家的閱讀,本文總共分為11章的內容,各章具體內容如下:
第1章Spring原理及應用;Spring 是一個企業級J2EE應用開發一站式解決方案,其提供的功能貫穿了專案開發的表現層、業務層和持久化層,同時,Spring可以和其他應用框架無縫整合,大部分Java開發人員在專案中均使用到了Spring 技術,但是在使用程序中,有很多開發人員認為“程式run起來就ok 了”,容易忽略其原理,本章將詳細介紹常用的Spring核心技術背后的原理,
第2章Spring Cloud原理及應用;Spring Cloud為企業級分布式Web系統構建提供了一站式的解決方案,為了簡化分布式系統的開發流程和降低開發難度,Spring Cloud 以組件化的形式提供了配置管理、服務發現、斷路器、智能路由、負載均衡和訊息總線等模塊,應用程式只需要根據需求引入模塊,便可方便地實作對應的功能,

第3章Netty網路編程原理及應用;Netty 是一個高性能、異步事件驅動的NIO框架,它基于Java NIO提供的API實作,提供了對TCP ( Transmission Control Protocol,傳輸控制協議)、UDP ( User DatagramProtocol,用戶資料包協議)和檔案傳輸的支持,作為一個異步NIO框架,Netty 的所有I/O操作都是異步非阻塞的,通過Future-Listener機制,用戶可以方便地主動獲取或者通過通知機制獲取I/O操作結果,
第4章ZooKeeper原理及應用;ZooKeeper是一個分布式協調服務,其設計的初衷是為分布式軟體提供一致性服務,ZooKeeper提供了一個類似Linux檔案系統的樹形結構,ZooKeeper的每個節點既可以是目錄也可以是資料,同時,ZooKeeper提供了對每個節點的監控與通知機制,基于ZooKeeper的一致性服務,可以方便地實作分布式鎖、分布式選舉、服務發現和監控、配置中心等功能,
第5章Kafka原理及應用;Kafka是一種高吞吐、分布式、基于發布和訂閱模型的訊息系統,最初由LinkedIn公司開發,使用Scala撰寫,目前是Apache 的開源專案,Kafka用于離線和在線訊息的消費,Kafka將訊息資料按順序保存在磁盤上,并在集群內以副本的形式存盤以防止資料丟失,
Kafka依賴ZooKeeper進行集群的管理,Kafka 與Storm、Spark能夠非常友好地集成,用于實時流式計算,

第6章Hadoop原理及應用;Hadoop是一個大資料解決方案,提供了一套分布式系統基礎架構,核心內容包含HDFS ( Hadoop Distributed File System,分布式檔案系統)、MapReduce計算引擎和YARN ( Yet Another Resource Negotiator,另一種資源協調者)統一資源管理調度,
其中,HDFS分為NameNode和DataNode,NameNode負責保存元資料的基本資訊,DataNode負責具體資料的存盤,MapReduce分為JobTracker和TaskTracker,JobTracker負責任務的分發,TaskTracker負責具體任務的執行,
Hadoop集群是Master/Slave (M/S)架構,NameNode和JobTracker運行在Master節點上,DataNode和 TaskTracker運行在Slave節點上,
第7章HBase原理及應用;HBase是一個開源的分布式Key-Value資料庫,其主要作用是面向數十億級資料的實時人庫和快速隨機訪問,HBase底層存盤基于HDFS實作,集群的管理基于ZooKeeper實作,HBase良好的分布式架構設計為海量資料的快速存盤、隨機訪問提供了可能,基于資料副本機制和磁區機制可以輕松實作在線擴容、縮容和資料容災,是大資料領域中Key-Value資料結構存盤最常用的資料庫方案,

第8章Cassandra原理及應用;Cassandra是一套開源分布式NoSQL資料庫系統,它最初由Facebook開發,于2008年開源,Cassandra由于良好的可擴展性、高性能和PP去中心化的設計,迅速成為分布式存盤中十分流行的資料存盤方案,
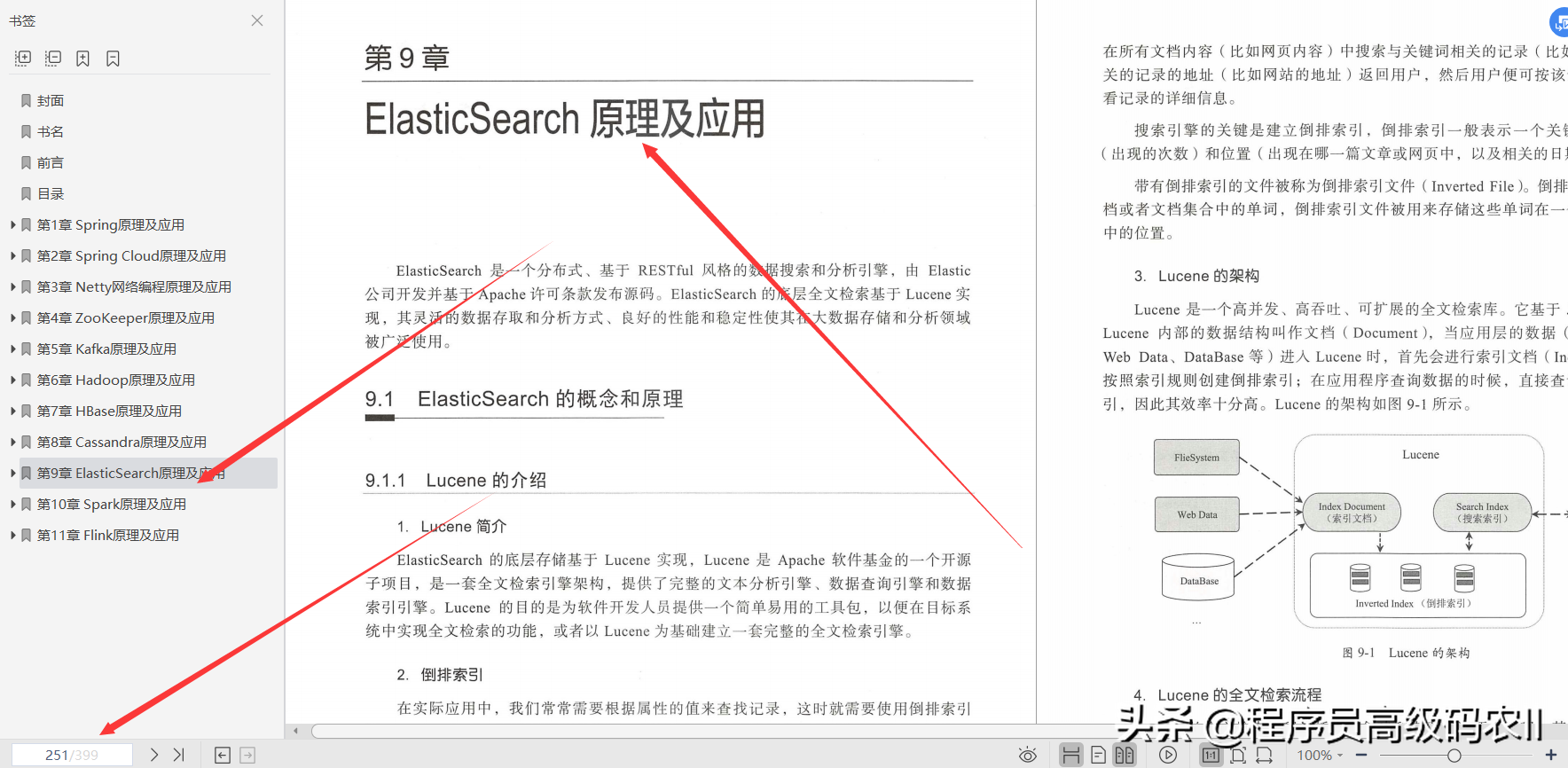
第9章ElasticSearch原理及應用;ElasticSearch是一個分布式、基于RESTful風格的資料搜索和分析引擎,由Elastic公司開發并基于Apache許可條款發布原始碼,ElasticSearch的底層全文檢索基于Lucene實作,其靈活的資料存取和分析方式、良好的性能和穩定性使其在大資料存盤和分析領域被廣泛使用,
第10章Spark原理及應用;Apache Spark是通用的分布式大資料計算引擎,Spark是UC Berkeley AMPLab(美國加州大學伯克利分校的AMP實驗室)開源的通用并行框架,Spark擁有HadoopMapReduce所具有的優點,但不同于Hadoop MapReduce的是,Hadoop每次經過Job執行的中間結果都存盤到HDFS等磁盤上,而Spark的Job中間輸出結果可以保存在記憶體中,而不再需要讀寫HDFS,因為記憶體的讀寫速度與磁盤的讀寫速度不在一個數量級上,所以Spark利用記憶體中的資料能更快速地完成資料的處理,
Spark啟用了彈性分布式資料集(Resilient Distributed Dataset,RDD),除了能夠提高互動式查詢效率,還可以優化迭代器的作業負載,由于彈性分布式資料集的存在,使得資料挖掘與機器學習等需要迭代的MapReduce的演算法更容易實作,
第11章Flink原理及應用;Flink是一個分布式計算引擎,主要用于有界資料流和無界資料流的有狀態的資料分析和處理,Flink擅長處理有界資料流和無界資料流,其精確的時間控制和狀態化使Flink能夠安全并快速地處理海量資料,
Flink 將資料抽象為有界資料流和無界資料流,
Flink 由Job Manager、Task Manager和客戶端組成,Job Manager是管理節點,負責集群任務的提交、分配和資源管理;Task Manager是具體執行任務的計算節點﹔客戶端用于作業的提交,

這份【java面試核心知識點核心篇】共有399頁,需要完整版的朋友,可以轉發此文關注小編,掃碼獲取!!!

專家對本文的熱評

Java程式員很大部分從事Web方向和大資料應用開發方向,對于后者來說,除了編程語言等基礎知識,了解大資料組件也是一個重要的部分,本文涵蓋了常用大資料組件的重要基礎知識,對于相關從業人員是很好的讀物,
本文主題雖然是Offer來了,但卻對Java分布式架構的常用技術做了非常詳細的梳理,并且結合了大量的原理圖和流程圖,讓讀者快速學習和了解這些常用技術,更以非常直觀的方式對知識體系做了總結,方便讀者在面試的時候有更全面的發揮,同時能夠在作業中得到運用,非常值得大家購買和閱讀,
微服務、網路編程、分布式系統等方面的知識,是每一個Java程式員都必須掌握的,
本文深入淺出,使得讀者們充分了解上述這些重要的知識點和底層邏輯,非常值得一讀,
希望大家通過本文的閱讀,能夠得到很大的提升,把自己的技術深度和廣度給提升上來,提高自身的價值,更好地適應社會的發展,更希望本文能夠幫助到廣大程式員!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/212942.html
標籤:其他